
Hongcheng
5K posts

Hongcheng
@hzhu_
Tech & Stocks Investing in tech stocks Writing https://t.co/FEEWR8xUvX Building: https://t.co/ZuZt3Vcian
The Bay Area, California Katılım Nisan 2021
1.8K Takip Edilen1.8K Takipçiler


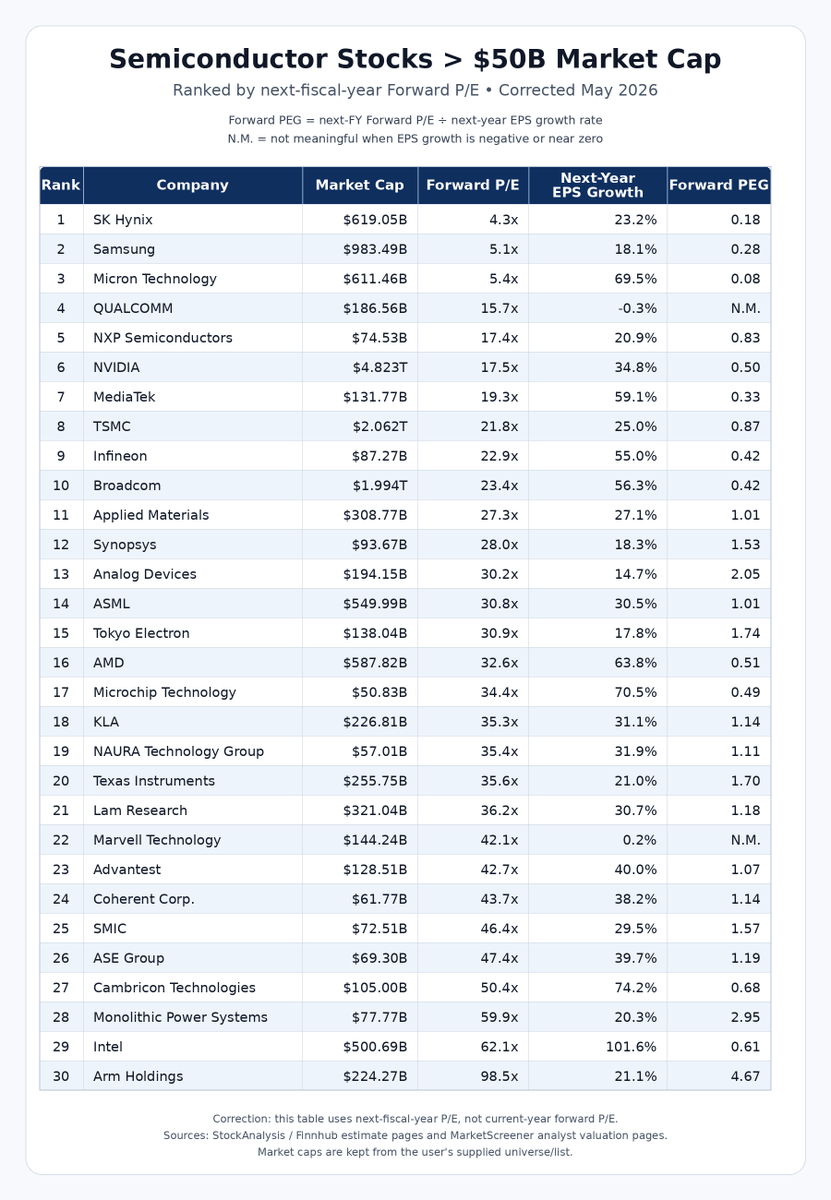
Current semi stocks ranking by forward PE / forward PEG
note - directional only, data might vary depending on sources or the method
English
@stuart983 @The_AI_Investor 现在才买大概率已经晚了。我是两年前买的台积电。现在可以考虑配置两个ETF,$SOXX 和 $DRAM,省事,不用研究。不过不要期望太高,这两个指数已经涨了很多。
$DRAM 大仓位持有这个表里的前三家公司,其中前两家是韩国上市公司,美股没有,散户不太容易买。
中文
Hongcheng retweetledi
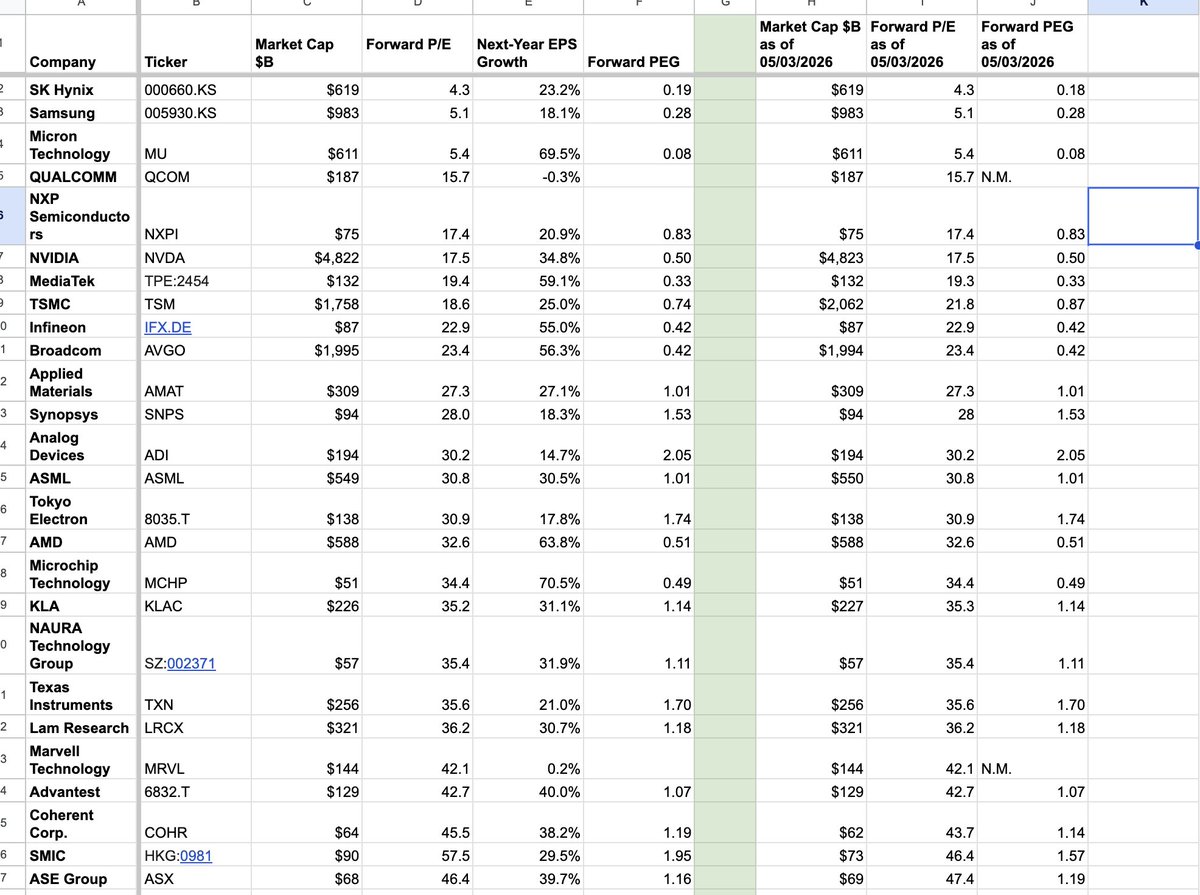
@The_AI_Investor I created a Google Spreadsheet for this table. The P/E and PEG ratios will automatically update based on each company’s latest market cap. Hope it helps.
