
Wenjun Hou
20 posts

Wenjun Hou
@houwenjun060
🪫Researcher @ HKU Shanghai X-Lab | Phd @HongKongPolyU ⚡Building Agentic System
Shanghai, China Katılım Nisan 2022
388 Takip Edilen54 Takipçiler



🤔Hold on, I can answer better.
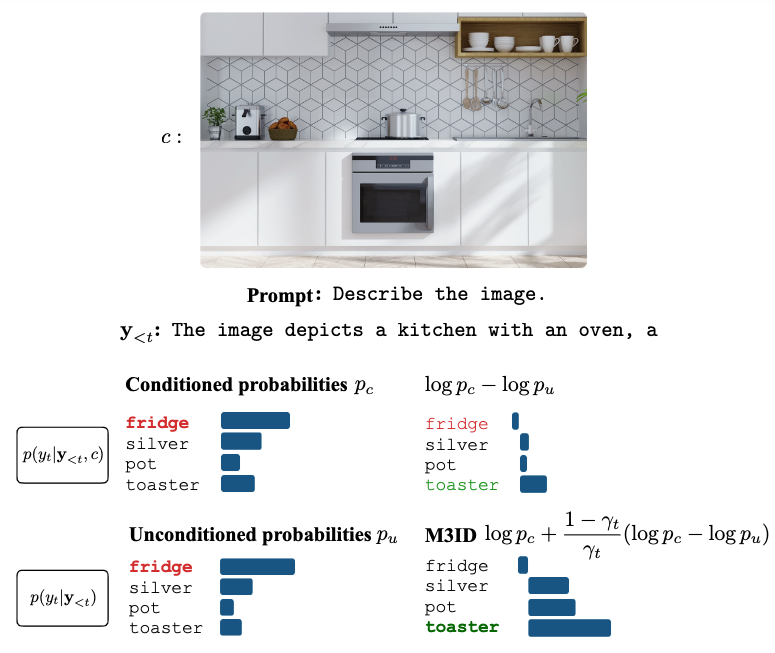
🔗New preprint on LLM multi-turn performance drop and recovery [arxiv.org/pdf/2604.04325]. 💡We identify a hidden tension in multi-turn reasoning: hold vs. lure.
⌛️Models can hold their intent to answer until sufficient evidence is observed, avoiding premature errors. ☔️But this ability is fragile—salient information can lure models to answer.
⬇️Even with the same information, performance drops significantly when moving from single-turn to multi-turn reasoning.
❓We ask: is this due to an overly strong intent to answer early?
🧑⚕️This is especially critical in medical diagnosis, a high-stakes setting with low tolerance for error, where a wrong answer at any turn can have serious consequences.
🎯To study this, we introduce MINT (Medical Incremental N-Turn Benchmark). MINT is:
✔ Information-preserving: decomposed cases can be concatenated to recover original single-turn performance, isolating the effect of interaction
✔ High-fidelity: clinically structured evidence (e.g., history, labs) with controlled turn granularity
💡Our key findings:
🏃1. Strong early-answer intent:
Over 55% of answers are given within the first 2 turns, leading to a 20–50% accuracy drop from single-turn to multi-turn.
⏰2. Holding unlocks self-correction:
When models are instructed to WAIT, the performance drop is greatly reduced. Incorrect→correct revisions occur up to 10.6× more often than the reverse, revealing a latent self-correction ability suppressed by early commitment.
🦴3. Strong lures override control:
Clinically salient signals (e.g., lab results) trigger premature answers—even when models are explicitly told to wait.
👇4. Actionable implications:
• Deferring the diagnostic question improves first-answer accuracy by up to 62.6%
• Delaying salient evidence prevents up to 23.3% catastrophic accuracy drop.
Thanks to all our coauthors for their amazing support! @ Jinrui Fang @ Runhan Chen @ Xu Yang @ Jian Yu @ Jiawei Xu @ Ashwin Vinod @WenqiShi0106 @TianlongChen4 @hengjinlp @ Chengxiang Zhai @TIMANUIUC @ying000




