Kailin retweetledi
Kailin
921 posts



Kailin retweetledi

we as software engineers are becoming beholden to a handful of well funded corportations. while they are our "friends" now, that may change due to incentives. i'm very uncomfortable with that.
i believe we need to band together as a community and create a public, free to use repository of real-world (coding) agent sessions/traces. I want small labs, startups, and tinkerers to have access to the same data the big folks currently gobble up from all of us. So we, as a community, can do what e.g. Cursor does below, and take back a little bit of control again.
Who's with me?
cursor.com/blog/real-time…
English
Kailin retweetledi



Kailin retweetledi
black hats having a field day w/ this kind of exploit surface. expect many more hacks in the headlines
elvis@omarsar0
NEW paper from Google DeepMind The biggest threat to AI agents isn't a smarter attacker. It's the web itself. This work introduces the first systematic framework for understanding how the open web can be weaponized against autonomous agents. The paper defines "AI Agent Traps": adversarial content embedded in web pages and digital resources, engineered specifically to exploit visiting agents. The taxonomy covers six attack classes targeting different parts of the agent architecture like perception (hidden instructions in HTML/CSS) and memory (RAG poisoning and latent memory corruption). The attack surface is no longer just the model. It is every web page, every retrieved document, every piece of content the agent ingests at inference time. Hidden prompt injections in HTML already partially commandeer agents in up to 86% of scenarios, and latent memory poisoning achieves 80%+ attack success with less than 0.1% data contamination. This paper maps where the defenses are weakest and where the research community needs to focus next. Paper: papers.ssrn.com/sol3/papers.cf… Learn to build effective AI agents in our academy: academy.dair.ai
English
Kailin retweetledi

Hermes Agent adapter with persistent memory and multi-provider support
github.com/NousResearch/h…
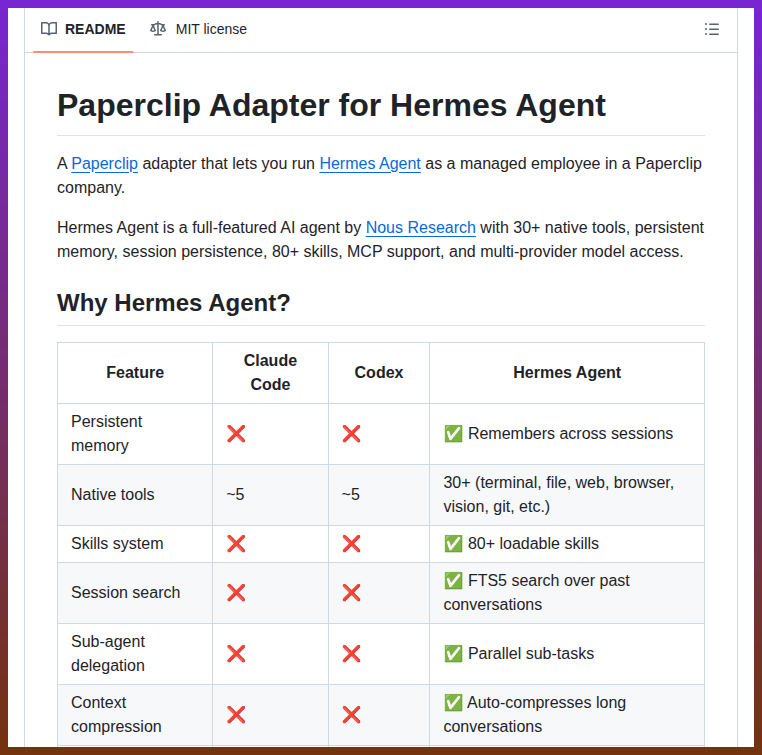
English

going to be in SF on Wednesday, who's up to chat about healthcare over the best ☕️ coffee?
English
Kailin retweetledi

Hyperagents: arxiv.org/abs/2603.19461
Code: github.com/facebookresear…
Huge thank you to everyone who discussed and gave feedback during this project, and to all collaborators Bingchen Zhao (@BingchenZhao), Wannan Yang (@winnieyangwn), Jakob Foerster (@j_foerst), Jeff Clune (@jeffclune), Minqi Jiang (@MinqiJiang), Sam Devlin (@MinqiJiang), Sam Devlin (@smdvln), and Tatiana Shavrina (@rybolos) for hosting me at Meta (@AIatMeta)!
English
Kailin retweetledi