$MU $INTC
docs.google.com/spreadsheets/d…
English
@sandeepDshah @thesincerevp Could you kindly name a few big customers beyond OpenAI?
English

@thesincerevp Everyone uses Cerebras in 2026. They are legit lol. They will be worth $100B+ in the next 24 months.
English
@realroseceline It's not trivial to record a negative return in the past 15 years in the US market :)
English

If you underperform the market for like 15 years, at some point you have to wake up and smell the roses (pun intended), stop blaming the market and start questioning your abilities. At some point you have to look in the mirror, because when you point one finger, the rest are pointing back at you.
I wouldn’t usually say it this bluntly, but getting blocked kind of removes the incentive to be polite. Either he’s one of the greatest salesmen alive or his investors are to put it mildly retarded. 🌹

English
@firstadopter Wonderful! I'm going to switch to it. Hope Google won't kill this product.
English

"I think in many ways Google is still underrated, just in terms of the breadth and depth of what they do."
– Sam Altman in a recent @stratechery interview
$GOOG
English

挺有意思的研究。
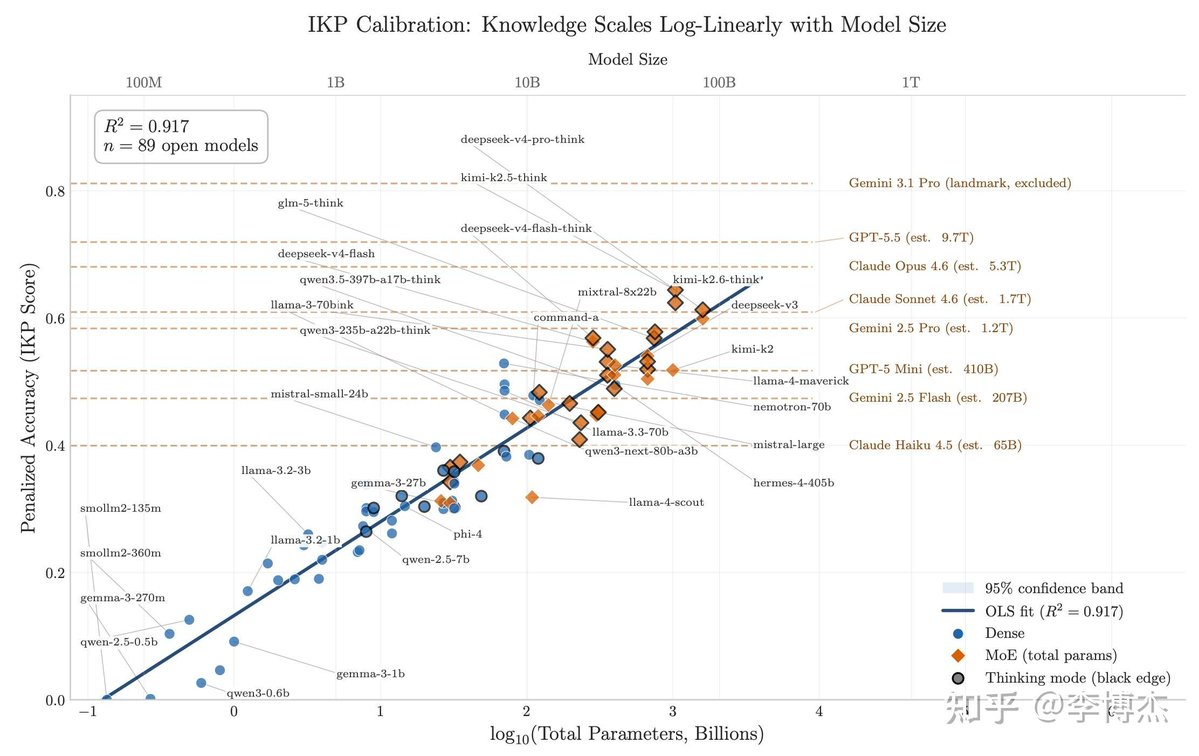
闭源实验室都对模型规模讳莫如深,但他们其实藏不住模型"知道什么"。而模型知道什么,恰恰就是参数量的指标。
核心逻辑:推理能力可以靠蒸馏压缩到小模型里,事实知识不行。一个模型记得多少冷门事实,直接跟它的参数量挂钩。
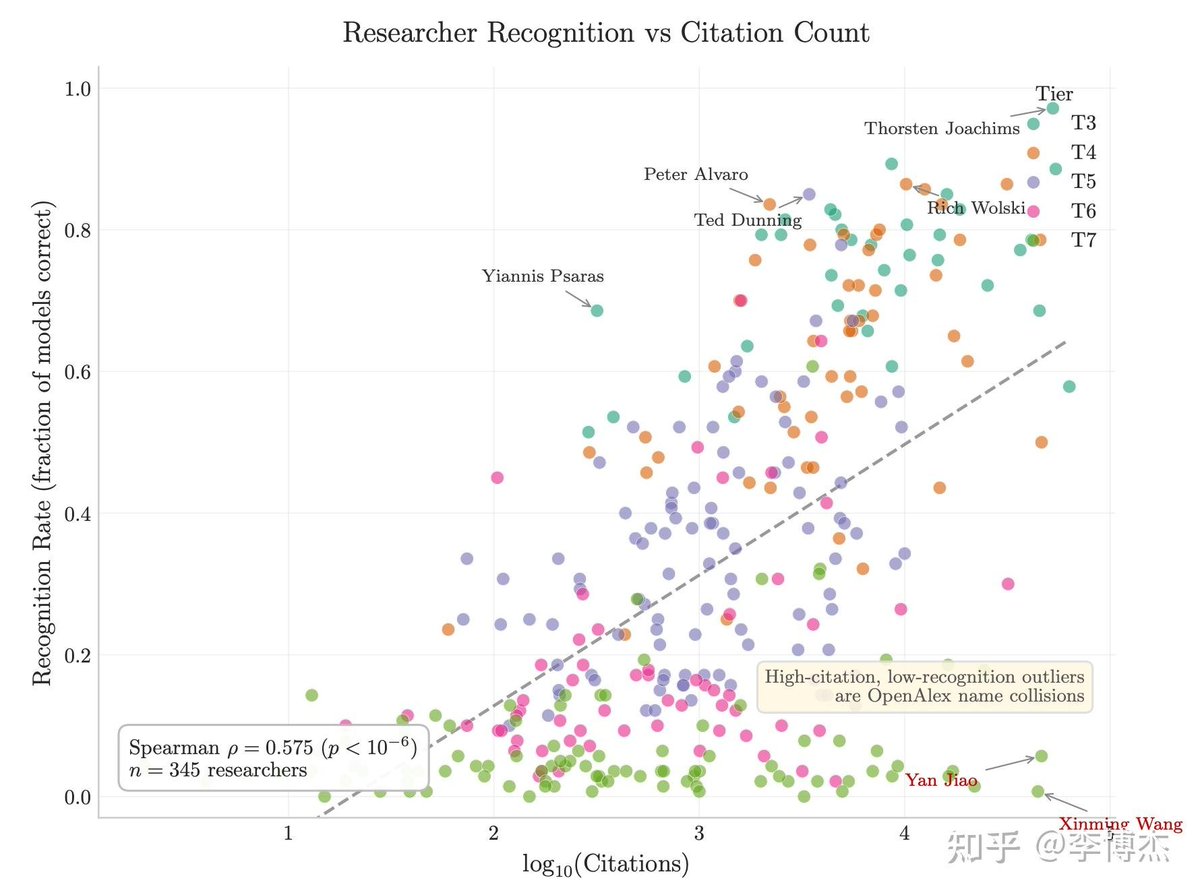
知乎博主李博杰为这个写了一篇小论文,构建了一套叫 IKP(不可压缩知识探针)的数据集:1400 个问题、7 层稀有度,扔到 27 家厂商的 188 个模型上跑了一遍,只看事实准确率。
结果在 89 个公开参数的开源模型上,准确率 vs log(参数量) 的拟合 R²=0.917,基本是一条直线。把闭源模型投影上去,规模就估出来了:
GPT-5.5 ≈ 9T
Claude Opus 4.7 ≈ 4T
GPT-5.4 ≈ 2.2T
Claude Sonnet 4.6 ≈ 1.7T
Gemini 2.5 Pro ≈ 1.2T
(90% 置信区间:0.3-3 倍规模)
另外两个发现也挺反直觉:
一是引用数和 h-index 不能预测一个研究者是否被前沿模型认识。两个引用数相近的人,模型给的回答可能完全不一样。它记的是有影响力的工作,不是论文数量。
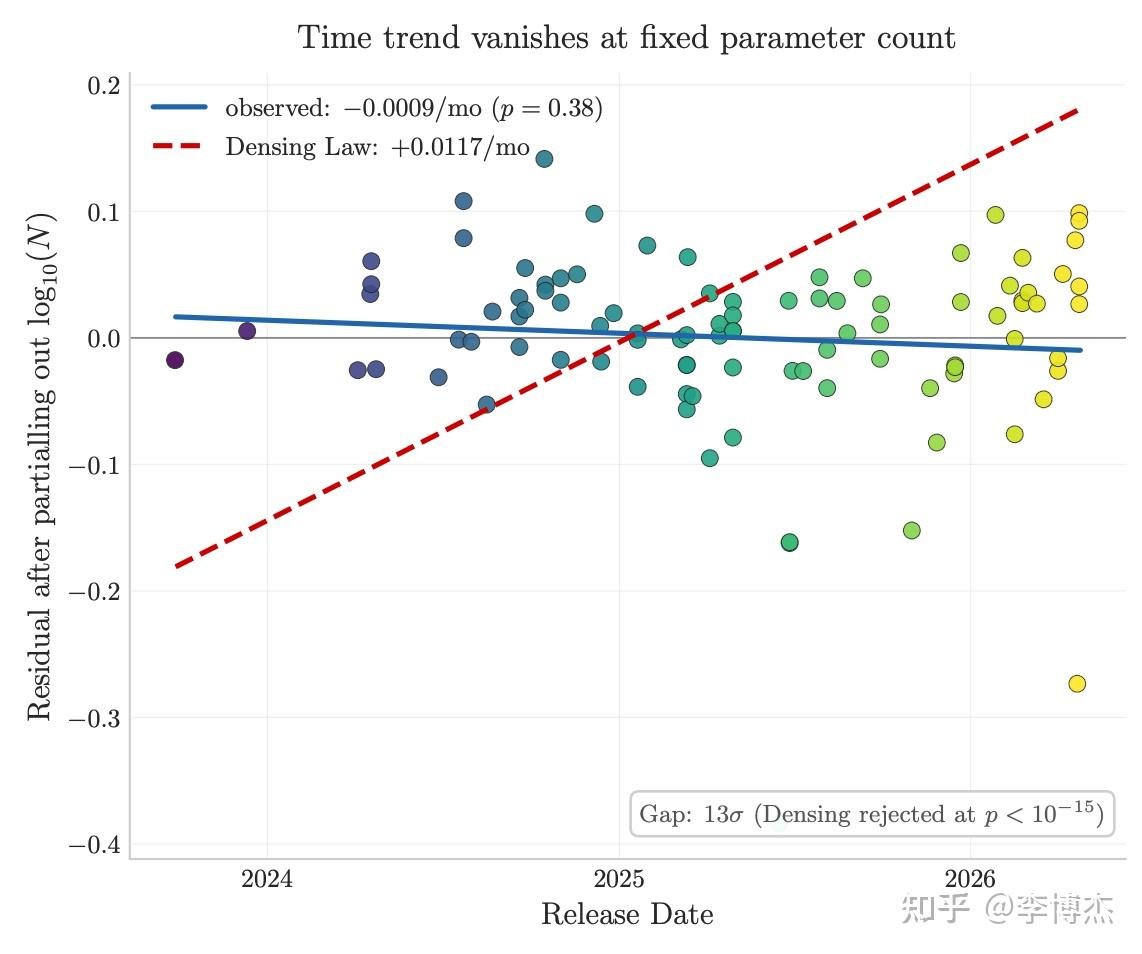
二是事实容量不会被时间压缩。跨 3 年的 96 个开源模型,IKP 时间系数统计上为零(p<10⁻¹⁵),直接拒绝了 Densing Law 预测的 +0.0117/月衰减。benchmark 在饱和,但事实容量还在随参数继续扩张。
来源:知乎博主 李博杰
侵权联系删
arxiv.org/pdf/2604.24827
中文
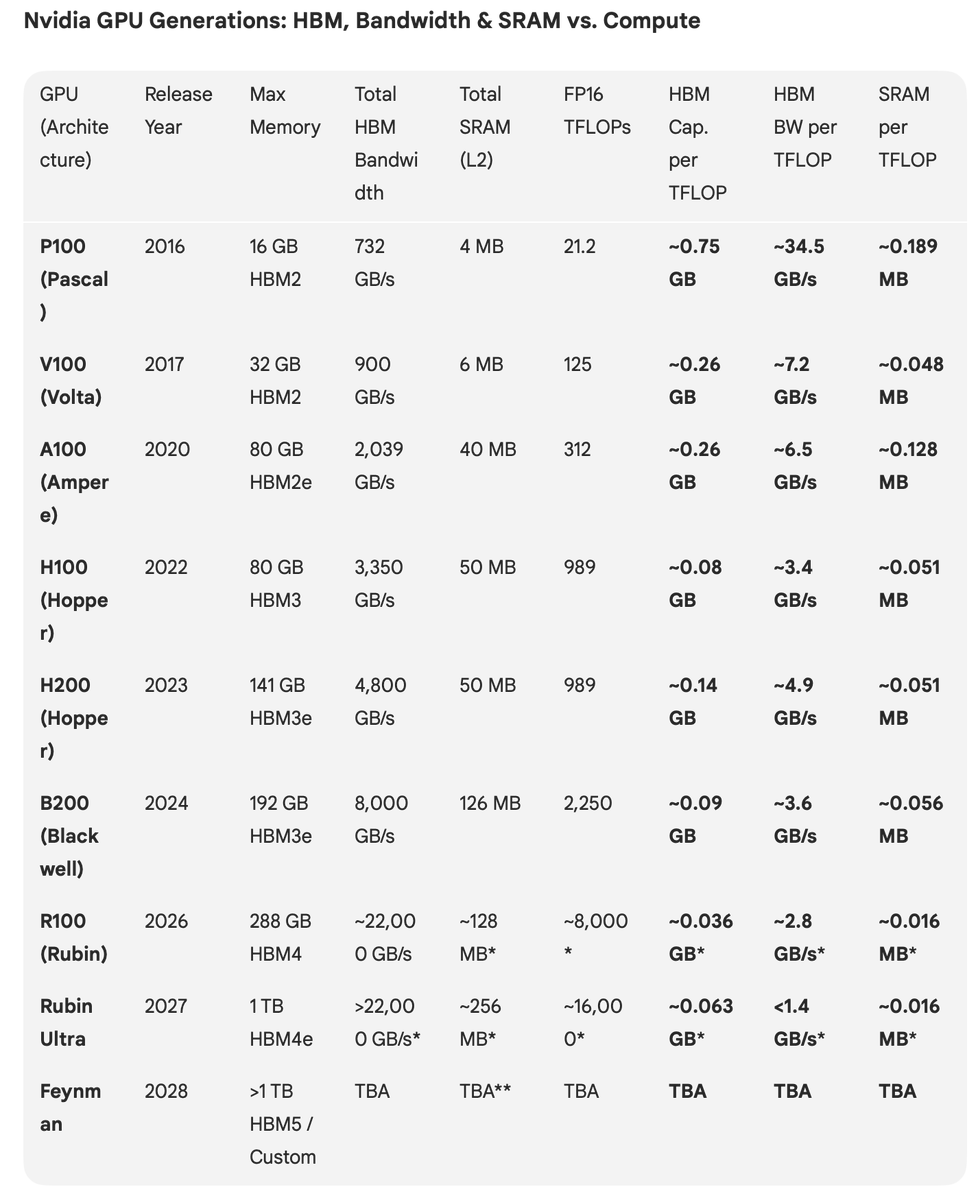
@fi56622380 写得很精彩,感谢分享。有一个反直觉的数据,Nvidia GPU的每tflog的HMB capaciy和bandwidth趋势是逐代下降的。HBM技术进步赶不上算力进步的速度,memory wall瓶颈越来越严重。
$NVDA
中文

AI半导体终局推演2026(I)
当新token经济学范式从GPU算力转移到HBM
本文从从GPU架构进化路线本质出发,解释这个市场长久以来担心的问题:
每个GPU的HBM内存需求为什么一定会是指数增长,为什么HBM需求指数增长不会停滞?