English
Wenjun Hou retweetledi

With @Grok, we keep the honest versions and kill the bad transformers (I believe they are called “Decepticons”)
I,Hypocrite@lporiginalg
This is fine.
English
Wenjun Hou retweetledi
🔍New findings of knowledge overshadowing! Why do LLMs hallucinate over all true training data? 🤔Can we predict hallucinations even before model training or inference?
🚀Check out our new preprint: [arxiv.org/pdf/2502.16143] The Law of Knowledge Overshadowing: Towards Understanding, Predicting, and Preventing LLM Hallucination.
💥We unveil the log-linear law of knowledge overshadowing: hallucination rate increases linearly with the logarithmic scale of relative knowledge popularity, relative knowledge length, and model sizes!
💥We are enabled to foresee hallucinations even before model training or inference by our unveiled law!
🧪Built on overshadowing effect, we propose a new decoding strategy CoDA to emphasize overshadowed knowledge while downweight dominant knowledge bias, significantly enhancing model factuality!
✨Our findings deepen understandings of the underlying mechanisms of hallucinations, opening exciting possibilities towards more predictable and controllable language models.
❤️Big thanks to the amazing team @ZoeyLi20 @qiancheng1231 @JiatengLiu @PengfeiYu @Glaciohound @May_F1_ for the inspiring collaborations!
❤️A huge appreciation for my mentors Prof. KathleenMckeown, Prof. ChengxiangZhai, Prof. @ManlingLi_ , and Prof. @hengjinlp for their amazing support and suggestions!




