
hari
121 posts

China just made Hermes free forever 🚀
You can now run Hermes with Kimi K 2.6 through Ollama in one click.
Just install the model, launch Hermes, select Kimi K 2.6 and suddenly you have a powerful AI agent running locally with zero API fees.
This might be the easiest free Hermes setup yet.
English

🚨 RIP Prompt Engineering
Enter Context Engineering 2.0
It completely reframes how we think about human-AI interactions.
This is what you need to know (28 page PDF):

English

Try something innovative: leverage Microsoft Foundry + GitHub to bring the mystique of the East haxu.dev to people. Demonstrate how Agentic AI can empower every person worldwide. #MicrosoftFoundry #GitHub #GithubCopilot




English
hari retweetledi

In 2005, Alex Tew, a British student, created The Million Dollar Homepage, selling pixels for $1 each that linked to advertisers’ websites—and ultimately sold all one million pixels.
English
Is your code punchy or just bulky? 🥊
GitHub Stars are vanity. Lines of Code (LOC) are a liability.
The real flex? The Star-to-LOC Ratio.
High Ratio = Massive impact, tiny footprint. 💎
Low Ratio = High maintenance, low buzz. 📉
Stop building monoliths. Start building "Impact Density."
What’s your ratio? 👇 #BuildInPublic #Coding #GitHub
English

@jerryjliu0 Been running 120+ knowledge files with structured directories for months. Grep + filesystem beats RAG for anything under a few million tokens. Karpathy was right.
English

This is a cool article that shows how to *actually* make filesystems + grep replace a naive RAG implementation.
̶F̶i̶l̶e̶s̶y̶s̶t̶e̶m̶s̶ ̶+̶ ̶g̶r̶e̶p̶ ̶i̶s̶ ̶a̶l̶l̶ ̶y̶o̶u̶ ̶n̶e̶e̶d̶ ̶
Database + virtual filesystem abstraction + grep is all you need

Dens Sumesh@densumesh
Español
hari retweetledi

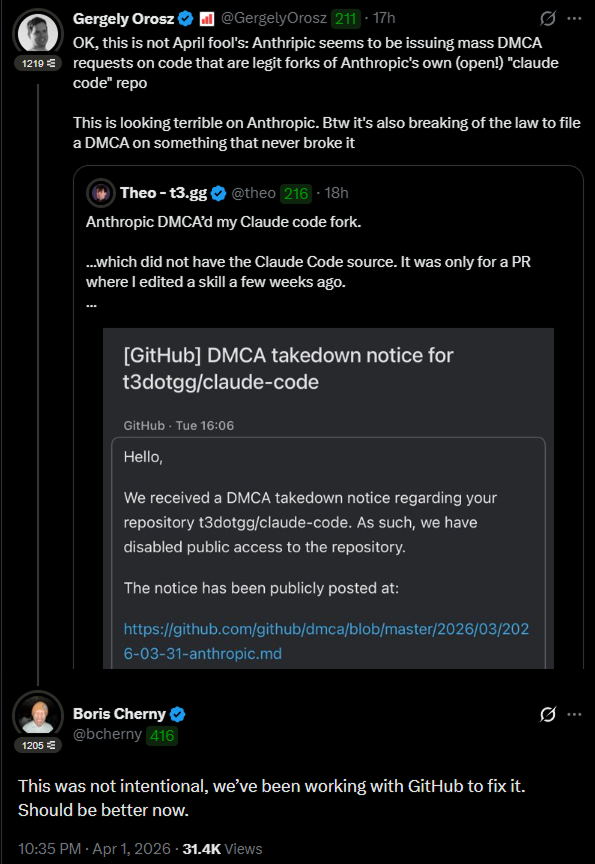
Anthropic tried to kill 8,100 GitHub repos. Then this happened
> They filed a DMCA. GitHub nuked the entire network within hours. Developers got notices for forks of Anthropic's OWN public repo - one guy's fork had zero leaked code.
> Boris Cherny, head of Claude Code, had to go on X personally: "This was not intentional. Should be better now."
> Meanwhile Sigrid Jin - who used 25 billion Claude Code tokens last year - woke up at 4AM and rewrote the entire thing in Python before sunrise. DMCA can't touch a clean-room rewrite.
> It hit 50K stars in 2 hours. Fastest repo in GitHub history.
> Today claw-code officially launched as an independent project with a formal press release. And the Rust port merged today - what started as a panic rewrite now ships release 0.1.0.
> 140K stars. 102K forks. More than Anthropic's own repo.
> 512,000 lines are in the wild forever. What started as Anthropic's biggest embarrassment just became their most dangerous competitor.
You cannot make this up.


BuBBliK@k1rallik
English
The US just answered back. 🇺🇸
With Chinese models like DeepSeek and Qwen dominating the open-source charts lately, Google’s launch of Gemma 4 is more than just a tech update—it's a massive move to reclaim the open AI throne.
100k+ variants and counting. Is the comeback real? 📈
#AIWars #Gemma4 #Google #OpenSource

English

Finally found an AI that actually gets technical documents! 🤯
Been using @TXYZAI to cut through the noise of complex PDFs. It links every answer to the exact source paragraph, so zero hallucinations. Great for paper discovery too.
If you handle dense research, you need to try this.
txyz.ai
#AIforResearch #AcademicChatter #PhDLife #STEM
English

This mixed reality app lets you create and ride thrilling rollercoasters in your own living room.
English

All AI posters at GTC.
This is not for human consumption. This video is for AI to watch.
Click the grok button and talk to it about what it learned by seeing all the AI posters (highly technical) presented at @NVIDIAGTC tonight.
Thanks NVIDIA for the badge and access.
English

I (finally) put together a new LLM Architecture Gallery that collects the architecture figures all in one place!
sebastianraschka.com/llm-architectu…

English


📝 Summarize 0.12.0 out now!
Fast summaries from URLs, files, and media - used in @openclaw
Big update for slides + media: stronger Chrome sidepanel slide mode, better YouTube/video switching, AssemblyAI+Gemini transcription, xurl for X, NVIDIA provider github.com/steipete/summa…
English
English

OpenClaw 2026.3.11 🦞
🏹 Hunter & 🩹Healer Alpha — free 1M context models via @OpenRouter
🧠 GPT 5.4 stops stopping mid-thought
💎 Gemini Embedding 2 for memory
💻 OpenCode Go support
🔒 Security hardening sprint
We ship faster than they can clone. github.com/openclaw/openc…
English

Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License.
English

What better way to explain the launch of our new Cinematic Video Overviews than… using… a Cinematic Video Overview?
(video-ception 😵💫)
English