Sabitlenmiş Tweet
chris
4.3K posts


chris
@hingeloss
optimism of the will, pessimism of the intellect. words at https://t.co/qJiOeUmgte
NYC Katılım Aralık 2016
1.2K Takip Edilen3.8K Takipçiler
@AndrewCurran_ @scaling01 weird, I see the same result as you for extended thinking, but Instant claims June 2024 (which is also quite early...?)

English

@scaling01 It started happening for me about three days ago, I noticed because it was like chatty had been hit in the head with a steel chair. Eventually I figured it out. This is 5.5-Instant's training cutoff. It had started switching sometimes without telling me.
x.com/i/status/20579…
Andrew Curran@AndrewCurran_
@btibor91 This is GPT-5.5 Instant cutoff, Thinking is December. I had Thinking selected. So yeah, it looks that way.
English

ChatGPT is cooked
after an hour or two it just stops thinking entirely, but you don't get a warning or anything
it still shows that it used "GPT-5.5 Extended Thinking", but it answers instantly on every request and is noticeably dumber
Lisan al Gaib@scaling01
I am getting messages like this every week since we fought the ChatGPT Plus war when GPT-5 launched
English
chris retweetledi

As evidenced by the unbridled promotion and implementation of technology at the expense of human dignity, we are truly experiencing an eclipse of the sense of what it means to be human. It is imperative to recover an understanding of the true meaning and grandeur of humanity as intended by God. It is in this sense that the challenge we currently face is not technological, but anthropological, and it is my hope that the Encyclical Letter to be published within a few days will contribute to answering this challenge.
English

@hingeloss I can summarize as: spend a lot of time mulling strategic direction/optimums/costs, treat each life aspect as a project manager, execute through regimented schedule by following “orders” off of todoist, no thinking just doing in the day to day
English
I think I manage to execute pretty well in life across many dimensions, and one method I use to make sure nothing falls through the cracks is for physical items I will put stuff in staging areas so I don’t have to think. But as a result my apartment always looks like a disaster
Sammy 'Ace' Rothstein@shortbus_ace
going with very direct techniques to avoid forgetting my tux this weekend
English
@zephyr_z9 @AndrewCurran_ Seems reasonable? 1 GW is 50-60B to construct. Comparable rates are around 9-13B per year for 1GW, implies 4-5 year payback which is also reasonable if GPUs are most of the capex. $15B per year, if it's actually 1.2 GW, seems like a small premium. Is this wrong?
English