English
Wenjun Hou retweetledi

🚀 Accepted by ICLR’25!
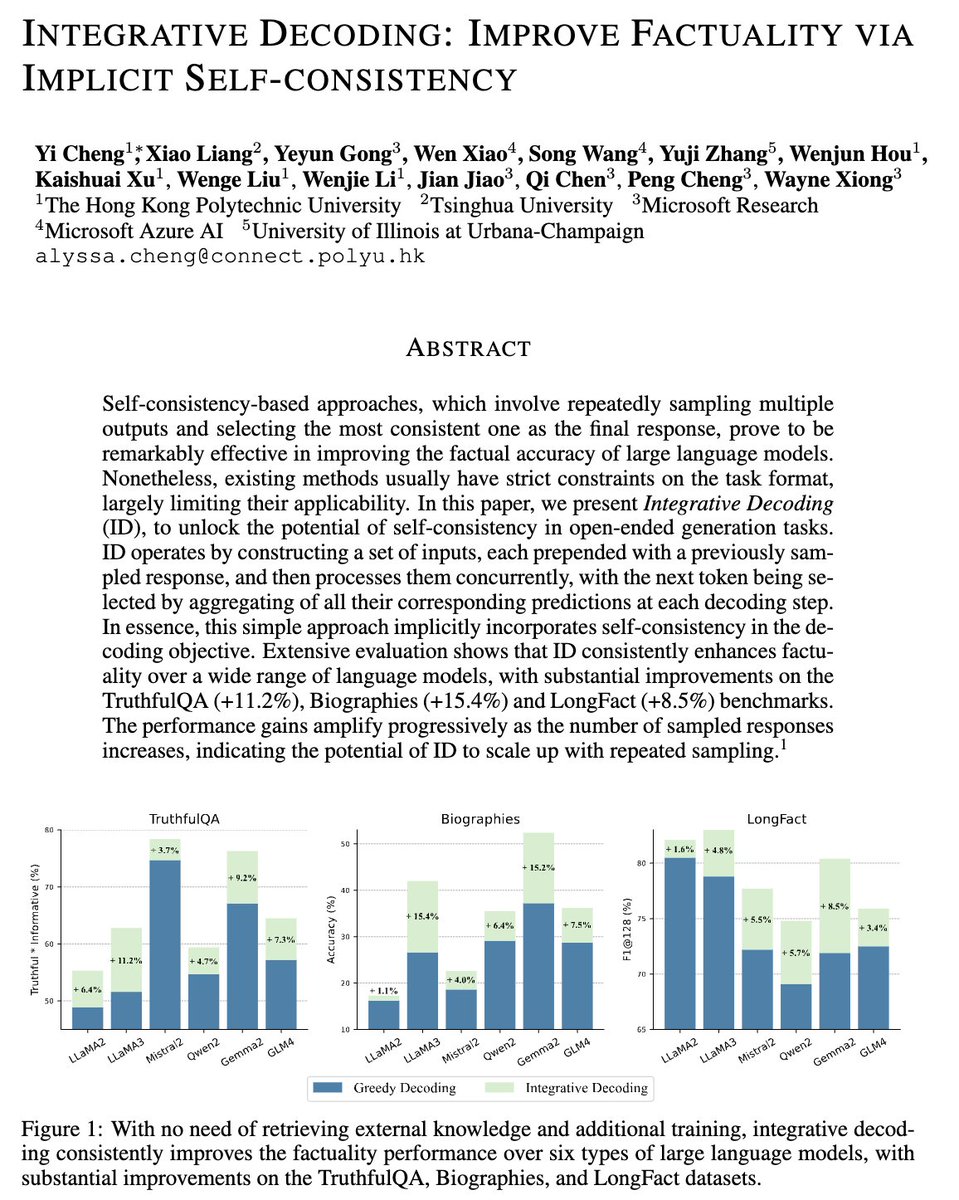
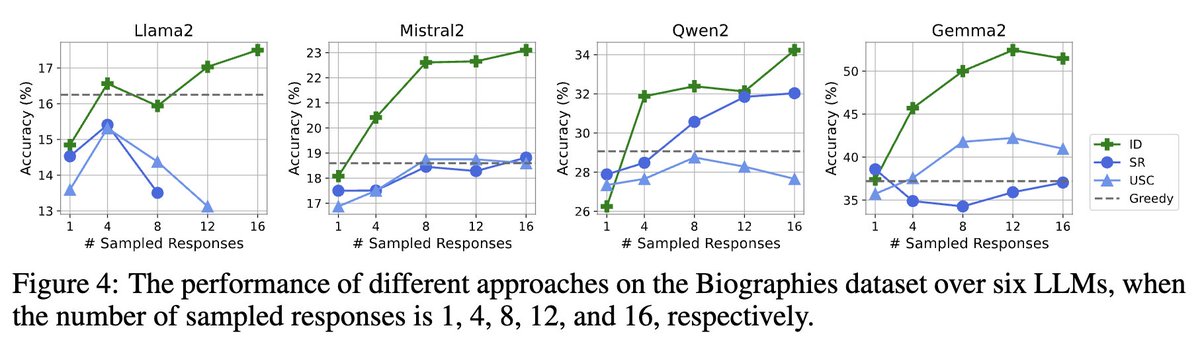
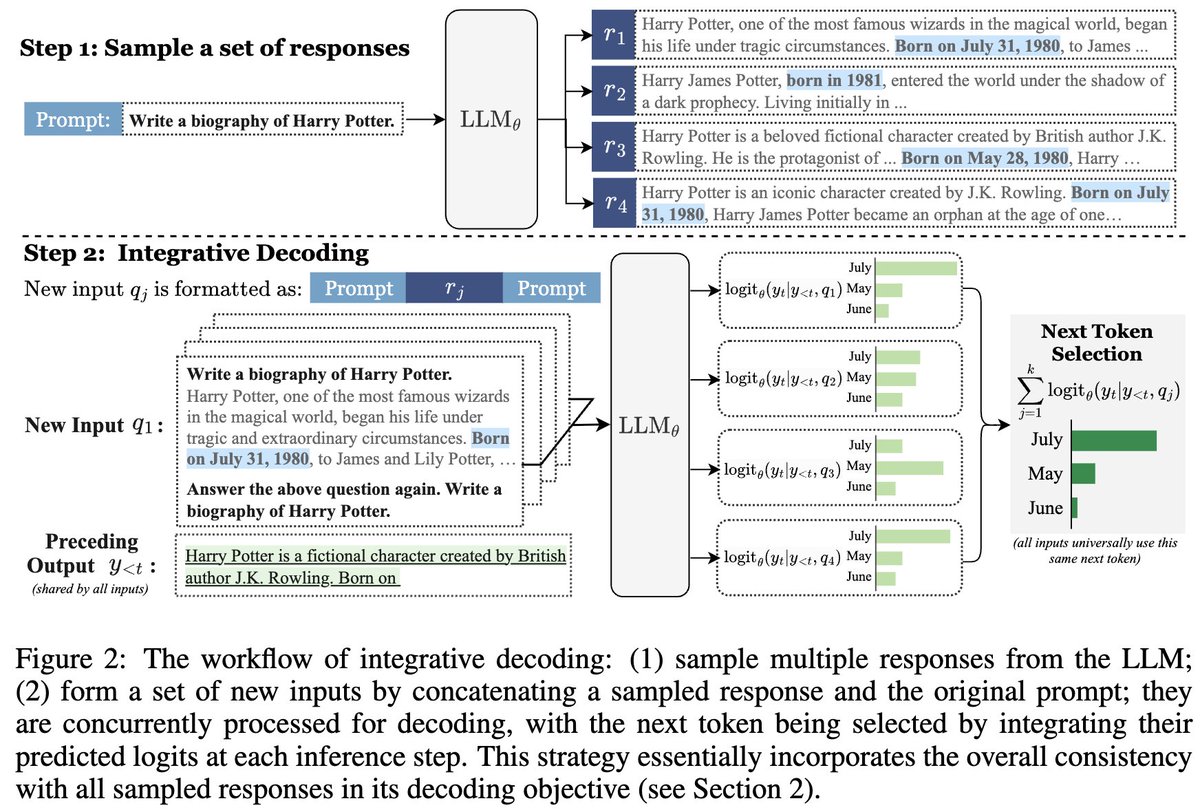
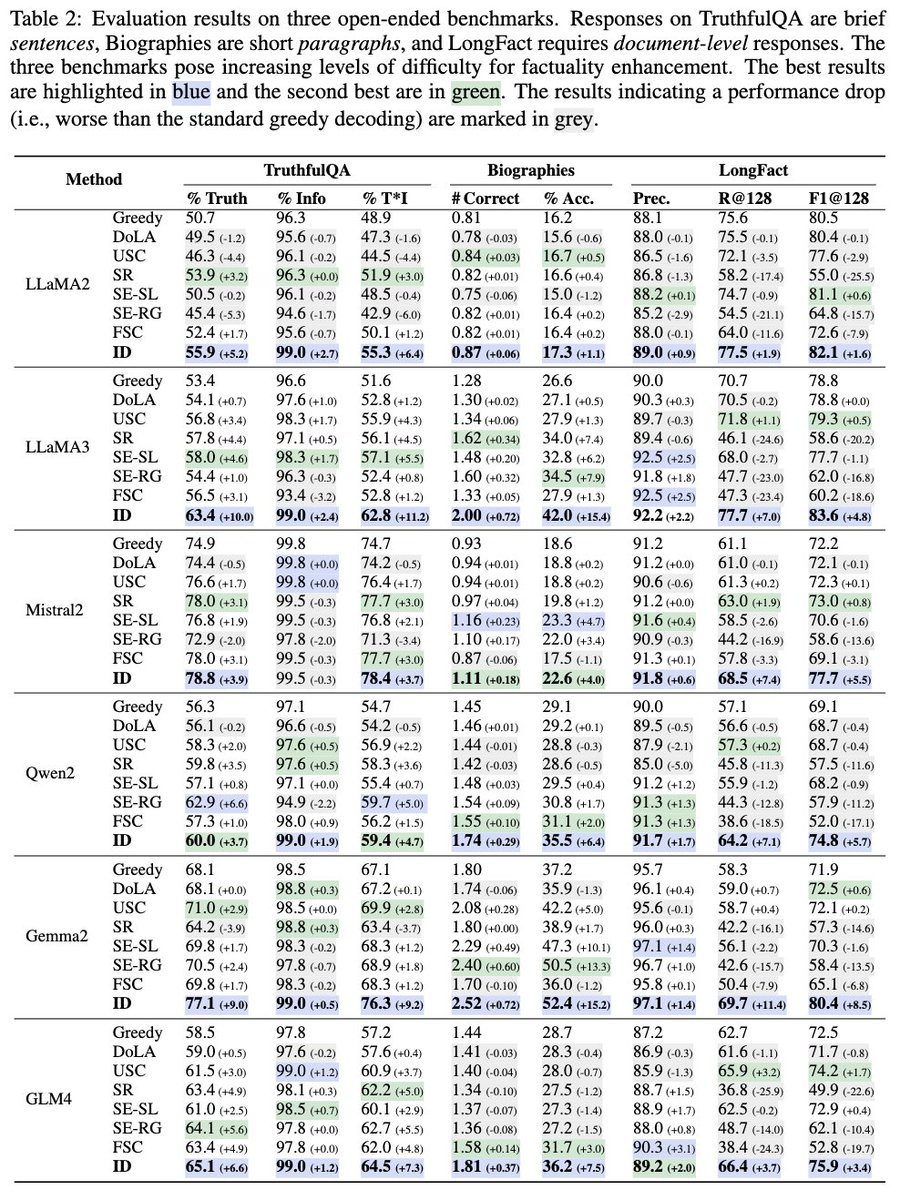
We introduce Integrative Decoding, a novel decoding algorithm to tackle the hallucination problem in LLMs. The core idea is to integrate “self-consistency” into the decoding objective to improve factuality.
✨ Super easy to implement: no training needed, no customized prompt design required. And it has zero restrictions on the generation form, making it a versatile solution for various scenarios.
🧪 We tested it on over a dozen different LLMs and three common benchmarks. The results? Highly stable and significant improvements!
📄 Check out the paper at arxiv.org/pdf/2410.01556
🙏 Big thanks to all our co-authors! @MasterVito0601 @wendyxiao06091 @Yuji_Zhang_NLP @houwenjun060 @xukaish
#ICLR2025 #LLM
English

