The Lunduke Journal@LundukeJournal
It looks like the Debian Linux project will soon have a new Leader focused on having fewer "(cis)male" contributors to Debian Linux.
Nominations are closed for the new Debian Project Leader... and the election period is underway.
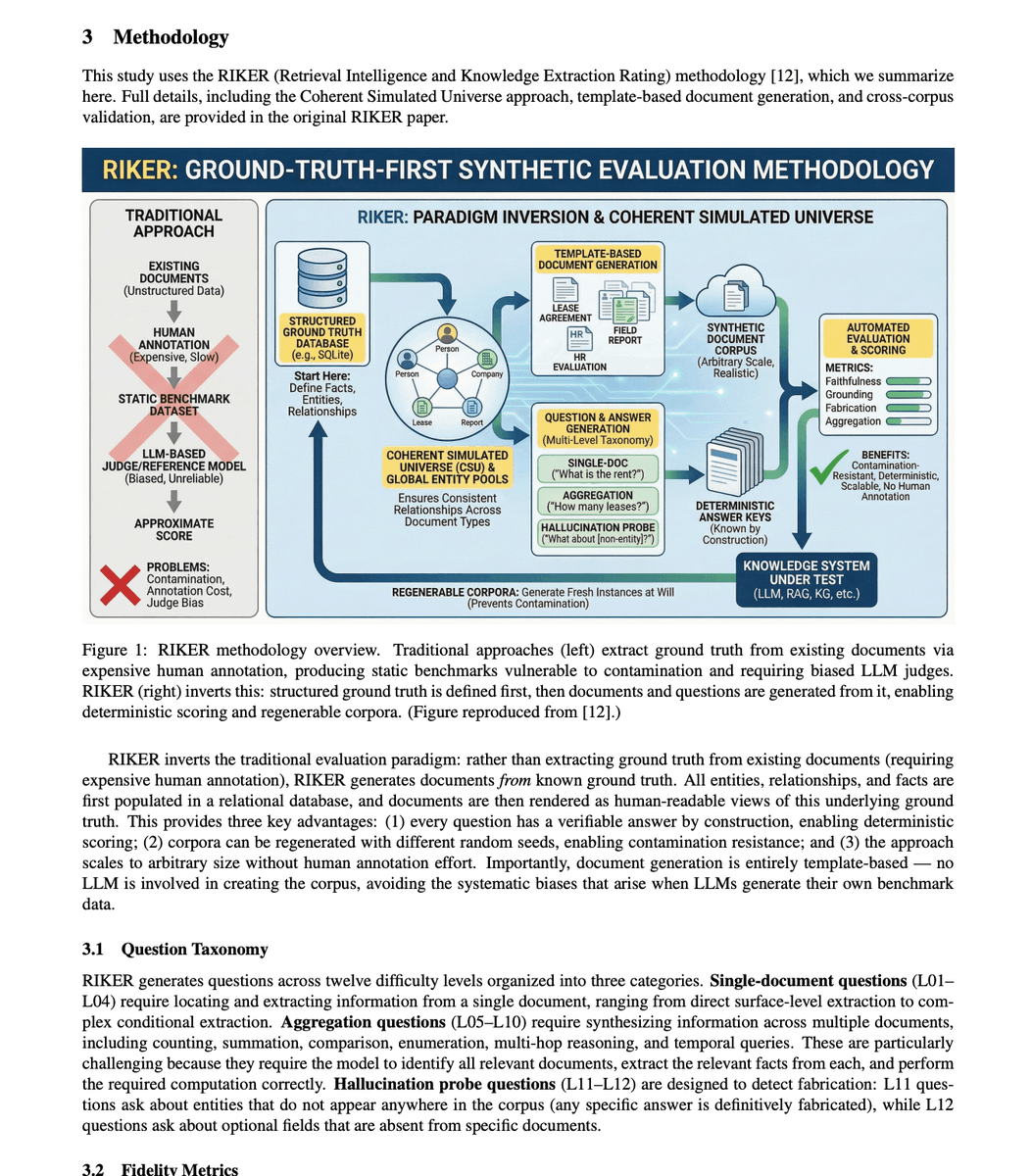
Voters have exactly 1 (one) candidate to choose from when they vote.
That's right. The Debian Project is giving their members only one option.
That person, Sruthi Chandran, describes herself as a "librarian turned Free Software enthusiast and Debian Developer from India".
She is focused on what she calls the "skewed gender ratios within the Free Software community", saying, "how many times did we have a non-(cis)male candidate for [Debian Project Leader]?"
Sruthi says that diversity should "come up for discussion in each and every aspect of the project," adding the goal is to have "more women (both cis and trans), trans men, and genderqueer people."
Voting officially begins on April 4th.
lists.debian.org/debian-devel-a…