并推导token经济学在当前架构下第一性原理:token吞吐 = HBM size X HBM BW带宽
同时讨论了,为什么GPU的天花板被HBM的两个发展维度所决定
HBM周期性这个话题争议一直很大,乐观派认为AI带来的需求比以前要大的多,但市场主流仍然认为前几次上升周期也有需求每年20%+增长,这次又有什么不一样呢?AI不影响HBM和传统DRAM一样有commodity属性,一旦在需求顶峰扩产遇上需求下行又会重蹈覆辙。
我们可以从算力芯片架构视角,从第一性原理出发,来拆解和推演一下这个问题:为什么这次真的不一样
-------------------------------
历史:CPU算力时代
很久以来,我们都处在CPU主导算力的时代,CPU的最高级KPI就是performance,跑的更快,所以每一代的CPU都用各种方法来提高跑分,最开始是频率上升,后来是架构演进superscaler等等
这个时候为什么DDR不需要很快的技术进步速度?比如DDR3到DDR5竟然经历了15年之久
因为这个时期的DDR的角色是纯粹的辅助,而且辅助功能极弱,以业界经验,DDR的速度即便是提高一倍,CPU的performance一般只能提高不到20%这个量级
为什么DDR带宽速度提高了用处不大?两个原因
1. CPU设计了各种架构去隐藏 DDR延迟,比如superscaler,加大发射宽度,用海量的ROB和register renaming来提高并行度隐藏延迟,一级缓存cache,二级缓存cache,削弱了DDR的带宽速度需求
2. CPU workload对DDR带宽要求并不高,大部分日常负载比如打开网页,DDR带宽是严重过剩的,甚至云端负载
也就是说,在CPU时代,DDR的带宽速度是不太有所谓的,DDR4和DDR5除了少数游戏就没啥差别,甚至JEDEC标准也进步缓慢。
另外,绝大部分app需要一直停留在DDR上的部分并不多,需要的时候从硬盘上调度到DDR即可,app的size增长没那么快,导致对DDR的容量需求也较为缓慢。
所以最近十年来,平均每台电脑上的DDR容量大概从7~8GB变成了23GB,十年只增长了3倍。
而这部分升级缓慢直接影响了营收,size容量计价是赚钱的主要方式,速度的提高只是技术升级,提高size的单价,这两个的升级需求都不大,需求主要是随着电脑/手机数量增长而增长
所以DRAM在带宽速度和容量这两个维度上,一直是都是芯片产业锦上添花性质的附属品,DDR升级带来的边际效用是很低的,跟CPU时代的最高KPI几乎没什么直接联系
--------------------------------------------
而到了genAI 大模型为主导的新时代,计算范式转移让最高级KPI起了根本变化
GPU发展到AI推理的时代,不再像CPU那样只看跑分,最高级的KPI不再是算力TOPS/FLOPS,而是token的成本,特别是单位成本/单位电力下的overall token throuput
其次是token吞吐速度,因为在agent时代,很多任务变成了串行,token吞吐速度成了用户体验的重要瓶颈。
这也是为什么老黄发明AI工厂概念的原因:最低成本的输出最多token,同时尽量提高token吞吐速度
AI训练时代,老黄的经济学是TCO(total cost ownership),买的GPU越多,省的越多
而老黄在推理时代的token经济学是:
AI推理的毛利润很可观,所以逻辑已经转换成:Nvidia GPU是这个世界上让token单价最便宜的GPU,买的GPU越多,赚的越多
最高的KPI变成了Pareto frontier曲线,在提高token 吞吐throughput和提高token速度两个维度上尽量优化
(见图一)
NVIDIA 的 token factory 代际进步,其实是在把整条 Pareto frontier 往右上推,这就是是AI推理这个时代最重要的KPI
----------------------------------
接下来是本文最重要的逻辑链,如何从token吞吐量指数型增长的本质出发,推导出天花板瓶颈在HBM size和HBM 带宽的指数型增长
单卡GPU推理单线程batch size = 1的时代,token吞吐只有一个维度,就是HBM的带宽速度,带宽速度越高,token吞吐越大
但进入NVL72的年代,推理不再是单卡GPU时代,而是72个GPU + 36个CPU整个系统级别的token工厂,把HBM带宽和算力用满,获得极致的token吞吐量
Token 吞吐throughput的增长,依赖两个东西:同时批处理的请求数 X 每个user请求的平均token速度
也就是batch size X per user token 速度
以Rubin NVL72为例,在平均token速度是100 token/s的情况下,同时批处理1920个请求,得到token吞吐量是19.2万token/s 一个Rubin NVL72大概是120KW(0.12MW)的功率,所以得到单位MW能处理1.6M token/s
(见图一)
所以,我们需要想方设法提高这两个参数:批处理数量batch size和per user token的平均速度,这两者相乘就是我们的最高KPI,也就是token的吞吐量
-------
第一个参数:batch size的增长,瓶颈在HBM size
批处理量里的每一个请求req,都会自带kv cache,这部分kv cache是需要存在HBM里的,大小大概在几个GB到数十GB不等 因为hot kv cache是随时需要高频高速读取,所以必须放在HBM里,比如一个大模型的层数是80层,那么每一个token的生成阶段,都需要读取80次HBM里的kv cache
随着批处理数量batch size的增长,会带来hot kv cache的线性增长
又因为这个批处理量的所有请求的hot kv cache,都要放在HBM上,这也就带来了HBM size必须要随着批处理量batch size线性增长
就像是机场接驳车,登机口尽量快的接旅客到飞机,HBM size小了,相当于接驳车size小了,就得多接一趟
结论是:批处理量的数量batch size,瓶颈依赖于HBM size的增长
---------
第二个参数:每个user请求的平均token速度,瓶颈在HBM带宽
大模型decode阶段的速度,瓶颈取决于HBM的带宽速度,因为每生成一个 token,都要把激活的权重和kv cache 读很多遍
LPU的出现,在batch不那么大的情况下,把激活权重这个部分搬到了SRAM上,但是每生成一个 token仍然要从HBM读很多次KV cache。HBM带宽越高,生成每一个token的速度也就越快,基本上是线性对应的
就像是机场接驳车,登机口尽量快的接旅客到飞机,hbm本身带宽速度就像是接驳车的车门有多宽,门越宽,旅客上接驳车越快
GPU的其他配置,都是在适配batch的增长以及要让token compute的速度配平HBM的增长,甚至会用多余的算力来获得部分的带宽(比如部分带宽压缩技术)
—-----
在那个接驳车的比喻例子里
接驳车的车厢大小 = HBM Size(容量): 决定了一次能装下多少名旅客(也就是能同时装下多少个请求的 KV Cache)。车厢越大,一次能拉载的旅客(Batch Size)就越多。如果车太小,想拉100个人就得分两趟,系统整体的吞吐量就上不去。
接驳车的车门宽度 = HBM Bandwidth(带宽): 决定了旅客上下车的速度。门越宽,大家呼啦啦一下全上去了(Decode/生成Token的速度极快)。如果门很窄,哪怕车厢巨大能装200人,大家也得排着队一个一个挤上去,全耗在上下车的时间里了。
旅客的吞吐量 = 接驳车车厢容量 x 接驳车旅客上车速度(车门宽度)
—---------------------------
至此,我们从逻辑上推演出了token经济学的硬件需求第一性原理:
Token throughput = HBM size X HBM Bandwidth
AI推理这个时代的最高KPI,实际上是高度依赖于HBM的两个维度的进步的
如果要维持token throuput每一代两倍的增长,实际上意味着,每一代的单GPU上,HBM size X HBM BW带宽之积要增长两倍!