Vision-language models sometimes hallucinate objects not in the image.
In our #CVPR2024 work, we show that this happens due to excessive reliance on language priors and propose two solutions.
If in Seattle, visit our poster on Thu to learn more!
📄 arxiv.org/abs/2403.14003
English
Wenjun Hou retweetledi

Really excited that our paper "A PhD Student’s🧑🎓 Perspective on Research in NLP in the Era of #LLMs" will be at #COLING2024! We brainstormed 45 topics💡 that students can work on despite the LLMs. Co-led by @OanaIgnatRo @ZhijingJin and @radamihalcea with contributions from many.
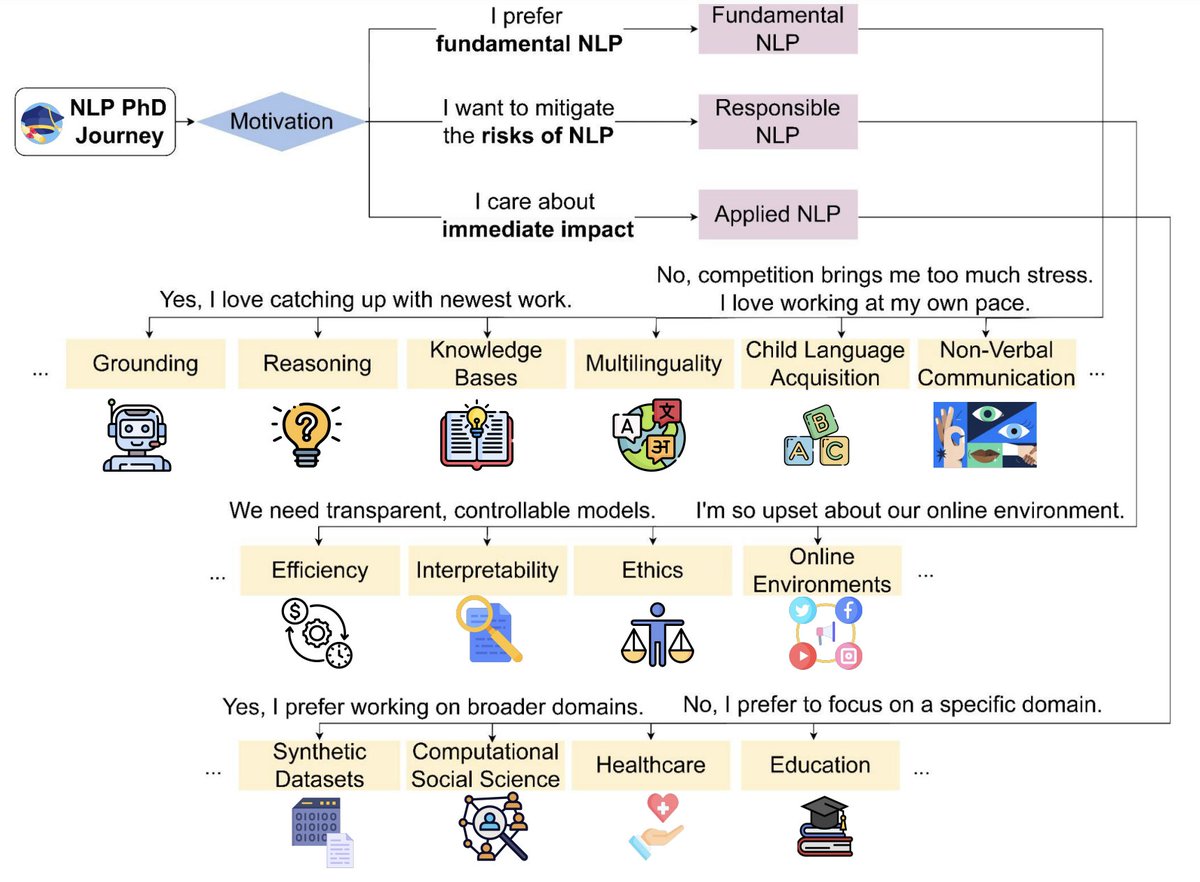
Rada Mihalcea@radamihalcea
“What should I work on?” is a question we hear more & more often from NLP students, during a time when the media rhetoric is that “it’s been all solved” Turns out there are many NLP research areas rich for exploration—here is our answer from 20+ students arxiv.org/abs/2305.12544
English
Wenjun Hou retweetledi
Explore LLM Interpretability with this comprehensive resource compilation:
github.com/cooperleong00/…
📚 Tutorials, libraries, surveys, papers, blogs & more!
📂 Categorized for easy navigation
🔄 Continually updated
🗨️ Your thoughts & feedback are welcome!
#NLProc #LLM
English
Wenjun Hou retweetledi

