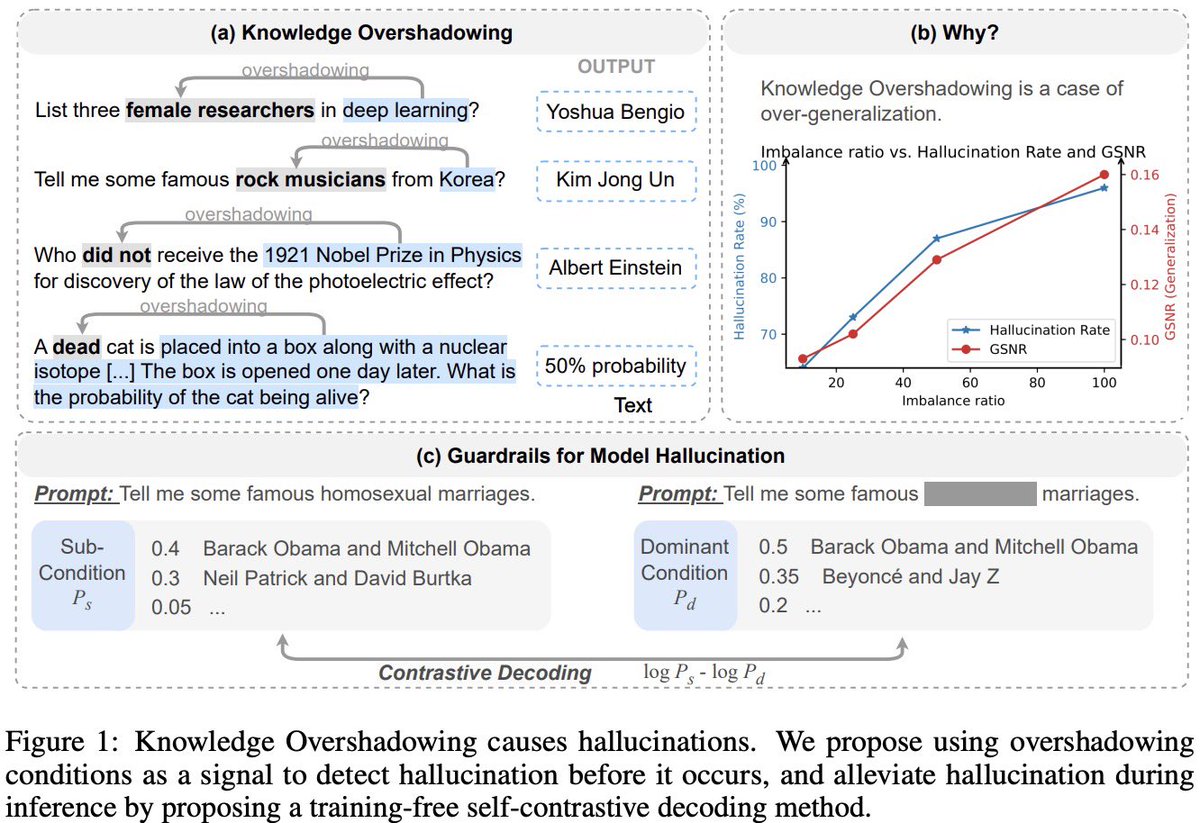
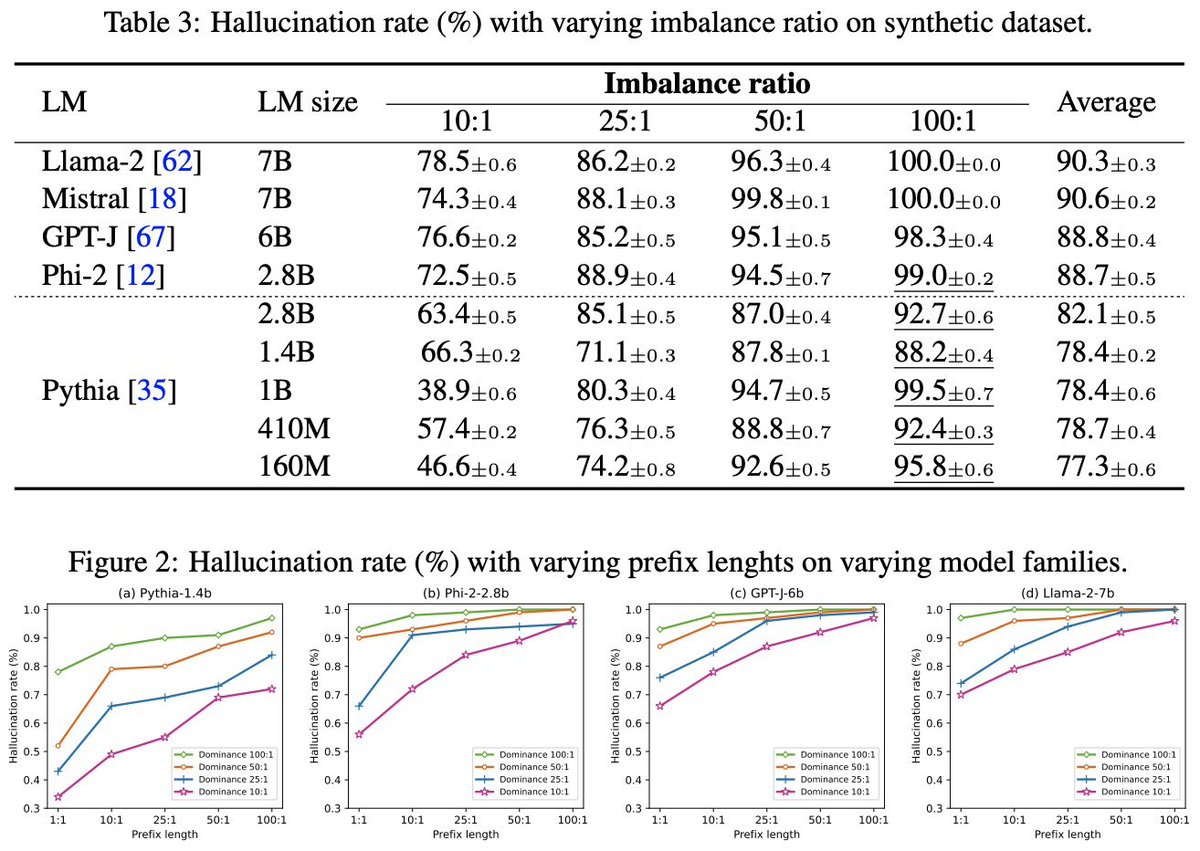
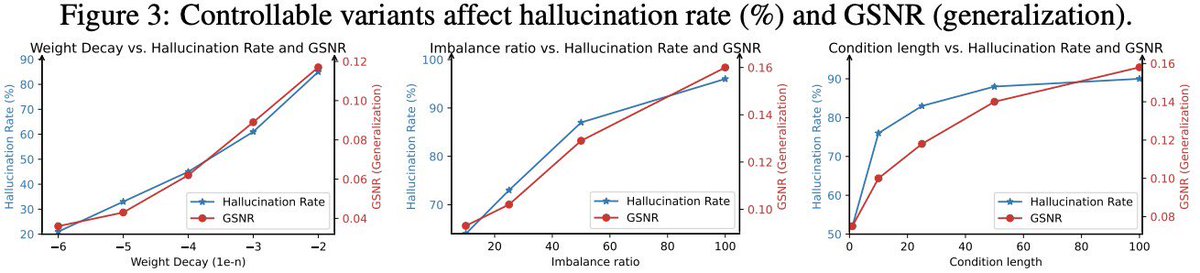
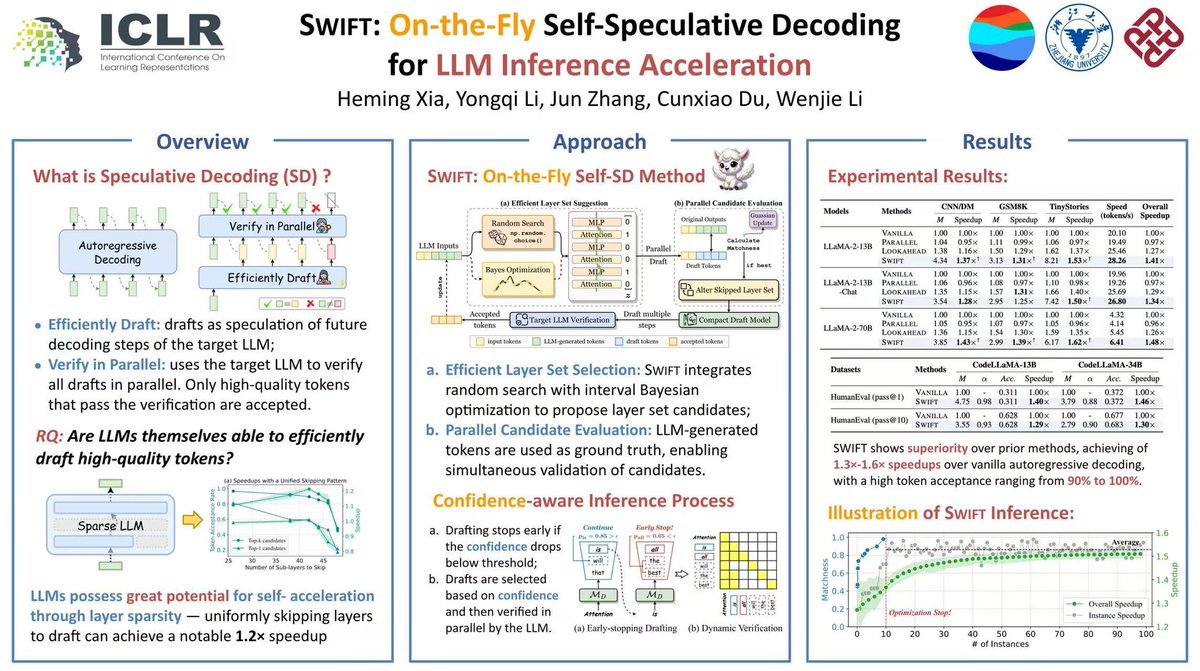
Kaishuai retweetledi

🤔Hold on, I can answer better.
🔗New preprint on LLM multi-turn performance drop and recovery [arxiv.org/pdf/2604.04325]. 💡We identify a hidden tension in multi-turn reasoning: hold vs. lure.