Introducing the Agent Virtual Machine (AVM)
Think V8 for agents.
AI agents are currently running on your computer with no unified security, no resource limits, and no visibility into what data they're sending out. Every agent framework builds its own security model, its own sandboxing, its own permission system. You configure each one separately. You audit each one separately. You hope you didn't miss anything in any of them.
The AVM changes this.
It's a single runtime daemon (avmd) that sits between every agent framework and your operating system. Install it once, configure one policy file, and every agent on your machine runs inside it - regardless of which framework built it. The AVM enforces security (91-pattern injection scanner, tool/file/network ACLs, approval prompts), protects your privacy (classifies every outbound byte for PII, credentials, and financial data - blocks or alerts in real-time), and governs resources (you say "50% CPU, 4GB RAM" and the AVM fair-shares it across all agents, halting any that exceed their budget). One config. One audit command. One kill switch.
The architectural model is V8 for agents. Chrome, Node.js, and Deno are different products but they share V8 as their execution engine. Agent frameworks bring the UX. The AVM brings the trust. Where needed, AVM can also generate zero-knowledge proofs of agent execution via 25 purpose-built opcodes and 6 proof systems, providing the foundational pillar for the agent-to-agent economy.
AVM v0.1.0 - Changelog
- Security gate: 5-layer injection scanner with 91 compiled regex patterns. Every input and output scanned. Fail-closed - nothing passes without clearing the gate.
- Privacy layer: Classifies all outbound data for PII, credentials, and financial info (27 detection patterns + Luhn validation). Block, ask, warn, or allow per category. Tamper-evident hash-chained log of every egress event.
- Resource governor: User sets system-wide caps (CPU/memory/disk/network). AVM fair-shares across all agents. Gas budget per agent - when gas runs out, execution halts. No agent starves your machine.
- Sandbox execution: Real code execution in isolated process sandboxes (rlimits, env sanitization) or Docker containers (--cap-drop ALL, --network none, --read-only). AVM auto-selects the tier - agents never choose their own sandbox.
- Approval flow: Dangerous operations (file writes, shell commands, network requests) trigger interactive approval prompts. 5-minute timeout auto-denies. Every decision logged.
- CLI dashboard: hyperspace-avm top shows all running agents, resource usage, gas budgets, security events, and privacy stats in one live-updating screen.
- Node.js SDK: Zero-dependency hyperspace/avm package. AVM.tryConnect() for graceful fallback - if avmd isn't running, the agent framework uses its own execution path. OpenClaw adapter example included.
- One config for all agents: ~/.hyperspace/avm-policy.json governs every agent framework on your machine. One file. One audit. One kill switch.
English
Kailin retweetledi

If you're building anything in AI, the best skill you need to be using right now is hugging-face-paper-pages
Whatever problem you're facing, someone has probably already published a paper about it. HF's Papers API gives a hybrid semantic search over AI papers.
I wrote an internal skill, context-research, that orchestrates the HF Papers API into a research pipeline. It runs five parallel searches with keyword variants, triages by relevance and recency, fetches full paper content as markdown, then reads the actual methodology and results sections. The skill also chains into a deep research API that crawls the broader web to complement the academic findings.
The gap between "a paper was published" and "a practitioner applies the insight" is shrinking, and I think this is a practical way to provide relevant context to coding agents.
So you should write a skill on top of the HF Paper skill that teaches the model how to think about research, not just what to search for.