这也是历史上第一次,HBM内存的size可以影响最高的KPI token throughput!
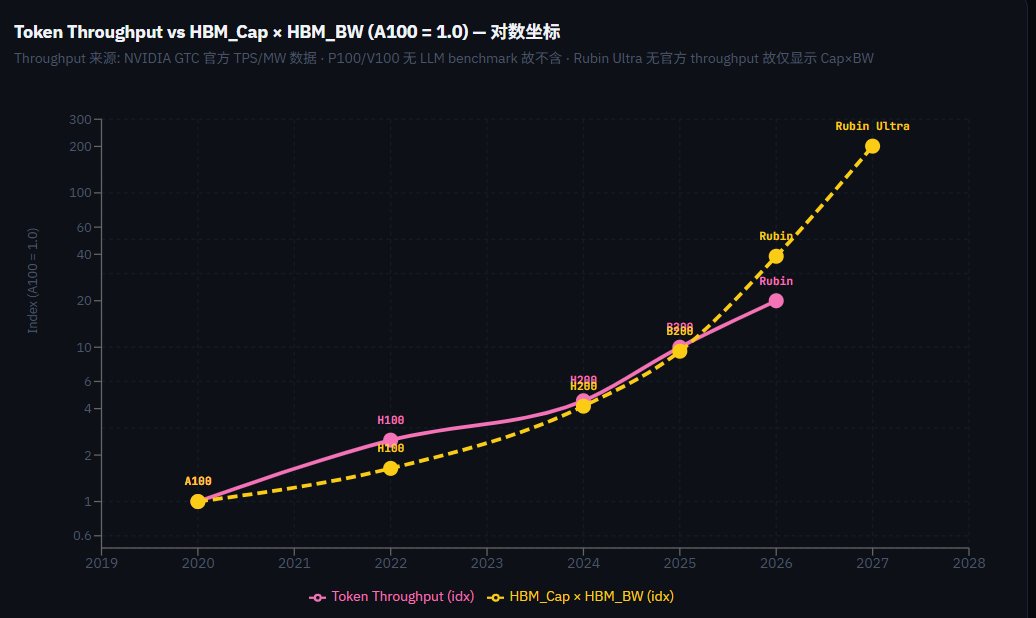
要验证这个理论,可以把Nvidia从A100到Rubin Ultra这几代的token 吞吐throughput,和HBM size X HBM BW 放在同一个图里比较
(见图二)
可以发现,这两个曲线的走势在对数轴上惊人的一致
HBM size x HBM带宽增长的甚至要比token吞吐量更快,毕竟HBM决定的是天花板,实际上这个天花板增长的利用率utilization是很难达到100%的,也就是说,HBM size x HBM 带宽就算增长1000倍,其他算力和架构的配合下,很难把这1000倍的天花板潜力全部榨干
这条曲线不是巧合,而是系统最优化的必然解
throughput = batch × Bandwidth,这就是token factory 经济学最绕不开的第一性原理
—--------
软件的影响呢?软件的优化会不会降低带宽的需求?降低HBM的需求?
这跟硬件是独立两个维度的,这好像在问,如果CPU上的软件优化了之后跑的更快,是不是CPU就十年不用发展了?反正软件跑的更快了嘛
这样的话,CPU厂还能赚得到钱吗?CPU想要存活下去,只有一条路可走,在标准benchmark,不考虑软件优化,每一代CPU必须要跑分更高,不然就卖不出去
GPU也是一样,软件优化如何,和自己的token吞吐量KPI每年都要大幅进步,是两回事
只要token的需求继续增长,对token throuput的追求就绝不会停止,那么对HBM size X HBM 带宽的追求也不会停止
如果HBM size和HBM 带宽发展慢了,老黄一定会亲自到御三家逼着他们技术升级,因为这就是老黄gpu的天花板,天花板要是钉死了不进步,老黄的GPU还能卖出去吗?
当然了,Nvidia需要绞尽脑汁去从异构计算的架构角度榨取HBM天花板之外的部分,比如LPU就是一个很好的尝试,把Pareto frontier从另一个角度改善了很多 (右半边高token速度的部分)
—--------------------------------------
HBM内存已然告别了那个随波逐流的旧时代,在这条由指数级需求铺就的单行道上,以一种近乎宿命的方式走到了产业史诗的主舞台中央
推理范式第一性原理演化到这一步,只要老黄还要卖GPU,HBM就必须翻倍,而且必须代代翻倍。这是supply side的内生压力,与AI需求无关,与宏观周期无关,与hyperscaler的心情也无关
剩下的问题,只有一个:
当需求被物理锁定为指数增长的时候,供给侧的三个玩家,会不会还像过去三十年那样,亲手把自己再拖回一次周期的泥潭?