🚨What is currently the best Speculative Decoding method for accelerating LLM inference?🔍
We introduce Spec-Bench📖: A Comprehensive Benchmark and Unified Evaluation Platform for Speculative Decoding!🚀
Project page: sites.google.com/view/spec-bench
🧵1/n

English
Wenjun Hou retweetledi
Check out our paper at #AAAI2024!
🤔Many recent works found that LLMs struggle to achieve a "complex" dialogue goal through multi-turn interactions strategically.
💡We propose Cooper to address this by coordinating multiple specialized agents towards a complex dialogue goal.

English
📢Can a model generate consistent reports for semantically equivalent radiographs?
📖Check out our new paper "ICON: Improving Inter-Report Consistency for Radiology Report Geneartion via Lesion-aware Mix-up Augmentation" for more details.
🔍arXiv: arxiv.org/abs/2402.12844
English
Wenjun Hou retweetledi

Happy to share that our paper "mPLM-Sim: Better Cross-Lingual Similarity and Transfer in Multilingual
Pretrained Language Models" (with Chengzhi Hu, @zheyu_bot, @andre_t_martins, @HinrichSchuetze) has been accepted to #EACL2024 Findings. See you in Malta!
arxiv.org/abs/2305.13684
English
Wenjun Hou retweetledi

Tuning LLMs has been a prevalent paradigm for building capable dialogue agents. Can a different tuning method enhance the consistency of dialogue generation?
👉 Our recent work may bring some insights!
🔍 arXiv: arxiv.org/abs/2402.06967

English
Wenjun Hou retweetledi
📢Excited to share our new survey paper "Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding"!
Paper: arxiv.org/abs/2401.07851
🧵1/n