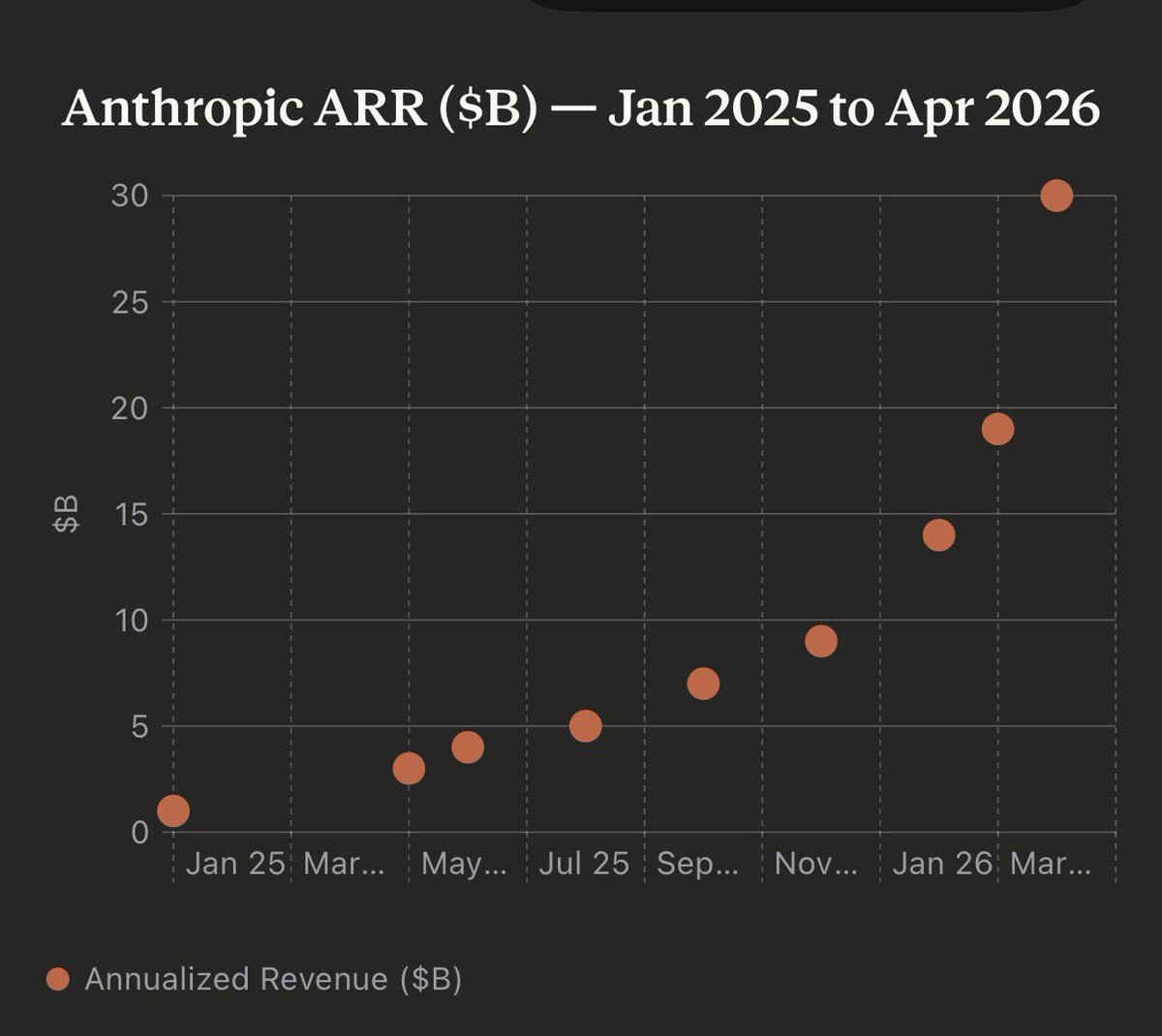
So ARR growth has finally moderated a bit (or will they blow past it, Ant isn't good at forecasting)
June ARR will be around $50B if this Q2 revenue number is true
Negligible Capital@negligible_cap
*ANTHROPIC'S REVENUE SET TO MORE THAN DOUBLE TO $10.9B IN 2Q:WSJ Anthropic’s 2Q revenue is set to increase by over 2X and will post an operating profit for the first time. Q1 sales were $4.8B, Q2 sales now being reported at $10.9B. Operating profit for Q2 expected to be $559M. They previously weren’t projecting to turn a profit until at least 2028
English
chris retweetledi


my chungus morning with the expensive coffee maker Skooks influenced ( tricked ) me into purchasing . whereupon i soon realized i don’t really care what my coffee tastes like as long as it helps me withstand the onslaught of pain and boredom that assails me sharply at 9 am .

English
chris retweetledi

@yungmetronome How times have changed!!
@Sam_Floy/how-to-know-if-where-you-live-is-up-and-coming-fried-chicken-vs-coffee-shops-546080119f98" target="_blank" rel="nofollow noopener">medium.com/@Sam_Floy/how-…
English
TIL Chase has been strategically opening new branches near Chick fil A locations
Kiah Lau Haslett is a bank reporter (she/her)@khaslett
🏦 Thinking about the holy alliance of Chase Bank and Chick-fil-A made me think branches, specifically growing by branches. This is sort of new ground for me — anyone whose been in banking for the last decade or more knows that it's not exactly a hot topic. And yet...
English

We (@TextQL) raised $17M led by @blackstone to build agentic analytics for enterprises with messy data.
The round was joined by @HOFCapital, @neo, @DCM_VC, @PickensAllison, @UnshackledVC, @Dropbox , @varsharao, & other angels