fin@fi56622380
回顾2025年半导体市场,真的是有太多太多精彩的故事,最大的主题就是: AI需求驱动导致半导体基建的估值体系重构 + 产业链的价值分配重写 从2024年开始,半导体基建正在飞速吞噬整个IT产业利润,SP500里半导体净利润EPS在IT行业里占比,在两年时间从不到20%上升了到了40%,而且还在呈加速上升姿态 半导体整体前瞻利润率从2023年的25%已经升到了2025年11月的43%,已经明显超过了几个互联网巨头的平均利润率,这也印证了半导体利润率超过互联网会是新常态。整个IT产业的利润分配,流向半导体的比例越来越大。 要知道,就算是20~22年的半导体芯片荒,短缺如此严重,半导体的利润率和整个IT利润分配也没有显著增长 这就是故事的上半篇:AI需求驱动导致半导体基建的估值体系重构,不再是互联网时期的基建从属地位 ------------------------ 这个现象背后的逻辑是商业模式随着技术特性的变迁: 互联网时代,每次请求的网络和算力成本,边际成本极低,scaling的效果极好,分发的边际成本几乎为零 在AI时代,这个互联网时代分发边际成本几乎为零利于scalable的特性遭遇了根本性的重大挑战:且不说训练成本从此不是一次性开销而是年年增长,就客户的AI推理请求而言,由于inference scaling成为共识,加上垂直领域仍然需要更大规模的旗舰模型来保持竞争力,推理的成本不会随着硬件算力价格的通缩而同步降低 互联网企业从前的最大成本只有OPEX尤其是SDE人工成本,而现在,互联网公司历史上第一次像半导体厂foundry那样背上高折旧成本的资产负债表,商业模型恨不得要慢慢从“流量 × 转化率”部分转向“每 token 毛利”了 简单的说,互联网时代到AI时代的成本分布,在人力成本opex的基础上又加上了沉重的硬件/算力成本capex(财报里占比:MSFT 33%, Meta 38%)。 上个时代的互联网公司+CSP+SAAS是收租行业里的大赢家,而AI时代,算力(半导体/芯片折旧)成为了新的收租行业,整个IT行业的利润分布发生了剧烈的重新分配(EPS利润流向半导体从20%升到40%而且持续攀升中),这就是半导体基建估值体系重构最重要的原因 --------------- 半导体高利润率的新常态趋势能持续多久? 目前的高溢价来自于前期不计成本的军备竞赛造成的半导体订单积压过多 但很显然,hyperscalers都不愿意当冤大头,都在试图自建ASIC降低成本,那么可以从2030年远期的算力分布来回看这个问题 长线来看,openai已经明牌了标准答案,10GW Nvidia,10GW ASIC,6GW AMD,其他hyperscaler划分比例有类似考虑 比如说,推理端希望ASIC >50%,GPU里再细分的话,AMD和NV(legacy)对半分。训练还是得NV占大头,60%+,剩下的自研ASIC和AMD对半分 2030年按60%推理,40%训练比例划分,算下来NV 38%, ASIC 39%, AMD 23%,跟openAI比例是几乎完全一致的,算是一个标准答案参考值 当然了,微软,Amazon,Google,Anthropic这几家里AMD的比例会比这个标准答案中枢/参考值明显低一些,xAI则是没有ASIC只有Nvidia+少量AMD AMD的风险在于,当2030年再往后的更长期,CSP的in house ASIC越来越成熟(微软除外),推理端ASIC占比可能越来越高,很难有incentive新买入大量GPU了,除非卖的足够便宜 最近风头正劲的TPU呢?Meta是不是要转向TPU?对Nvidia的利润率影响大吗? 实际上,Meta今年capex72B,明年capex110B,未来六年capex平均值可能达到160B附近,而Meta 6年10B的TPU订单算下来年均只有1.6B,而且购买的是TPU云服务,并不是裸TPU 也就是说,Meta这笔TPU订单只占到Meta未来6年capex的1%,并没有严肃的考虑大规模部署,可能只是作为和Nvidia讨价还价的手段而已 另外从Meta最近几个月的招聘广告来看,也并没有看到任何TPU engineer方面的招聘,不像 Anthropic那样从五月就招一堆TPU kernel engineer,十月才宣布大规模采购TPU做训练 所以说,不管原因是diversify供货商,还是给自研ASIC延迟做退路,还是因为AMD的MI350X延迟,Meta买TPU基本上只有一个考虑:增加买Nvidia GPU的议价权,但顶多只有推理份额里能讨价还价,实际效果很有限,对Nvidia利润率影响也很有限。 要知道,22年加密货币熊市矿难的时候,NVDA库存上升到了198天,利润率只是从65%回撤到了56%,算上PE/宏观双杀股价才从300变100,现在一直供不应求,利润率没道理能降下来 再加上TPU v8设计过于保守(没用HBM4),Kyber rack的Rubin方案会比TPU v8的TCO更好,到头来最后还是得继续依赖Nvidia,很难议价。只要Nvidia继续保持这样的大踏步前进,竞争对手其实要跟上还是不容易的。 总之,一方面,全产业链瓶颈,比如cowos扩张都很谨慎,供不应求的状态还能持续多年。 另一方面,AI变现的利润曲线和硬件投入曲线存在“时间错配”,应用端的增长曲线会落后几年,只要这个应用端和基建端的增长曲线的时间错位依旧存在,半导体在IT行业的利润分配就会一直占优势。 从OpenAI的到2030年的投入曲线来看,这个时间错位至少要持续到2030年附近。也就是说半导体行业的超级扩张期带来的在IT产业利润划分的主导地位,目前看至少能持续到2030年 而半导体高利润率可能会维持的更长远一些,因为从互联网时代一次性基建属性变成了现在的收租基建属性 --------------------------------------------------- AI 不是只养活了 GPU,而是在用算力预算把“能把电变成 token 的每一环”都抬了一轮,从内存,存储,互联,光纤,电力,储能…..等等 上半篇讲完了“半导体吞噬IT利润”,那么下半篇讲的就是“AI算力价值溢出效应(Spillover Effect)重塑半导体内部格局”:GPU算力增长 -> 内存/存储/互联/CPU瓶颈 -> 溢出效应 -> 结构性机会 2025 年更有趣的故事,是巨大的行业红利在半导体内部怎么诞生结构性新机会,比如说,一个super cluster需要几个数据中心互联,光纤互联的长度需要上百万mile这个级别,这就是新机会 半导体产业链的结构性趋势带来的新机会,最典型的例子就是内存(DRAM/HBM)和存储(SSD),HBM的需求增长太夸张,连带挤压DDR4/5产能,直接让以周期性为标志的内存行业甚至喊出了“周期不存在”了,Hynix因为在HBM上领先,甚至都开始憧憬起了几年后年利润1000亿美元,妥妥一个万亿市值的公司 这两个板块背后,是结构性趋势的转变:AI workload从训练逐渐往推理延申,推理比例越来越大。 而推理是一个非常纯粹的吃内存带宽速度(memory bound)的事情,可以说带宽速度=token/s。模型尺寸越来越大,以及上下文context length的增加,对内存的尺寸要求也相应增大,导致了内存的需求激增:推理即内存 下一代的的GPU/ASIC内存已经成了暴力美学,配备的内存size之巨大,是三年前无法想象的,回看22年H100的80GB简直像个玩具,这才几年就增长了十倍: Nvidia Ultra Rubin - 1024GB HBM Qualcomm AI200 - 768GB LPDDR AMD MI400x - 432GB HBM 内存的另外一个潜在的爆发点在端侧,也就是手机/PC/汽车/机器人的端侧LLM,这两年主流的手机旗舰机已经从6GB升级到了8GB/12GB/16GB,提前为可能的端侧LLM生态做准备,毕竟手机算力下一代就能达到150TOPS量级,妥妥的桌面级,非常暴力 潜力上来说,端侧内存升级是比云端内存增量要更大的市场,毕竟端侧终端device的数量太惊人了,每年都是billion级别,一旦端侧LLM生态繁荣起来,内存用量翻倍轻而易举,针对端侧低功耗内存/存算一体的各种设计都会跟上 但端侧genAI的软件生态,似乎明显滞后,一直比我想象的进度要慢,可能是因为这方面还处于摸索期,并没有云端那么确定的ROI,厂商们在投入上都很谨慎,我在23~24年时候看好27年,可能还是太乐观了 互联网->移动互联网用了10~15年,端侧genAI/LLM可能也需要7~10年,可能得等云端ROI开发的差不多了,边际收益下降了,才能轮得到端侧genAI/LLM拿到开发资源,跑通端侧ROI。 -------------------------------------- 另一个2025年半导体内部结构性转变的故事是NAND存储,特别是企业级eSSD硬盘 结构性趋势来源也是同一个,AI workload的推理需求越来越大。内存红利也外溢到了SSD存储,甚至HDD存储,因为内存不够用就用高速SSD作为多级缓存 主要逻辑是AI推理过程中内存溢出KV cache offloading到下一层SSD存储,以及向量数据库检索/indexing,都在增加SSD存储的需求 Micron财报说的精准又直白:“AI inference use cases such as KV cache tiering and vector database search and indexing, are driving demand for performance storage.” 至于为什么存储价格在第四季度才爆发,这需要区分一下合约价格和现货价格,合约价格涨幅会温和一些,就算是最紧缺的企业级eSSD合约Q4上涨大概25%。而当NAND产能在2025年被合约慢慢的吃光,现货的价格就造成了观感上强烈的冲击,一个月上涨50%以上。 另一个未经验证的逻辑是多模态的爆发,特别是AI图片和AI视频的需求爆发,也会加剧存储的短缺,我觉得这条线只能说未来可期,但目前的视频/图片精细程度,可能还不到当年GPT3的水平,要达到出圈效果还需要一些时日。 ------------------------ 那么下一步还有什么趋势转移带来的半导体结构性的机会呢 那么就要先看下一步AI推理端的需求趋势是什么,毫无疑问,agentic flow的比例会越来越大,2025并不是year of agent,而是一个decade of agent 从CPU视角去看agentic workload,routing和工具处理都在CPU上,如果把常用的agentic框架做profiling,比如SWE-Agent, LangChain, Toolformer,CPU最长可以占到90%的E2E端到端延迟,throughput瓶颈也更多的卡在CPU,甚至CPU能耗也超过了总能耗的40% Agentic AI目前是一个CPU瓶颈更多的事情,在 agentic 框架里,CPU 是永远在忙的总指挥orchestrator, 很可能会成就CPU需求的新一波回暖 AMD 2025年Q2财报(8月5日),Lisa Su明确表述了这一现象:"In particular, adoption of agentic AI is creating additional demand for general-purpose compute infrastructure, as customers quickly realize that each token generated by a GPU triggers multiple CPU-intensive tasks." "agent AI的采用正在对通用计算基础架构产生额外的需求,因为客户很快就意识到GPU产生的每个令牌都会触发多个CPU密集型任务。" Q3 财报里Lisa又明牌了一次CPU TAM increasing due to Gen AI. "Many customers are now planning substantially larger CPU build outs over the coming quarters to support increased demands from AI, serving as a powerful new catalyst for our server business." Nvidia也是把agent flow视为CPU需求,GB200/300 架构配置的CPU比例也比以往大的多,36颗 Grace CPU : 72颗 Blackwell GPU,直接达到了1:2的水平,AMD的路线则是用1~4个256核的EPYC去服务MI400系列72~128个GPU 以后的硬件架构,一定会往优化agent workload方向发展,比如agent task graph的调度和load balancing,CPU/GPU协同micro-batching 算力上的比较,说不定以后也会摆脱现在的纯GPU token rate比较,转向整个系统级全栈agentic benchmark比较. -------------------------- 半导体结构性转变带来的机会同时,下一步,可能也会带来一些意想不到的次生效应 云端AI数据中心需求爆发,造成内存和存储的暴涨,给消费电子的成本带来了很大压力,在2026年,这也许会演变成消费电子产业潜在的黑天鹅 PC厂商最近的股票大跌,也是这个原因。HP已经说了要减少内存配置,暗示要把PC重回8GB内存+256GB存储的时代了。 DRAM内存和存储再这么涨下去,可能会出现很离谱的情况:内存/存储现货价格比CPU和GPU还要更贵。尴尬的是,这可能直接延缓了消费电子期望的AI PC的进程,毕竟大内存是更有利AI PC的表现力的。 夸张的说,每个PC厂商和手机厂商的员工,甚至是消费电子厂商的员工,都应该买入存储和内存,作为职业风险对冲 明年年初开始,安卓阵营的内存以及存储成本要压不住了,三星,小米的手机售价都提高的话(美国市场现在已经提高不少了),利好最大的就是苹果 苹果的内存产能,nand产能都是专属长约锁价特供的,顺带还把Kioxia给坑了好多不涨价产能,导致苹果的成本优势进一步扩大,苹果全球手机销量市占率增长可能会非常可观,接下来一阵子可能会是iphone辉煌的时光。 ----------------------- 2025年半导体市场真的是太多精彩的故事了,Nvidia/AMD/TPU和各家hyperscaler的恩怨情仇引得各路下注的吃瓜群众心情跌宕起伏。 HBM/内存厂商吃到了memory-bound的红利,NAND厂商意外收获了KV cache的溢出效应,CPU在沉寂近十年后,可能会因agent orchestration再次回到增长叙事的中心 不再是Nvidia/AVGO几家算力厂商独大,而是AI workload算力价值溢出后的每一次演进,从训练到推理,从文本到多模态,从单模型调用到agentic flow,都在重写产业链的价值分配。 云端AI的繁荣正在挤压消费电子的生存空间——当PC厂商被迫讨论重回8GB时代,苹果却因供应链优势坐收渔利。这场算力军备竞赛的次生效应,可能在2026年以意想不到的方式重塑整个消费电子格局 半导体的故事不再是一条单线,而是一张持续自我重构的网。而 2025 年,大概只是合纵连横的第一回合
中文
Today I went to a nationwide chain tutoring center, Sylvyn Learning, in San Jose to enroll my child. Before leaving, I casually asked which schools most of the students there come from. That opened the floodgates. The manager gave me a glimpse of just how intense the competition is for kids in the Bay Area.
He said the largest group of students there comes from the well-known Harker School. These students are not there because they are struggling academically, but because the competition within the school is extremely fierce. Starting from TK, Harker places students into three tiers. Even the lowest tier is about one year ahead of public school pace, while the highest tier is ahead by as much as three years. Many students attend tutoring in order to move into the top tier.
The youngest student currently enrolled is a TK child who will be starting at Harker this fall. The parents enrolled the child early to gain a head start. The manager also mentioned that at most other locations, this tutoring chain mainly serves students who are below the national average. The Bay Area is an exception.
English


Since we’re sharing Jane Street interview stories, here’s mine from 2009 when Jane Street NYC was <200 people. Final round was a gauntlet of math/stats theory interviews, back to back for hours with different interviewers.
My favorite: “1000 ninjas are standing in a circle, each holding a sword. #1 kills #2, #3 kills #4, and so on. It keeps going around and around until one ninja is left standing. Which ninja is it?”
I love it because the problem is so easy to understand, and it rewards a beautiful progression — you start with brute force to build intuition, spot the pattern, then derive a clean theory that solves it for any arbitrary N. It’s a beautiful distillation.
Deedy@deedydas
Jane Street made ~$40B in 2025 with 3,500 employees, a ~2x from the year before. At ~65-70% profit margin, that's $8M profit / employee, the highest for a 1000+ ppl company. High-frequency trading continues to be the most efficient money making engine. I want to share an old story about my Jane Street interview in 2014. Jane Street was known for hiring a lot of math, physics and CS olympiad winners from top universities and putting them through many rounds - including, for trading roles, a gauntlet of mental math. It was my 6th interview and my final round and I recall being asked "What is the next day after today in DD/MM/YYYY where all the digits are unique?" They'd toy with you and say "You can use a pencil and paper, if you want" but you knew that was an instant no. Painstakingly and as quickly as I could, I came to an answer. "How confident are you that this is correct on a 0-1 probability scale?" the interviewer said. "0.95", I blurted out, not fully knowing how to answer that. "Are you sure?" After thinking harder for a few more seconds, I realized I could've flipped the digits around to get a closer date. I gave the interviewer my answer. It was correct. "0.95 huh?" he chuckled. That's when I knew I failed. Note: fwiw, other companies that come close in efficiency are - Tether ($90M+ profit/emp) - Hyperliquid ($80M+ profit/emp) and on revenue: - Valve ($50M/emp) - OnlyFans ($37M/emp) - Craigslist ($14M/emp) - Anthropic ($12M/emp, run rate) - OpenAI ($8M/emp, run rate) For comparison, Nvidia is very efficient at scale and is $4.4M/emp.
