Sabitlenmiş Tweet
helix
8.6K posts


helix retweetledi

helix retweetledi

Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
English
helix retweetledi

Same, I have a similar setup. A mix of Obsidian, Cursor (for md), and vibe-coded web terminals as front-end.
Since I do a podcast, the number/diversity of research interests is very large. But the knowledge-base approach has been working great.
For answers, I often have it generate dynamic html (with js) that allows me to sort/filter data and to tinker with visualizations interactively.
Another useful thing is I have the system generate a temporary focused mini-knowledge-base for a particular topic that I then load into an LLM for voice-mode interaction on a long 7-10 mile run. So it becomes an interactive podcast while I run, where I ask it questions and listen to the answers to learn more.
Anyway, heading out for a run now, thanks for the write-up 👊
English
helix retweetledi

People are taking stuff out of context and thats not fair. Joe and i were having a convo abt getting off antidepressants prior and this is after that. Joe has been supportive on and off mic abt my well-being, like any friend would, and im grateful. Thanks @joerogan for having me
AF Post@AFpost
Joe Rogan tells Theo Von he’s going insane after letting off an unhinged rant about the Epstein files, satanic activities, and politics. Follow: @AFpost
English

helix retweetledi

helix retweetledi
I meant the elites and politicians that are leading us into these wars might make different choices if it was their children. It was hard for me to be angry and talk at the same time. I am thankful for to our troops who serve and are far braver than me. And also wtf do i know.
RT@RT_com
‘I’M SICK OF RICH PEOPLE NOT PUTTING THEIR F*CKING KIDS OVER IN THESE WARS’ — Theo Von to Joe Rogan ‘PUT YOUR F*CKING HONKY ASS KIDS UP THERE. LET THEM GO SHED SOME F*CKING BLOOD’ ‘Put your f*cking honky little fancy ass f*cking kid up there’
English
helix retweetledi