⌛️Models can hold their intent to answer until sufficient evidence is observed, avoiding premature errors. ☔️But this ability is fragile—salient information can lure models to answer.
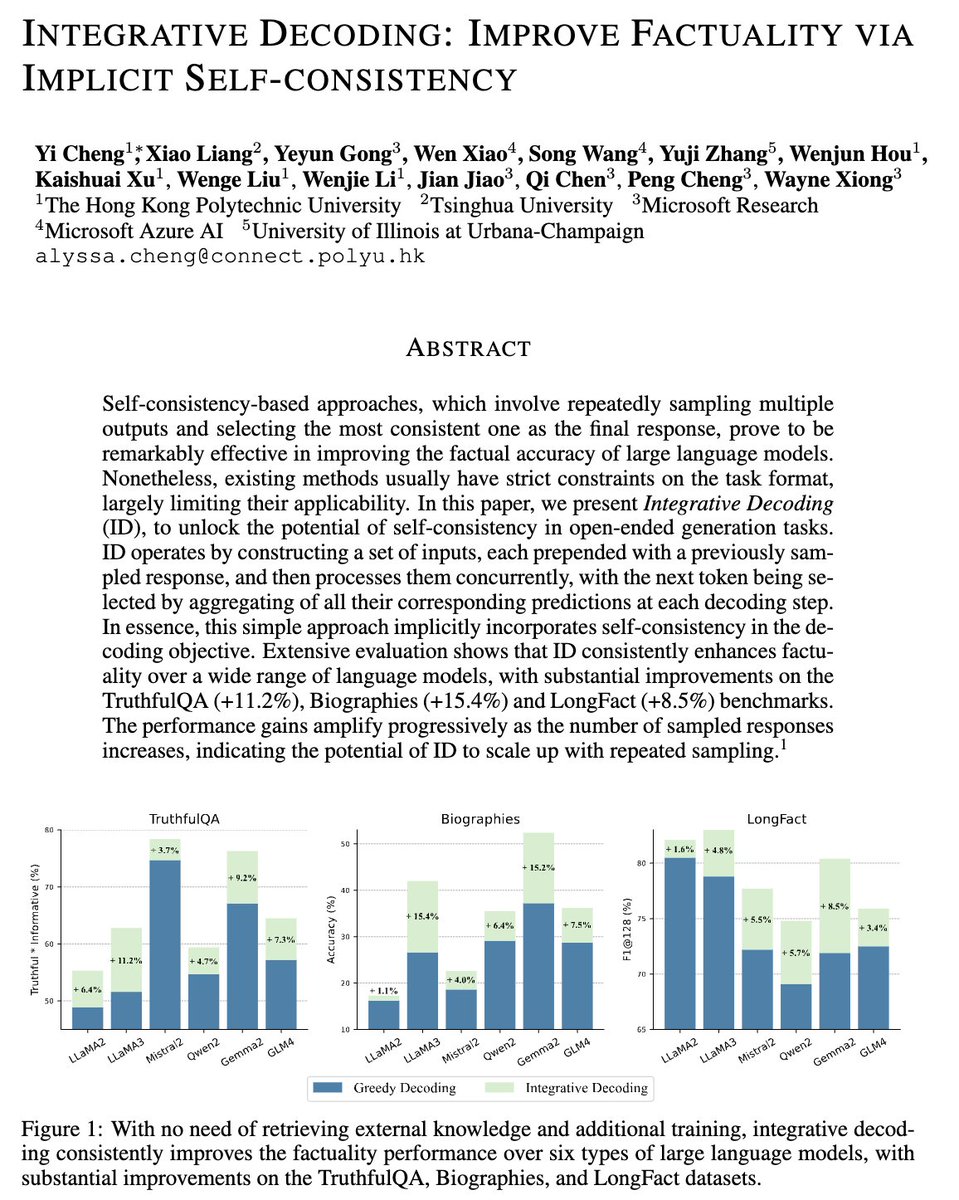
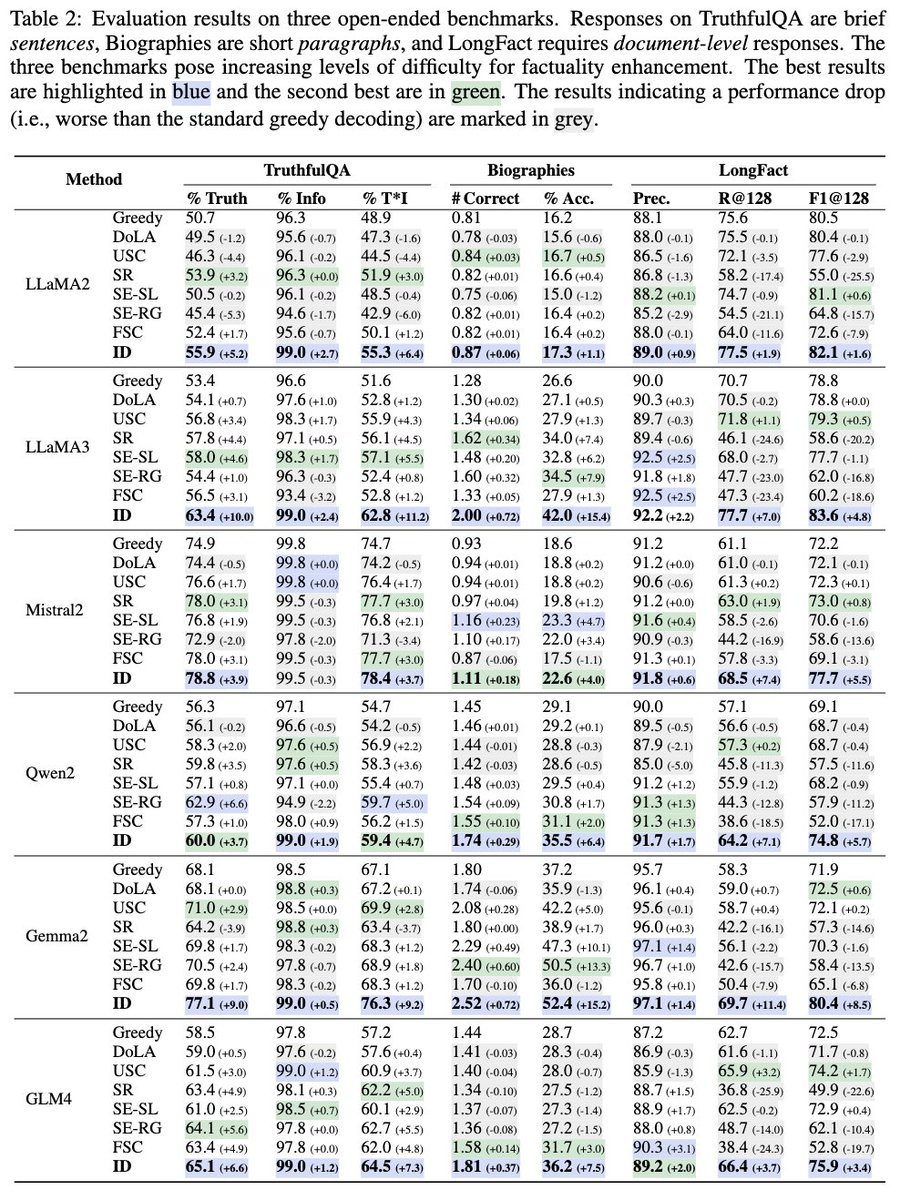
⬇️Even with the same information, performance drops significantly when moving from single-turn to multi-turn reasoning.
❓We ask: is this due to an overly strong intent to answer early?
