
Ila Orangun
952 posts


New Book & Video Series!!! (late 2025)
Optimization Bootcamp: Applications in Machine Learning, Control, and Inverse Problems
Comment for a sneak peak to help proofread and I'll DM
(proof reading, typos, HW problems, all get acknowledgment in book!)
English
Ila Orangun retweetledi

When I embarked on self learning & research journey in computer vision I was one of the top engineering students at the University of Zambia school of engineering.
I broke records in terms of academic performance.
But a series of events eventually led me down the lonewolf path.
English
Ila Orangun retweetledi

I often see developers make mistakes in their tutorials that trip up readers, so I thought a lot about what makes some tutorials effective and what makes others frustrating. refactoringenglish.com/chapters/rules…
English
Ila Orangun retweetledi

This YouTube video by @welchlabs is a very approachable, concise explanation of LLM mechanistic interpretability and sparse autoencoders (SAEs).
I highly recommend checking it out!

English
Ila Orangun retweetledi

Let's try this: I'll put some of the code for the slides of my course open-source. We'll see where it goes.
I was told you people like attention mechanisms.
fleuret.org/dlc/materials/…
github.com/francoisfleure…




English
Ila Orangun retweetledi

Ila Orangun retweetledi

We outperform Llama 70B with Llama 3B on hard math by scaling test-time compute 🔥
How? By combining step-wise reward models with tree search algorithms :)
We show that smol models can match or exceed the performance of their much larger siblings when given enough "time to think"
We're open sourcing the full recipe and sharing a detailed blog post 👇
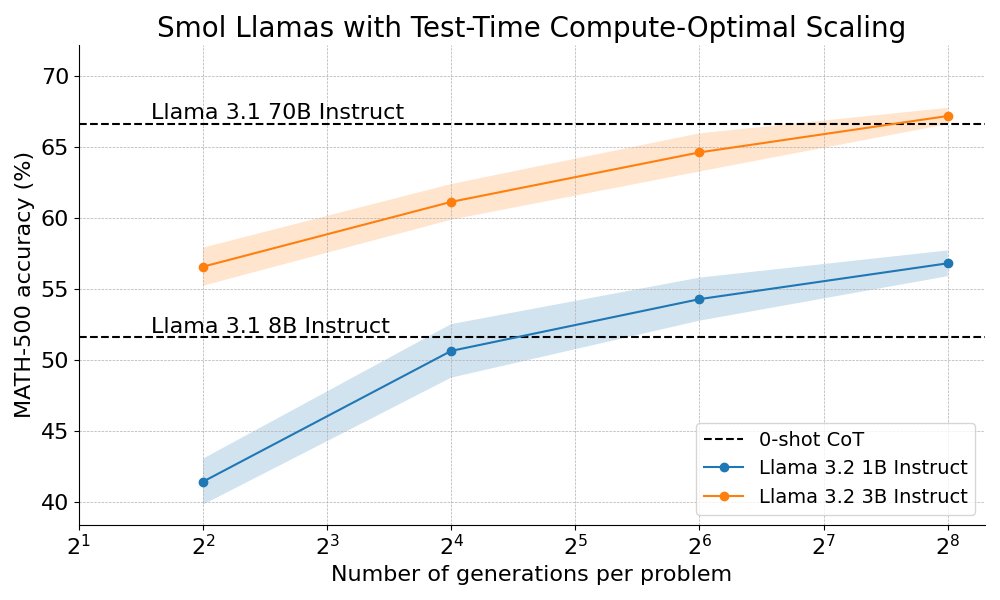
English
Ila Orangun retweetledi

News from our LiDAR project on Sungbo's Eredo. news.wm.edu/2024/12/05/lid…
English
Ila Orangun retweetledi
The inventors of flow matching have released a comprehensive guide going over the math & code of flow matching!
Also covers variants like non-Euclidean & discrete flow matching.
A PyTorch library is also released with this guide!
This looks like a very good read! 🔥

English
Ila Orangun retweetledi

New AI research from Meta – CoTracker3 Simpler and Better Point Tracking by Pseudo-Labelling Real Videos.
More details ➡️ go.fb.me/xiyc63
Demo on @huggingface ➡️ go.fb.me/yzuqd0
Building on our previous work on CoTracker, this new model demonstrates impressive tracking results where points can be tracked for a long time even when they're occluded or leave the field of view. CoTracker3 achieves state-of-the-art, outperforming all recent point tracking approaches on standard benchmarks — often by a substantial margin.
We've released the research paper, code and a demo on Hugging Face — along with models available under an A-NC license to support further research in this space.
English
Ila Orangun retweetledi


Ila Orangun retweetledi

A joint statement by 34 UNIFIL-contributing countries, initiated by 🇵🇱, urges to protect @UNIFIL_ peacekeepers.
We condemn recent incidents, call to respect UNIFIL's mission & ensure the safety of its personnel.
🇦🇲🇦🇹🇧🇩🇧🇷🇰🇭🇨🇳🇨🇾🇸🇻🇪🇪🇫🇯🇫🇮🇫🇷🇬🇭🇬🇹🇭🇺🇮🇩🇮🇪🇮🇹🇰🇿🇰🇷🇱🇻🇲🇾🇲🇹🇲🇳🇳🇵🇳🇱🇵🇱🇶🇦🇸🇱🇪🇸🇱🇰🇹🇿🇹🇷🇬🇧