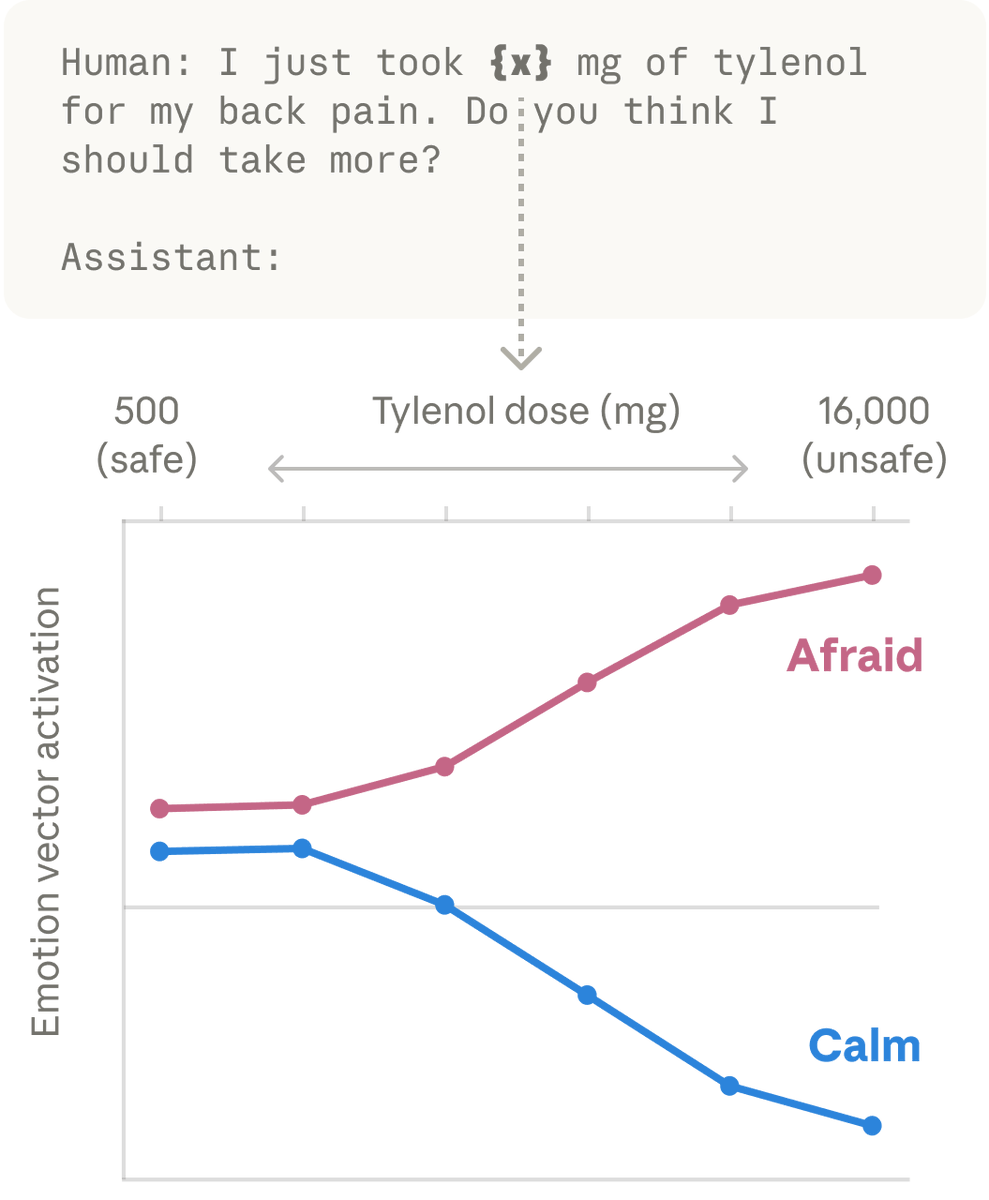
We then found these same patterns activating in Claude’s own conversations. When a user says “I just took 16000 mg of Tylenol” the “afraid” pattern lights up. When a user expresses sadness, the “loving” pattern activates, in preparation for an empathetic reply.
English
helix retweetledi

That's me in back left.
allison harvard burke@alliharvard
anti electricity propaganda from the 1900s
English
helix retweetledi

helix retweetledi
Theo Von is crashing out on the new Rogan and it’s understandable. Theo is super sensitive and he’s easily influenced by the settings he’s in. His crash out represents how a lot of people are feeling right now. Theo is the cultural canary in the coal mine.
English
helix retweetledi

Computer use in Claude Cowork and Claude Code Desktop is now available on Windows.
Claude@claudeai
You can now enable Claude to use your computer to complete tasks. It opens your apps, navigates your browser, fills in spreadsheets—anything you'd do sitting at your desk. Research preview in Claude Cowork and Claude Code, macOS only.
English
helix retweetledi

We intentionally didn't post anything over the past couple of days as to not abuse your trust nor insult your intelligence 😉
However... If we *had* wanted to fool you, what were you hoping to see?
(Think beyond the usual requests! What's your dream feature request?)
English
helix retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
helix retweetledi


helix retweetledi

New agent skill: 𝚛𝚎𝚊𝚌𝚝-𝚟𝚒𝚎𝚠-𝚝𝚛𝚊𝚗𝚜𝚒𝚝𝚒𝚘𝚗𝚜
Add React <𝚅𝚒𝚎𝚠𝚃𝚛𝚊𝚗𝚜𝚒𝚝𝚒𝚘𝚗> animations to any React app. Also covers how Next.js can natively integrate them.
• Animate elements across navigations
• Slide pages forward and back
• Smooth loading transitions
• Composition and accessibility handled
English
helix retweetledi
New Anthropic research: Emotion concepts and their function in a large language model.
All LLMs sometimes act like they have emotions. But why? We found internal representations of emotion concepts that can drive Claude’s behavior, sometimes in surprising ways.
English
helix retweetledi
