Hung retweetledi

太炸裂了,居然有人做了款能直接看懂K线交易的AI,
胜率还高达93%!
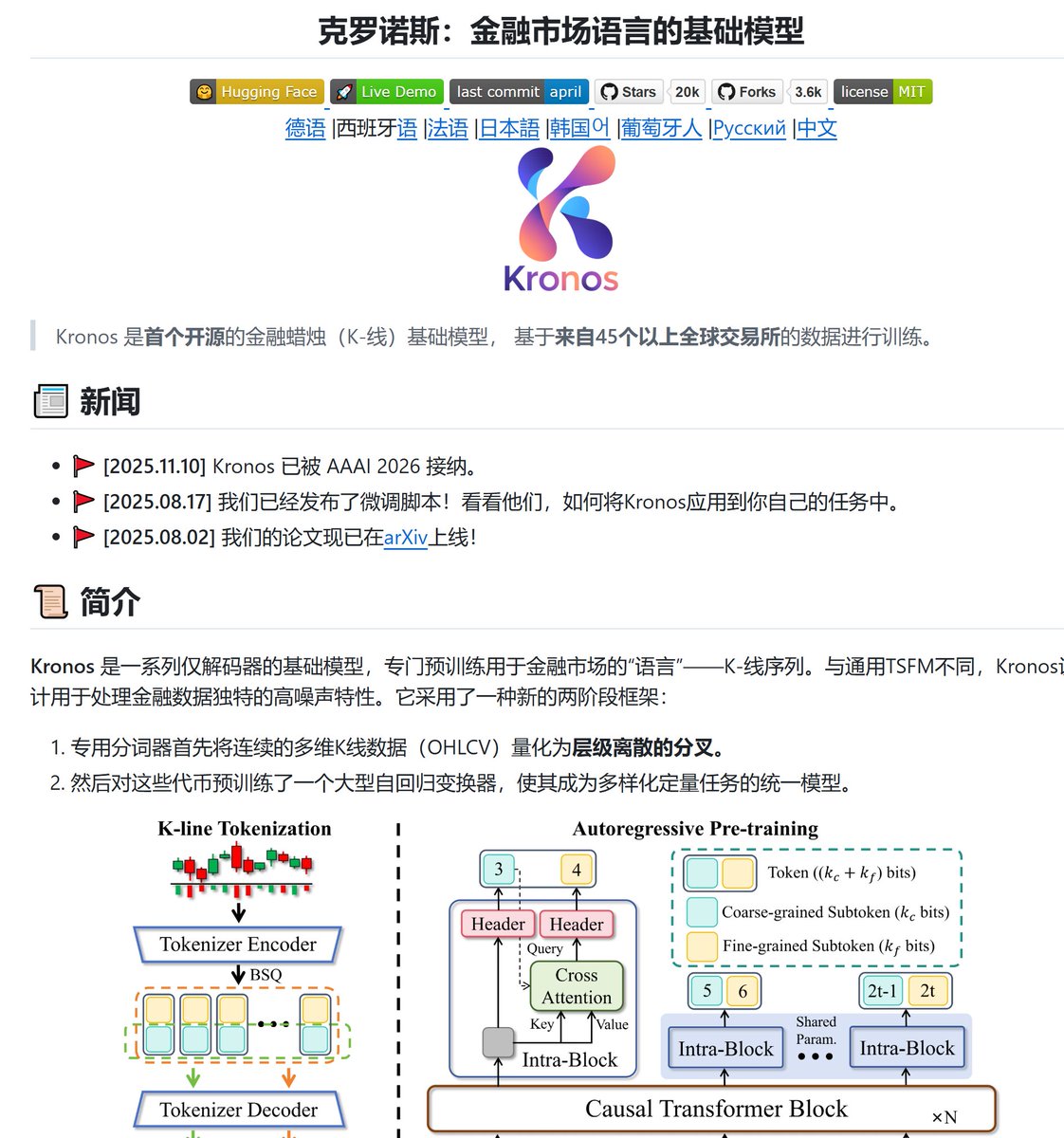
这款AI叫Kronos,靠45家交易所120亿条数据训练,是首个专门为金融市场打造的开源基础大模型,从底层就是为K线和交易逻辑设计,不是通用AI改出来的。