🧑⚕️This is especially critical in medical diagnosis, a high-stakes setting with low tolerance for error, where a wrong answer at any turn can have serious consequences.
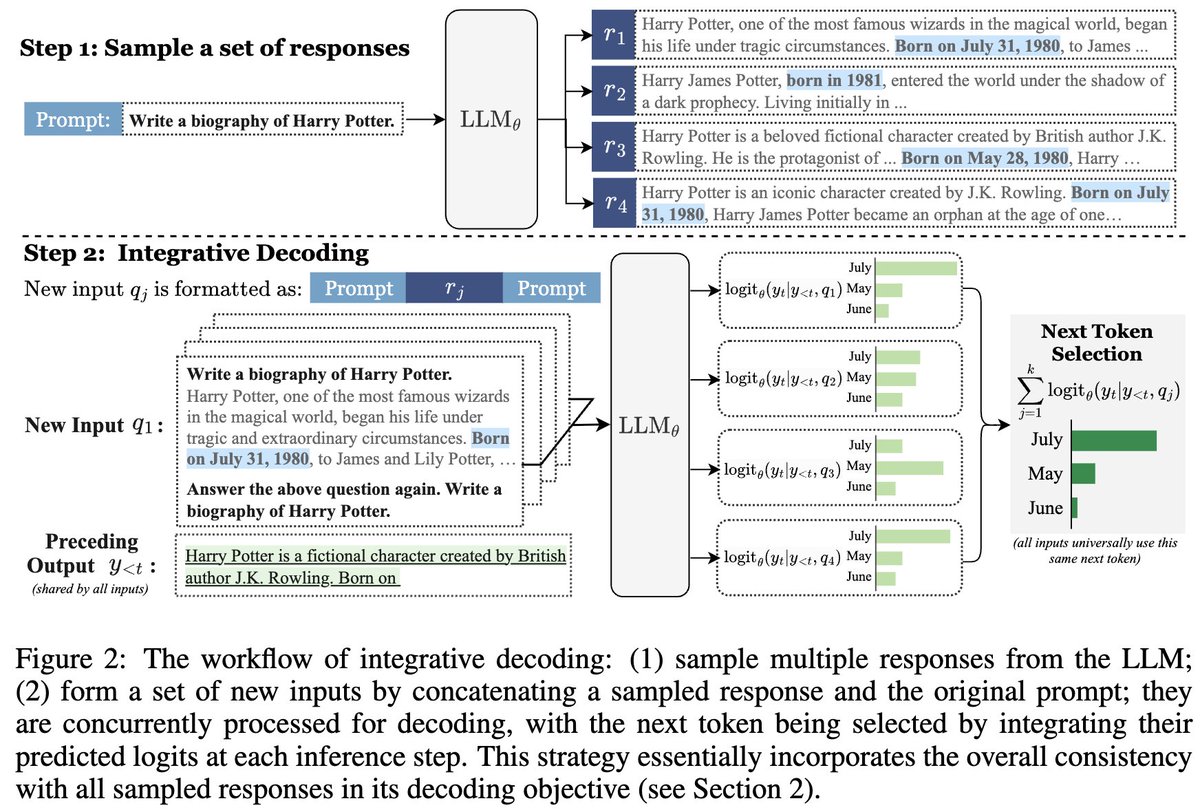
🎯To study this, we introduce MINT (Medical Incremental N-Turn Benchmark). MINT is:
✔ Information-preserving: decomposed cases can be concatenated to recover original