
English
Knik
228 posts

@G_melo_ding @hmph29759351 @hjc4869 Why there are still so many haters claiming 18A has worse efficiency, when low end PTH4+4 easily beats lnl in almost all the tests?




Some quick thoughts on Intel's EMIB-T packaging for the new 2H27 Google TPU (Humufish). Based on my industry checks: 【How to read EMIB-T's 90% yield?】 1. Given Intel's track record running EMIB in mass production, hitting 90% technology validation yield on EMIB-T (still under development) is a very positive but reasonable data point. 2. Intel benchmarks EMIB production/assembly yield against FCBGA. Industry FCBGA yield today is generally above 98%. 3. On yield, getting from 90% to 98% is harder than getting from project kickoff to 90%. And technology validation yield ≠ final production yield, especially with some Humufish specs still unfinalized. So long-term, I'm positive on Intel's advanced packaging story. Near to mid-term, I'm staying cautious on how they get there. 【From 90% to 98%. Looks like just a few points. Does Google care? Absolutely】 1. Google recently asked TSMC how much it could save by placing wafer orders for Humufish's main compute die (designed in-house by Google) directly, rather than routing them through MediaTek. 2. Google and MediaTek have run a semi-COT model since day one (8t). MediaTek's mark-up sits mostly on the parts it designs itself, so whether Google places the wafer orders for main compute die directly isn't a key swing factor for MediaTek's earnings trajectory. 3. But Google even probing whether it can squeeze out the pass-through mark-up on wafer orders tells you something: Google has shifted from easygoing buyer to hard-nosed on cost. The reason is simple: to take on Nvidia head-on, cost is Google's edge, which makes EMIB-T production yield Google's problem to solve. For context, TSMC's yield target on 5.5-reticle CoWoS in 2026 also starts at 98%. 【TSMC's position】 1. My understanding is TSMC is still working out how much advanced-node capacity to allocate to Humufish in 2H27, for two reasons: (1) it still wants the back-end packaging orders, though looks unlikely for now, and that's by design on Google's part; and (2) it's still gauging actual back-end output from EMIB-T, to avoid misallocating scarce advanced-node capacity. 2. Humufish's effective back-end output hinges on both EMIB-T and substrates, and both need to be tracked together. 3. On the Humufish semi-COT model, TSMC also prefers MediaTek to place the wafer orders for the main compute die. Beyond the close working relationship, the key point is MediaTek is TSMC's third-largest advanced-node customer in 2025. If TPU orders shift, MediaTek's scale makes it a natural buffer for TSMC to rebalance its wafer allocation mix.




#Intel Thanks for referencing our research. We believe the company’s front end 18A yield is also doing well, which is consistent with mgmt’s comments. As said in our earlier note, we expect the company to have started trial/testing for external customers based on 18A for a customer’s 2023’s chip which was on N3B.

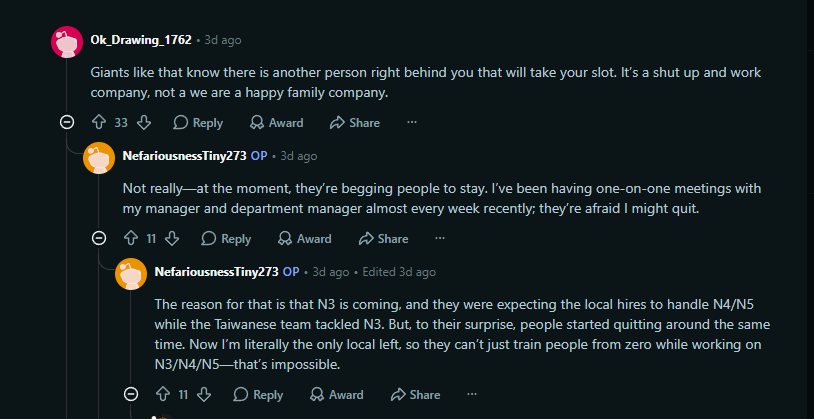
Anyone that works in Fabs or knows someone who works there knows that $TSM work culture is not healthy. Which really means talent would rather be somewhere else if that somewhere else provides them a good stable opportunity…..Queue Intel! A change is happening gradually and I bet many TSM talent will soon make the move to $INTC reddit.com/r/Semiconducto…


Northland Downgrades $AMD to Market Perform, PT $260 Analyst comments: "We initiated coverage of AMD 11 years ago with an Outperform rating, and people thought we were clueless. At the time, AMD was catching up to Intel, and Intel was falling behind TSMC. Now Intel is catching up to AMD, and TSMC is partnering with NVDA in AI infrastructure and PCs. We think this limits AMD’s gross margin expansion, and R&D spending will likely remain elevated. While AMD is a phenomenal company, the CY27 consensus is likely too high. Downgrading to Market Perform. We expect AMD to beat and raise estimates when it reports next week, but the results will likely not be as robust as Intel's. While AMD will benefit from price increases, we believe AMD needs to continue spending heavily on R&D to catch up with NVDA. AMD’s non-GAAP gross margin is currently in the mid-50% range, whereas INTC is high 30% to low 40%. Intel is becoming more competitive, and while INTC likely has a higher cost structure, AMD’s price premium relative to Intel’s is likely to decline. AMD is a fabless company and dependent on TSMC. NVDA is TSMC’s largest customer and is likely to receive favorable allocation amid very tight supply. Moreover, NVDA uses the supply chain as a competitive weapon, buying up capacity ahead of its competitors and constraining their growth. Our conclusion is that AMD results and outlook are going to be good, just not as good as INTC's last week. We believe the CY27 consensus needs to come down, as we expect AI infrastructure spending to decline in CY27. We believe that capex/cash flow of the hyperscalers is maxed out, and as OpenAI and Anthropic go public this year, they will demonstrate greater financial discipline. They are already moving away from unlimited free usage toward strict usage caps, token-volume-based pricing, and higher-tier subscriptions. We think this slows AI demand growth. At the same time, construction delays are affecting data center facilities." Analyst: Gus Richard



A brief look at how TSMC's Top 8 customers by % revenue has changed throughout the years from 2018 to 2027 👀 Apple at its peak commanded 27% share in 2021, but is now 19% and will decline further to 16% in 2027. Meanwhile, Nvidia has grown from 7% in 2018 to TSMC's biggest customer and will continue to be so in 2027 at 25%!!! AMD were once minnows at 4% but have now grown steadily to 10%!!! What is the moral of the story? stick with TSMC and they will make you a ton of money in semiconductors!!!! Republic of China (Taiwan) is the future!!! 🇹🇼💪💪💪 It is VERY WELL MADE in TAIWAN 🇹🇼😉 $NVDA $AAPL $AMD $AVGO $INTC $QCOM $MRVL #AI $TSM