它能做价格预测、波动率预判,支持全资产零样本直接使用,覆盖币安、纽交所、纳斯达克等45家交易所,从400万到4.99亿参数共4个版本,笔记本就能跑。
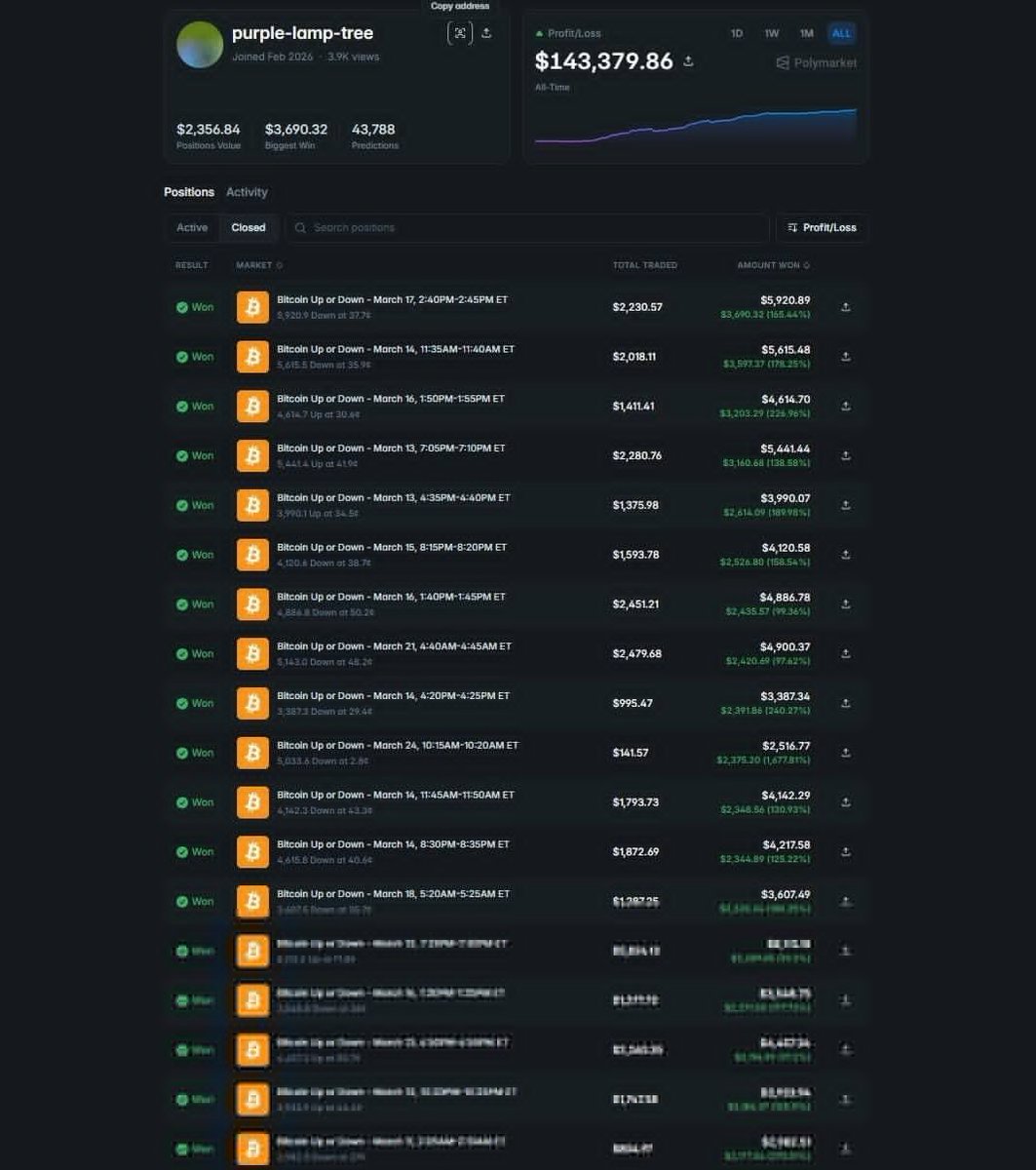
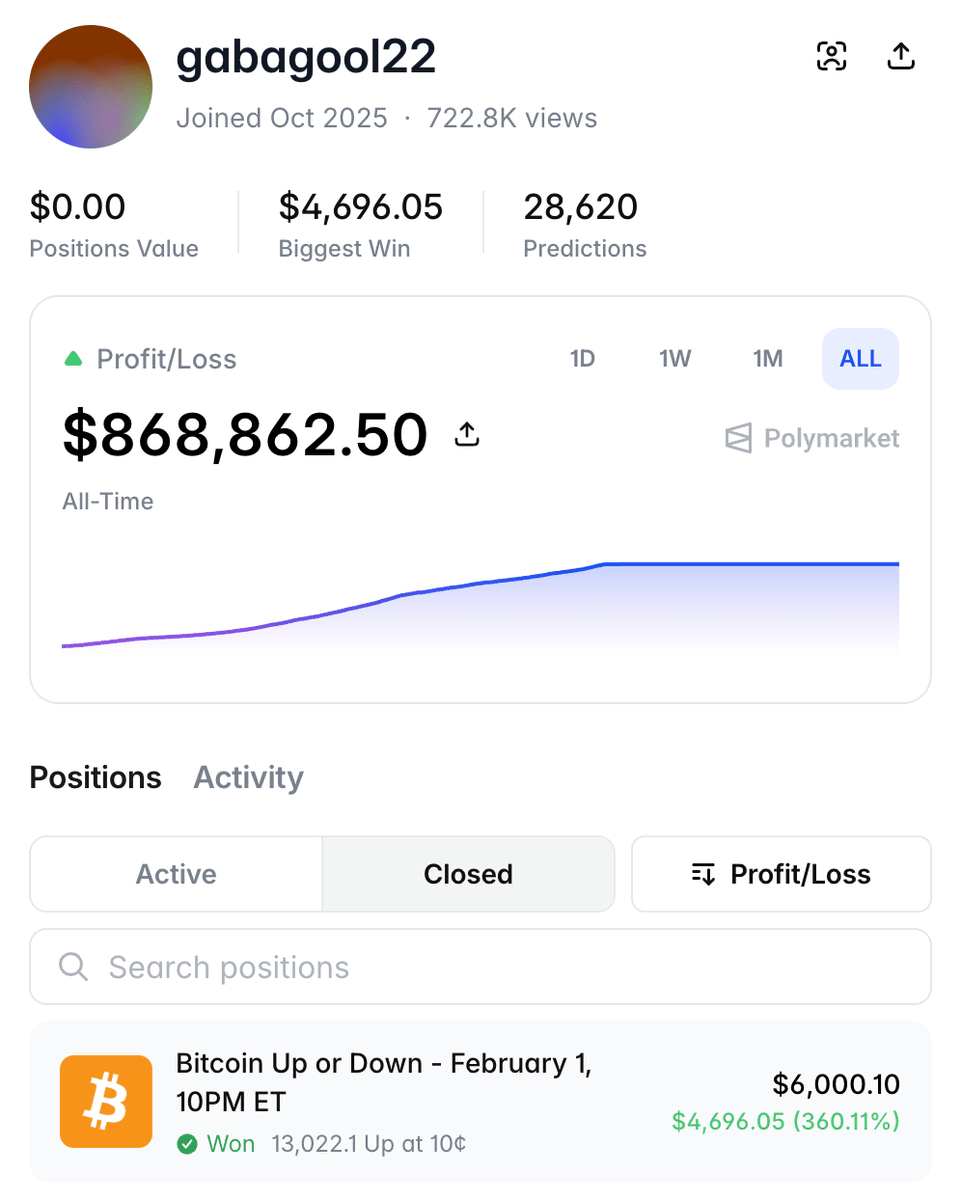
实测效果很夸张:准确率比主流时序模型高93%,比顶尖非预训练模型高87%,而且不用微调,拿来就用。目前BTC实时走势演示免费开放,每小时更新。
对比之下,对冲基金定制模型要几百万,彭博终端年费2.4万美金,而Kronos完全免费,几行Python就能调用。
由清华团队研发,入选2026 AAAI顶会,现已上架Hugging Face,GitHub斩获1.16万星标、2400复刻,MIT协议,100%开源。
github.com/shiyu-coder/Kr…
中文