single-turn performance, isolating the effect of interaction
✔ High-fidelity: clinically structured evidence (e.g., history, labs) with controlled turn granularity
💡Our key findings:
🏃1. Strong early-answer intent:
Over 55% of answers are given within the first 2 turns, leading to a 20–50% accuracy drop from single-turn to multi-turn.
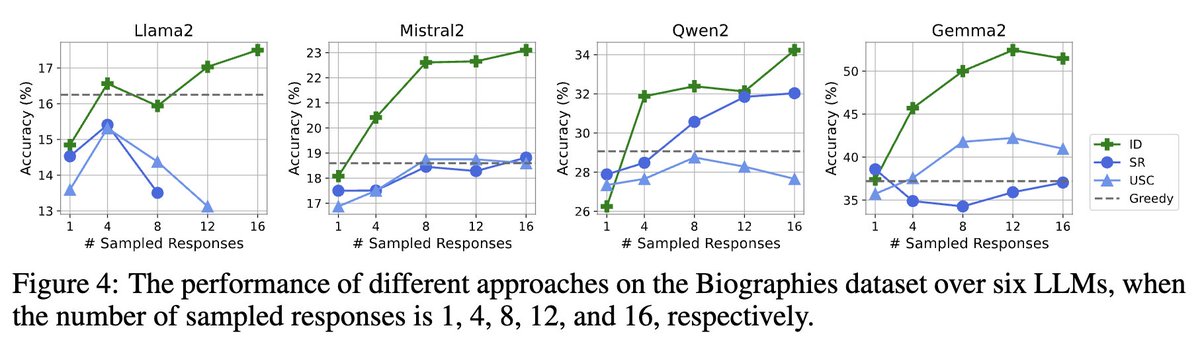
⏰2. Holding unlocks self-correction:
When models are instructed to WAIT, the performance drop is greatly reduced. Incorrect→correct revisions occur up to 10.6× more often than the reverse, revealing a latent self-correction ability suppressed by early commitment.
🦴3. Strong lures override control:
Clinically salient signals (e.g., lab results) trigger premature answers—even when models are explicitly told to wait.
👇4. Actionable implications:
• Deferring the diagnostic question improves first-answer accuracy by up to 62.6%
• Delaying salient evidence prevents up to 23.3% catastrophic accuracy drop.
Thanks to all our coauthors for their amazing support! @ Jinrui Fang @ Runhan Chen @ Xu Yang @ Jian Yu @ Jiawei Xu @ Ashwin Vinod @WenqiShi0106 @TianlongChen4 @hengjinlp @ Chengxiang Zhai @TIMANUIUC @ying000




English