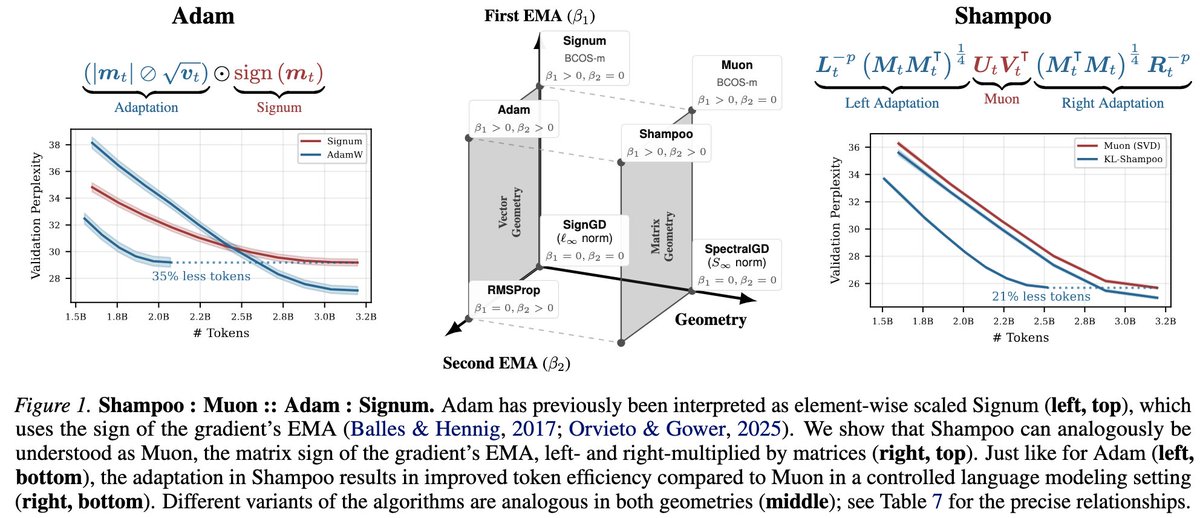
10/10 Both our paper (arxiv.org/abs/2512.17131) and code (github.com/facebookresear…) are available online. All the credit belongs to my awesome collaborators and teammates across MSL Kernels & Optimizations and FAIR: @paramsraman, @aaron_defazio, @konstmisch, and Lin Xiao.
English