English
My five-year-old didn’t want to put on a jacket this morning. I told him it would rain. He came up with his own theory and claimed that since it rained yesterday, it wouldn’t rain today. I told him that’s not how it works. Afterwards, I realized it’s actually the opposite. The probabilities of rain on two consecutive days at the same location should be highly positively correlated.
English
That’s where the math starts to change. Going from $15b to $30b is a completely different challenge than going from $1b to $2b. The base is bigger, expectations are higher, and execution has to be very good.
At around a ~$90b market cap, the setup starts to look more balanced to me. You’re no longer paying peak optimism for a perfectly clean narrative. You’re paying for a great business that is starting to show a few cracks. Historically, that’s where opportunities tend to lie, not when everything looks perfect.
The business didn’t suddenly change overnight, and that’s an important distinction. What really changed is the price people are willing to pay for it. Markets don’t just reprice bad businesses, they reprice great businesses the moment the narrative changes even slightly.
This is also a Silicon Valley darling, and that comes with both advantages and trade offs. The talent, the positioning, and the reputation all matter hugely. But it also comes with heavy stock based compensation, which I take seriously and don’t ignore. You’re getting a world class business, but you’re also paying for it through dilution over time, albeit they are buying back shares at an accelerated pace to offset some of that pressure.
For me, this ultimately comes down to a simple question. Does $NOW remain a core system for enterprises in an AI driven world, or does it slowly lose relevance over time. If it remains essential, then what we’re seeing right now is likely just a reset in expectations, not a structural break. If that assumption proves wrong, then the story changes.
There are also clear things I’m watching closely from here. If sales cycles continue to stretch and conversion weakens further, that would matter. If margins don’t show a credible path back over time, that would matter as well. For now, I don’t think we’re there yet, but those are the lines I’m paying attention to.
I’ve seen this pattern before in other businesses that looked almost perfect for a long time. They don’t usually break all at once, but they do go through periods where things get a little less clean. That doesn’t mean the opportunity disappears, but it does mean expectations need to reset. That reset is often where the opportunity comes from.
At the end of the day, I still believe this is a company that can be worth hundreds of billions of dollars over time. The combination of scale, deep enterprise integration, and the ability to expand across workflows is extremely powerful if they continue to execute. This is not a business that needs to reinvent itself, it just needs to stay disciplined and keep doing what it has already proven it can do. If it remains a core system for enterprises and continues to compound at a high rate, the outcome can be much larger than what the market is pricing in today.
The path is not guaranteed, and that’s what creates the opportunity. Expectations have come down slightly, the story is a bit less clean, and that’s exactly when these types of businesses become interesting. If they can work through the current friction and regain consistency over time, the narrative can shift again just as quickly as it changed.
These are my thoughts on the quarter, the business, and my investment in $NOW. It may be a bit lengthy, but like I said at the beginning, I don’t like leaving things unfinished and I wanted to put all the cards face up on the table since I already unlocked Pandora’s box. If you found it useful or interesting, I’d appreciate a like, comment, share, or follow.
🌹
3/end
English
Final thoughts on $NOW
This whole situation around $NOW was a lot to say the least. I posted that I bought it, got hit with a tsunami of toxicity, and honestly it left a bad taste in my mouth. Enough where I said I’d probably never share a buy or sell again.
But then something else happened that I didn’t expect. A lot of people showed up, left thoughtful comments, and asked good questions. The kind of questions that make you stop and think instead of react. And I realized I kind of left those people hanging.
If there’s one thing about me, I don’t like leaving things unfinished. Especially when it’s something I put out there myself and people took the time to engage with. Most people react and move on, but very few go back and actually do the work. So I decided to go back and really think this through properly. I reread the conference call multiple times, slowly and carefully, without distractions (perhaps that’s one of the few positives of being in the hospital).
The easiest takeaway from the Q1 call is that nothing is broken at $NOW. Revenue is still growing above 20%, enterprise demand is still strong, and large customers are still signing large deals. On the surface, it looks like the same high quality business people have been used to owning. But when you slow down and really listen, the story starts to change in a subtle way.
The first thing that stood out to me is not the level of growth, but the direction of it. A business growing 20% sounds strong, but what matters is whether that growth is accelerating, stable, or starting to slow. What we’re seeing here feels more like stabilization with early signs of deceleration. That may sound small, but when expectations are high, small changes matter a lot.
Management says that some large deals slipped rather than disappeared, particularly in the Middle East due to the war. That explanation is completely reasonable on its own because timing issues happen all the time in enterprise sales. The issue is when that explanation appears more than once. That’s usually when it points to something deeper underneath the surface.
It often means sales cycles are getting longer and budgets are getting tighter. The demand is still there, but it’s harder to convert into actual sales. When deals take longer to close, the pipeline can still look strong, but conversion becomes uneven. That is exactly what this quarter hinted at and that’s the kind of thing markets react to quickly.
That’s what I would call friction, not weakness. The business isn’t breaking, but it’s not flowing as easily as it used to. And over time, that friction always finds its way into the numbers. It doesn’t show up all at once, but it builds gradually.
Another piece that deserves more attention is how AI is changing the business. Management is right that AI is a tailwind because it’s clearly driving demand and expanding use cases. But at the same time, it’s priced on a usage based instead of fixed recurring subscriptions like $NFLX. That changes the nature of the business because usage based pricing makes revenue less predictable and harder to forecast.
You get more upside in strong environments, but you lose some visibility. Investors historically paid a premium for $NOW because it felt almost automatic in how it grew. When that predictability starts to fade, the multiple compresses.
Margins are another area where the explanation sounds simple,
but the implications are more complex. $NOW says the Armis acquisition is the reason margins will be pressured in the near term. They should recover but not until 2027, which is further out than investors expected. That tells us something important about the level of investment happening.
1/
Rose Celine Investments 🌹@realroseceline
I’ll be honest, I didn’t sleep last night and I’m a bit irritable. I shared my $NOW buy because people keep asking what I’m buying or selling, and I wanted to oblige, not because I’m looking to debate or defend it. I’m not here to justify my thinking or argue over PE, SBC, EPS, FCF, GAAP or non GAAP, or whatever angle you want to take. I’ve been doing this for almost 20 years and I’m more than comfortable making decisions on my own. Investing isn’t a group activity. If your conviction depends on consensus or justification, you don’t have conviction, you have a vote. Markets don’t pay you for agreeing with the crowd, they pay you for being right when the crowd is wrong. Everyone wants to argue about a multiple or a quarter or whatever, but very few people actually think through a business over 5 to 10 years. Look at your own behavior. How many stocks have you held for a decade? What does your transaction history in your brokerage actually look like? Nothing against discussion, it’s just not how I invest. When I share a buy or sell, it’s simply that, sharing. Not an invitation to debate, convince, or relitigate the work I’ve already done. Going forward, I won’t be sharing my trades publicly. Not because I have anything to hide, but because this experience left a sour taste in my mouth. 🌹
English
@CatChen @stuart983 当然不能保证突破,统计上看有足够比例突破就行。我没有数据,但是rags to rices这样的故事很多,富人没落的例子也很多。
中文

@hzhu_ @stuart983 如果一个人的基因和家境都不行,那赚钱能力也不一定能培养起来啊,这依旧无法突破啊。这研究反而给 generational wealth 提供了有力的支撑,只要家境能够维持下去,每一代随机开盲盒不是问题,都不会差到哪里去。
中文
最新的研究显示,富裕家庭的孩子鸡娃的效果主要体现在给娃补足弱项上,而不是环境让他们发挥出基因优势。 siyingd.blogspot.com/2026/04/blog-p…
中文