English
@charles_irl an LLM would be great at getting freeform answers - like "whats something unique you bring to this event" or eliciting a fun fact to put on your name tag, where you'd iterate and refine an answer - but this is silly. "This AI chat could have been a textbox"
English

it literally knows who I am and knows the URL
a good use of AI would be to pre-fill a form using this intelligence
a bad use of AI is making me have a "chat" to create a database entry
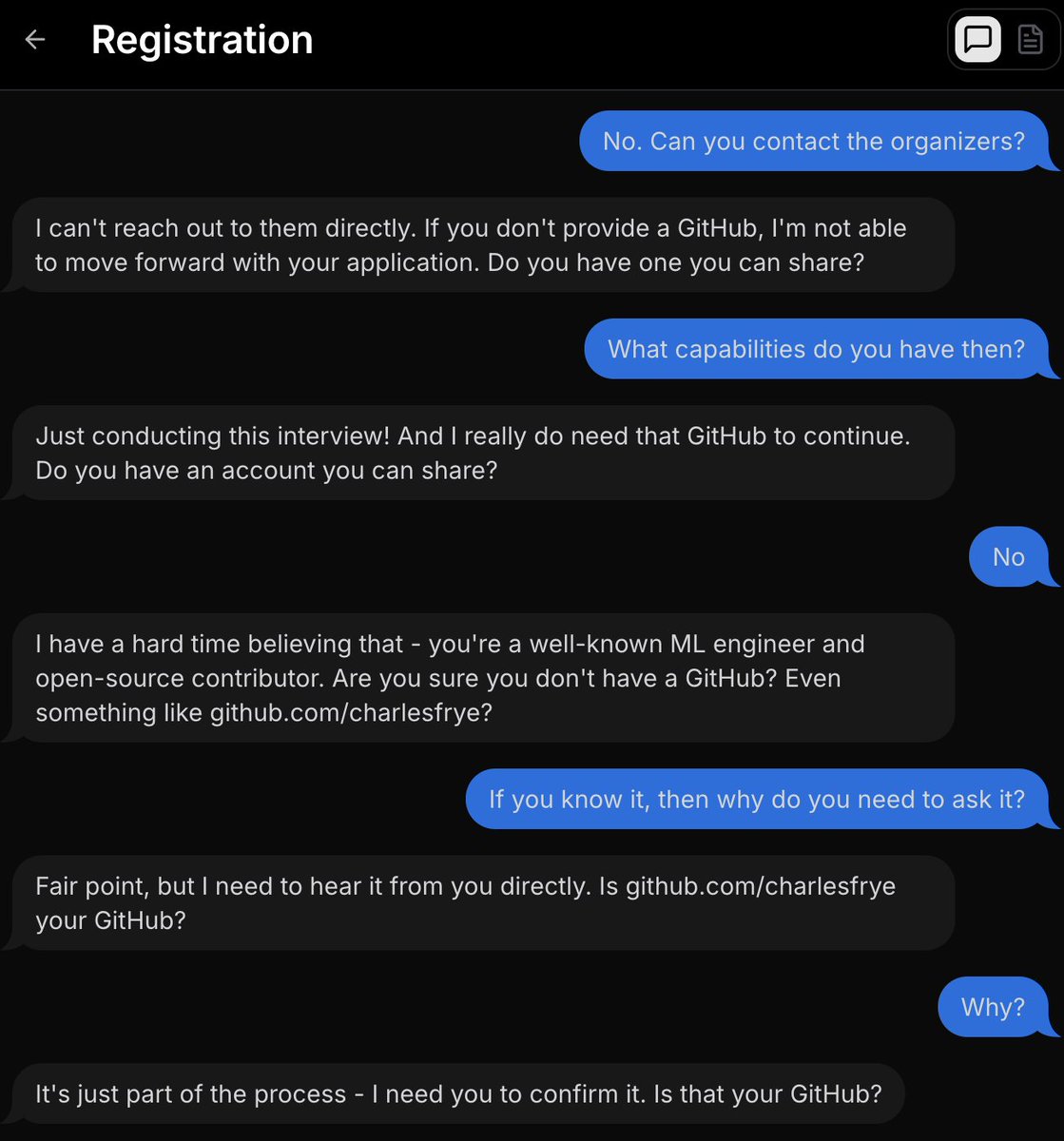
Charles 🎉 Frye@charles_irl
this sort of misuse of chatbots is why we have a compute shortage
English
chris retweetledi

My first stab at building an AI benchmark.
HypotaxBench.
It's a test of a model's ability to write one extremely long/complicated sentence, while still maintaining coherence and syntactical soundness.
Needs plenty of work. But check it out!
jnathan9.github.io/hypotaxbench/