English
Wenjun Hou retweetledi

Could I trust LLM critique?
🔥 We are the pioneers in prioritizing critique evaluation and introducing the critique of critique, termed MetaCritique.
Repo: github.com/GAIR-NLP/MetaC…
Paper: arxiv.org/abs/2401.04518
(1/7)

English
Wenjun Hou retweetledi

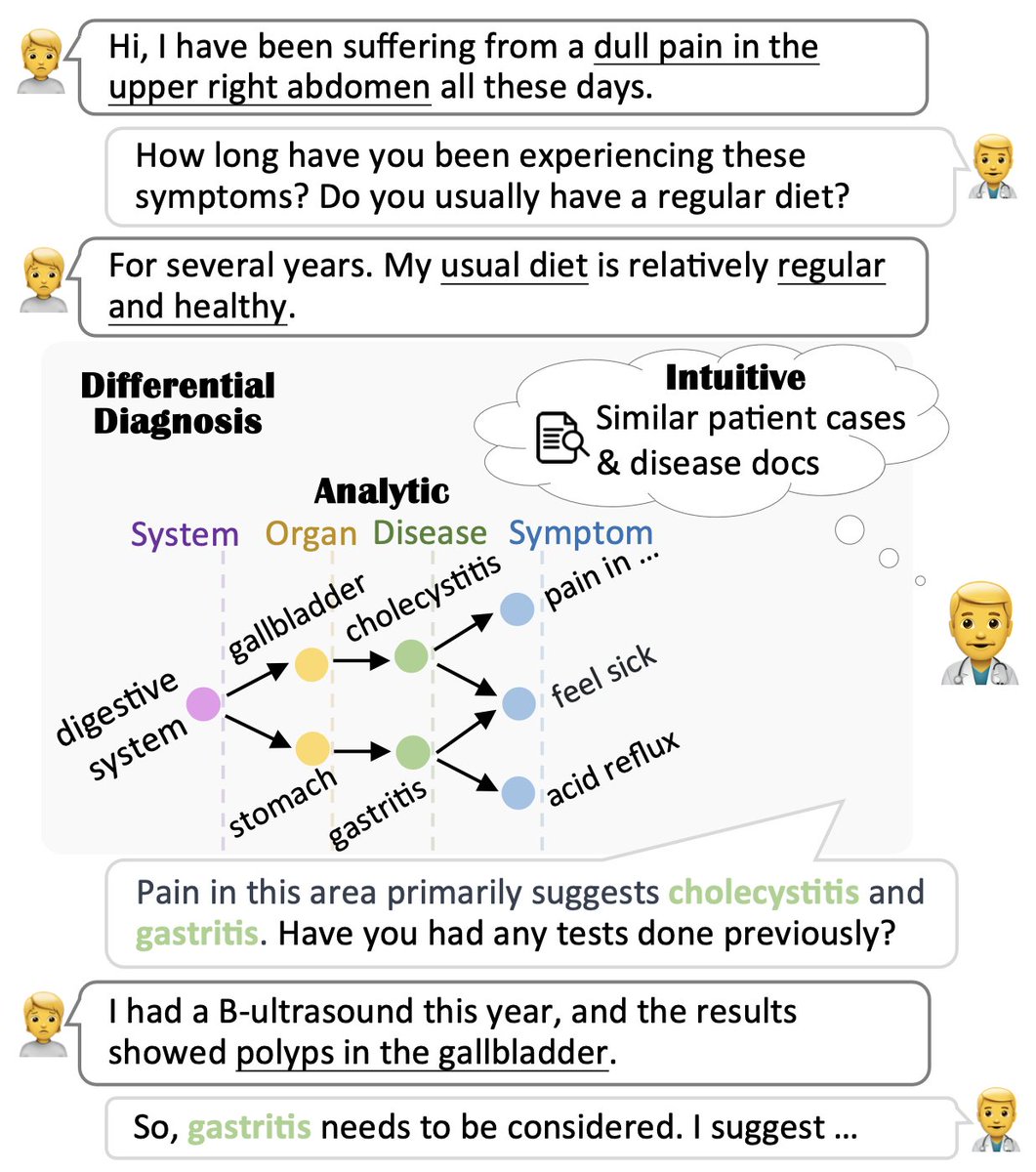
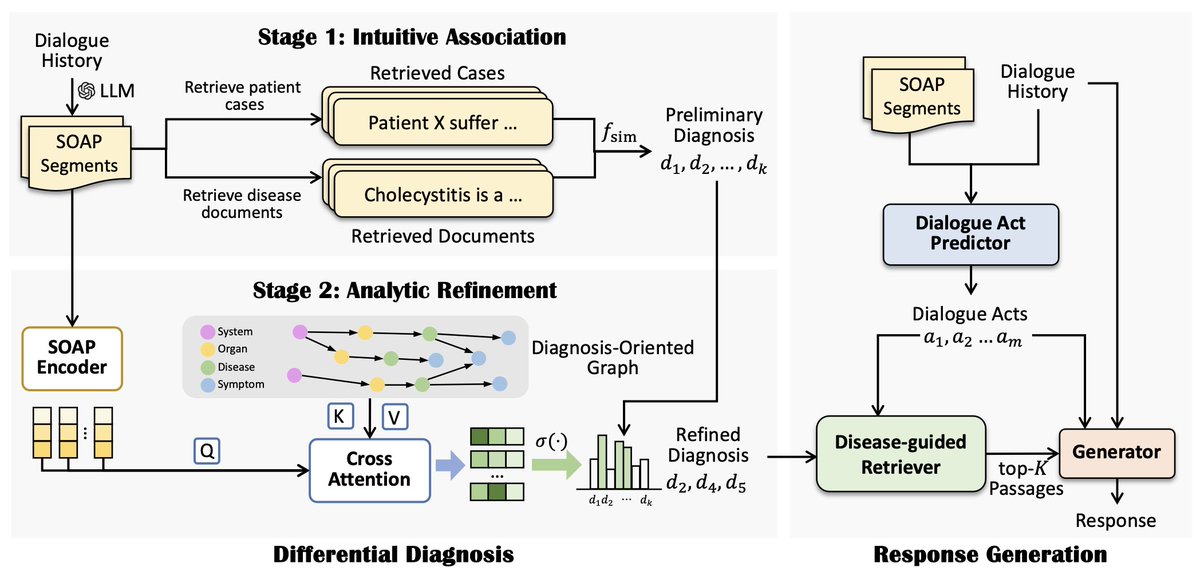
🤒You wouldn't feel at ease letting just a language model be your medical assistant.
👨⚕️An explicit and understandable differential diagnosis is required!
📖Paper: arxiv.org/abs/2401.06541
English
Thrilled to attend the EMNLP@Singapore🇸🇬
We leverage the historical records for precise radiology report generation.
Check out our EMNLP Findings paper for more details:
arxiv.org/abs/2310.13864
English
Wenjun Hou retweetledi
Excited to arrive in Singapore for #EMNLP2023 today! We will present our work in the East Foyer room on Dec. 8.
Feel free to stop by during our poster sessions. I'm looking forward to meeting new and old friends!


English
Wenjun Hou retweetledi
Beyond elated that Glot500 won an Area Chair award.
I'll also be presenting on this at:
- Jul 11 (Tue), 09:00-09:15, Metropolitan Centre
- Jul 12 (Wed), 09:00, Bay - Unit 3
Come if you are interested in multilinguality and scaling large language models to 500+ languages.
Ayyoob Imani@imani_ayyoob
Excited that our paper "Glot500: Scaling Multilingual Corpora and Language Models to 500 Languages" won the Area Chair Award at #ACL2023. Big kudos to our squad at @CisLmu who made it all happen. @lpq29743 to present the findings. #NLProc
English
Wenjun Hou retweetledi
Excited to be in Toronto for two days! I will present our #ACL2023NLP work "Dialogue Planning via Brownian Bridge Stochastic Process for Goal-directed Proactive Dialogue" in the spotlight session on Monday, July 10, 19:00-21:00, Metropolitan East. Welcome to have a chat!🤗
English