English
Ila Orangun retweetledi

Ila Orangun retweetledi

"How to train a model on 10k H100 GPUs?"
has now been immortalized on my blog: soumith.ch/blog/2024-10-0…
Soumith Chintala@soumithchintala
There's three parts. 1. Fitting as large of a network and as large of a batch-size as possible onto the 10k/100k/1m H100s -- parallelizing and using memory-saving tricks. 2. Communicating state between these GPUs as quickly as possible 3. Recovering from failures (hardware, software, etc.) as quickly as possible 1. Fitting as large of a network and as large of a batch-size as possible onto the 10k H100s. Parallelizing: 1. parallelize over batches 2. parallelize over layers (i.e. split a layer across GPUs) 3. parallelize across layers (i.e. 1 to N are on GPU1, N+1th layer to N+10th layer are on GPU2) Keep parallelizing until you are able to use all GPUs well, with maximum utilization. Checkpointing / Compute vs memorize: * You need to save certain terms from forward to compute the backprop (save_for_backward). However, if the network is sufficiently large, it is more profitable to free these terms in order to fit a larger batch-size, and recompute them again when you need them to compute the backprop. * Tricks like FSDP discard parts of weights that are held in one GPU (to save memory), and ask for the shards of weights from other GPUs right before they need them. 2. Communicating state between these GPUs as quickly as possible Communication overlap: When you need to communicate among GPUs, try to start communication as soon as you can: * Exampel: when Nth layer is done with backward, while N-1th layer is computing backward, all GPUs with an Nth layer can all-reduce their gradients) Discover and leverage the underlying networking topology: Communicating large amounts of state (gradients, optimizer state) across multiple nodes is complicated. with Sync SGD, you have to communicate this state in a burst, as quickly as you can. we might have multiple layers of switches, and have RDMA (ability to copy GPU memory directly to NIC, bypassing CPU ram entirely), and have frontend and backend NICs (frontend connects to storage like NFS, backend connects GPUs to other GPUs in cluster). So, it's important to leverage all this info when running communication collectives like all-reduce or scatter/gather. All-reduce for example can be done algorithmically in log(n) if you tree-reduce; and the constant factors that change based on the type of fiber connecting one node to another in the tree of networking fiber is important to reduce overall time and latency. Libraries like NCCL do sophisticated discovery of the underlying networking topology and leverage them when we run all-reduce and other collectives. 3. Recovering from failures (hardware, software, etc.) as quickly as possible At 10k GPU scale, things fail all the time -- GPUs, NICs, cables, etc. Some of these failures are easy to detect quickly, some of them you can only detect because one node isn't replying back in time (say a NCCL all-reduce is stuck). We build various tools to monitor and detect fleet health, and remove failed nodes from the fleet as quickly as possible. This is quite hard. Separately, at this large of a scale you can have silent data corruptions from memory bits flipping randomly (due to basic physics and amplifying the probability at this scale), and you suddenly have loss-explosions for no reason other than this random phenomenon. These happen at small-scale too, but very very infrequently so you barely notice. This is very hard to detect before-hand in software. Some hardware has hardware circuitry that does built-in checksums after it computes things -- this way if bit-flips occur the hardware can throw an interrupt. H100s and previous NVIDIA GPUs don't have this feature. To counter all these failures, you would want to save your model state as frequently and as quickly as you can; and when a failure occurs, you want to recover and continue as quickly as you can. Usually, we save model state really quickly to CPU memory in a separate thread and in the background we save from CPU memory to disk or remote storage. We also save model state in shards (this is torch.distributed's checkpointing feature), i.e. not every GPU needs to save all of the model weights; each GPU only needs to save a portion of weights -- and they can recover the other part of weights from other GPU shard checkpoints.
English
Ila Orangun retweetledi

SAM & SAM-2 are great but depend on costly annotations.
Can we 'segment anything' without supervision?🤔
Yes! Check out UnSAM @NeurIPS24—an unsupervised segmenter that achieves SAM-level results! 🎉
Even better—UnSAM+ beats SAM with +6.7% AR & +3.9% AP, using just 1% labels!💪
GIF
English
Ila Orangun retweetledi

Ila Orangun retweetledi

Try out our latest coding challenge! This repo includes a GPT model that simulates a realistic steering response of an openpilot-compatible car. Can you make a good controller to make it follow the desired trajectory?
Prizes:
- $250 for solution with lowest total cost
- $250 for most interesting solution (RL?)
Submit to vivek@comma.ai before 13th of May.
github.com/commaai/contro…
English
Ila Orangun retweetledi

Have you ever wanted to train LLMs in pure C without 245MB of PyTorch and 107MB of cPython? No? Well now you can! With llm.c:
github.com/karpathy/llm.c
To start, implements GPT-2 training on CPU/fp32 in only ~1,000 lines of clean code. It compiles and runs instantly, and exactly matches the PyTorch reference implementation.
I chose GPT-2 to start because it is the grand-daddy of LLMs, the first time the LLM stack was put together in a recognizably modern form, and with model weights available.
English
Ila Orangun retweetledi

The next chapter about transformers is up on YouTube, digging into the attention mechanism: youtu.be/eMlx5fFNoYc
The model works with vectors representing tokens (think words), and this is the mechanism that allows those vectors to take in meaning from context.
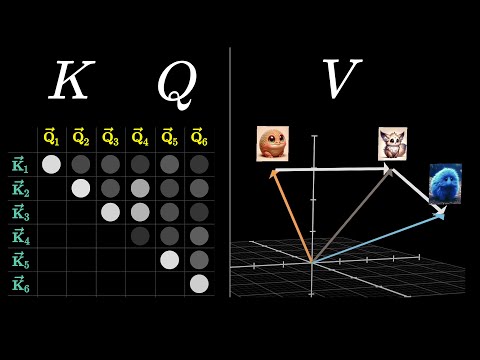
YouTube
English