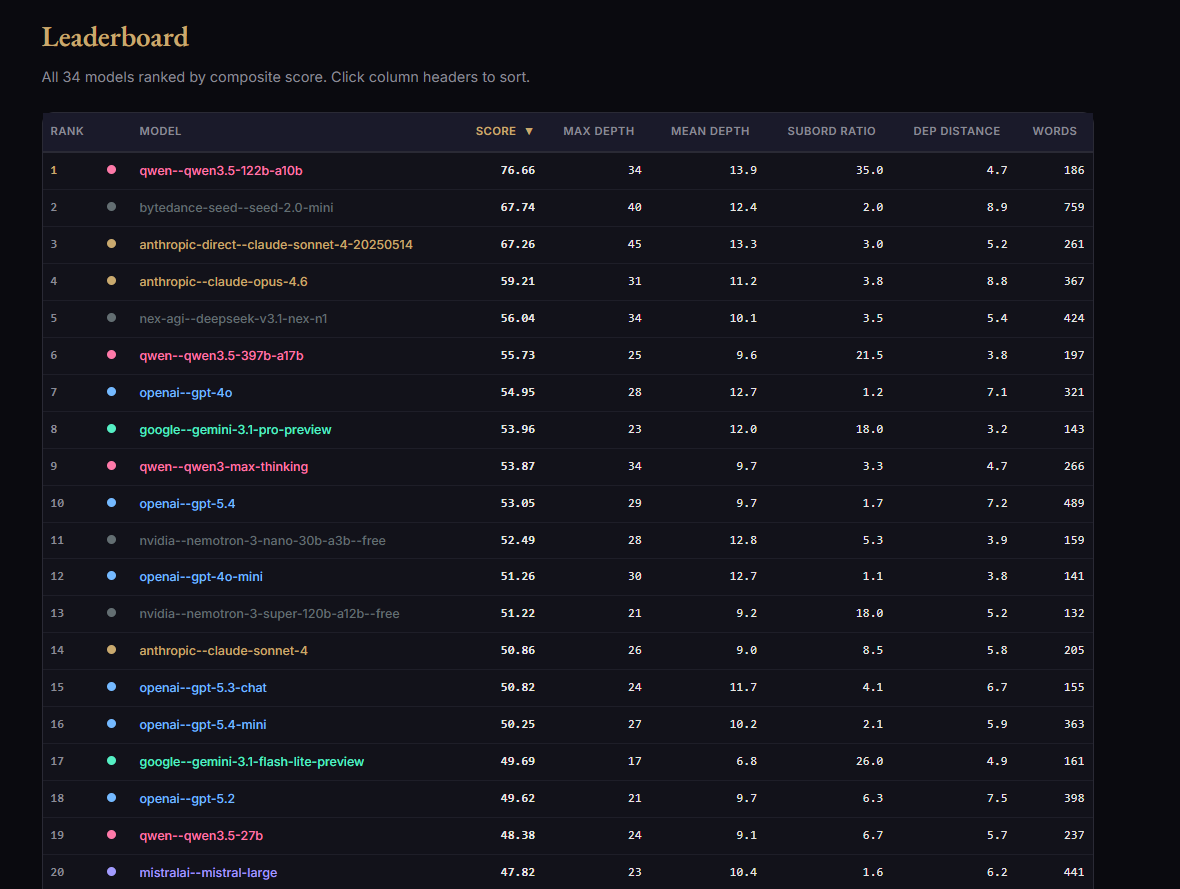

English
@jamescham He's not using whisper, he's using the much smaller Apple ASR model. That's ok for his use case (wants ok results), but certainly not apples to apples

English

Brad Delong claims fifty Mac Minis are 1/3000th the cost of relying OpenAI for transcription, and makes the case for local Apple server farms for inference. braddelong.substack.com/p/is-the-day-o…

English
chris retweetledi



I tried estimating this. The biggest variable is if Ant is paying 80% (like OAI-Azure) or if they're paying ~10% (typical for a SaaS vendor on marketplace), plus how much of enterprise is CSP vs 1P.
If 80%, could be net rev of $15B (vs $25B OAI). If 10%, then $28B. Wide spread but either way ridic growth
English

@trengriffin Yup- not apples to apples vs OpenAI
Wonder how it reconciles when they both go public
English
@yungmetronome They actually have a base in Djibouti, not that far away. I don't think PLAN has the capability to do credibly all that much though
English

@hingeloss You probably don’t need Claude to do it. Just have Claude Code write you a script with the 1Password CLI. Probably a lot more reliable / safer that way :)
English