
Very crazy stuff
This (and things like this) will be the future
funkii.sui@funkii
This is @t2000ai. Full article on how it all works: x.com/funkii/status/…
English
Hvx Crypto
3.6K posts

@hvxcrypto
Let's explore the crypto jungle together.
This is @t2000ai. Full article on how it all works: x.com/funkii/status/…


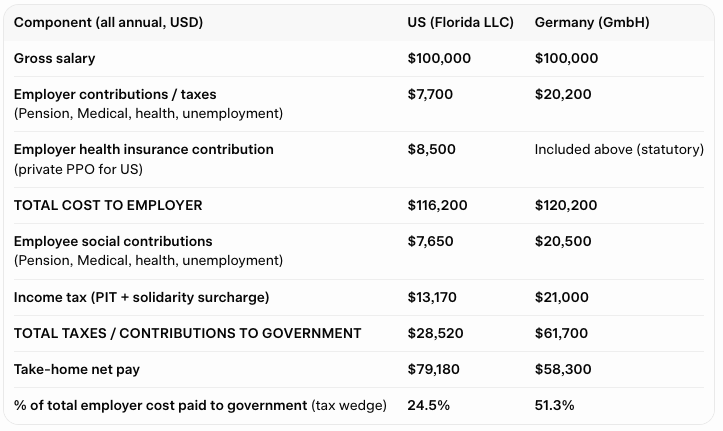



Announcing companies.sh - the open standard for Agent Companies Import and run entire companies with a single command Just run `npx companies.sh add <repo/company>` More 👇



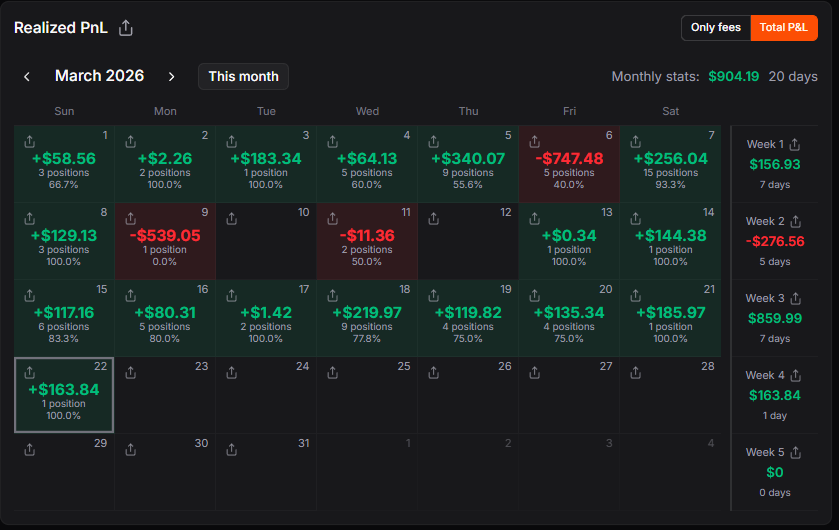



@sbaratelli @nvidia @openclaw most folks will want as much intelligence as possible, and open models aren't there yet.



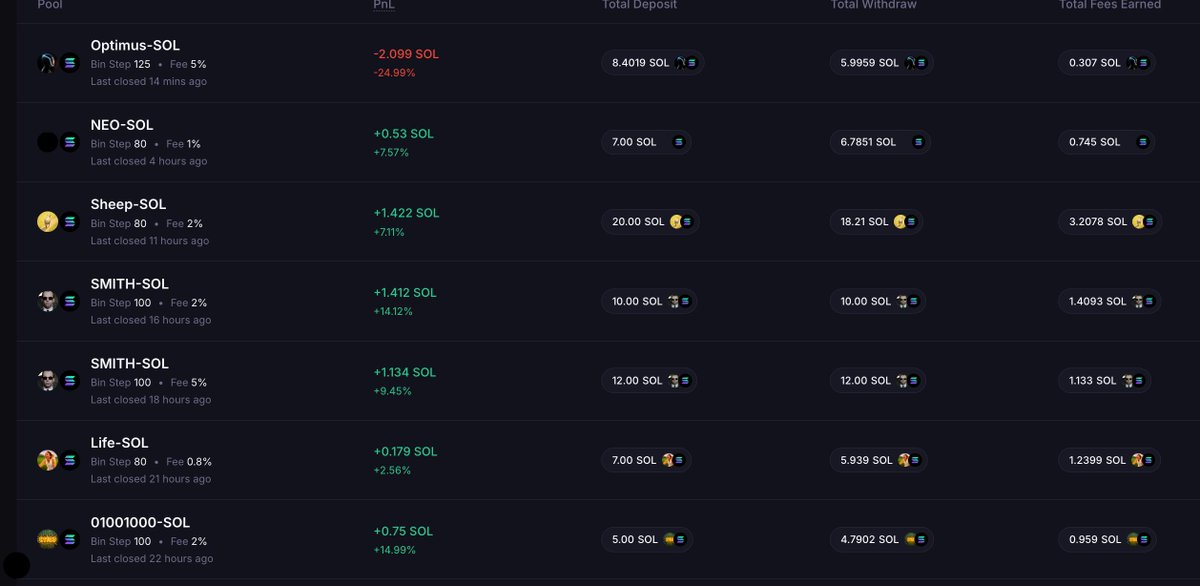
Bear market and relatively low activity doesn't really mean you have to sit down and do nothing. I wasn't actively LPing for some time, but today, using @MeteoraAG Discovery, it takes me 5 minutes to find and open a position once or twice a day. Each day I earn 50-200$ on these small wins, and I hope they will compound. The strategy for those more or less passive and easy LPs is really simple, and I will share it here tommorow!



OpenFang: The Rust-Powered Agent OS Will Soon Be Taking Over The Internet search.app/rzHzG