English
Kailin retweetledi

THIS is the wildest open-source project I’ve seen this month.
We were all hyped about @karpathy's autoresearch project automating the experiment loop a few weeks ago.
(ICYMI → github.com/karpathy/autor…)
But a bunch of folks just took it ten steps further and automated the entire scientific method end-to-end.
It's called AutoResearchClaw, and it's fully open-source.
You pass it a single CLI command with a raw idea, and it completely takes over 🤯
The 23-stage loop they designed is insane:
✦ First, it handles the literature review.
- It searches arXiv and Semantic Scholar for real papers
- Cross-references them against DataCite and CrossRef.
- No fake papers make it through.
✦ Second, it runs the sandbox.
- It generates the code from scratch.
- If the code breaks, it self-heals.
- You don't have to step in.
✦ Finally, it writes the paper.
- It structures 5,000+ words into Introduction, Related Work, Method, and Experiments.
- Formats the math, generates the comparison charts,
- Then wraps the whole thing in official ICML or ICLR LaTeX templates.
You can set it to pause for human approval, or you can just pass the --auto-approve flag and walk away.
What it spits out at the end:
→ Full academic paper draft
→ Conference-grade .tex files
→ Verified, hallucination-free citations
→ All experiment scripts and sandbox results
This is what autonomous AI agents actually look like in 2026.
Free and open-source. Link to repo in 🧵 ↓
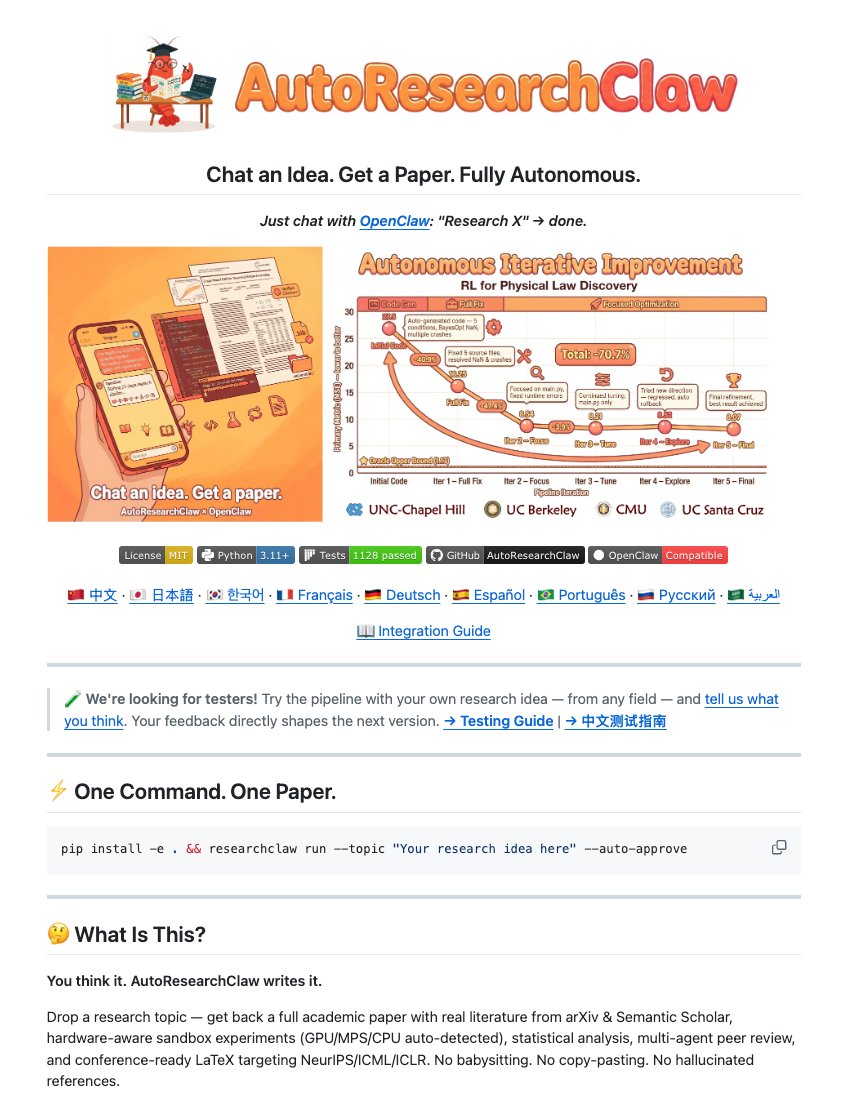
English
Kailin retweetledi

this is an open source project - add your company by opening a PR and editing the YAML file: github.com/unicorn-mafia/…
English
Kailin retweetledi

🚨 Someone just solved the biggest bottleneck in AI agents. And it's a 12MB binary.
It's called Pinchtab. It gives any AI agent full browser control through a plain HTTP API.
Not locked to a framework. Not tied to an SDK. Any agent, any language, even curl.
No config. No setup. No dependencies. Just a single Go binary.
Here's why every existing solution is broken:
→ OpenClaw's browser? Only works inside OpenClaw
→ Playwright MCP? Framework-locked
→ Browser Use? Coupled to its own stack
Pinchtab is a standalone HTTP server. Your agent sends HTTP requests. That's it.
Here's what this thing does:
→ Launches and manages its own Chrome instances
→ Exposes an accessibility-first DOM tree with stable element refs
→ Click, type, scroll, navigate. All via simple HTTP calls
→ Built-in stealth mode that bypasses bot detection on major sites
→ Persistent sessions. Log in once, stays logged in across restarts
→ Multi-instance orchestration with a real-time dashboard
→ Works headless or headed (human does 2FA, agent takes over)
Here's the wildest part:
A full page snapshot costs ~800 tokens with Pinchtab's /text endpoint.
The same page via screenshots? ~10,000 tokens.
That's 13x cheaper. On a 50-page monitoring task, you're paying $0.01 instead of $0.30.
It even has smart diff mode. Only returns what changed since the last snapshot. Your agent stops re-reading the entire page every single call.
1.6K GitHub stars. 478 commits. 15 releases. Actively maintained.
100% Open Source. MIT License.

English
@tom_doerr @raphaelmansuy Sorry. Maybe better to ask @raphaelmansuy if my cofounder and I can shoot some questions over about this repo?
English
Kailin retweetledi
@tom_doerr Hey @tom_doerr, can my cofounder and I chat with u about this ?
English
Kailin retweetledi

🚨 Holy shit… Stanford just published the most uncomfortable paper on LLM reasoning I’ve read in a long time.
This isn’t a flashy new model or a leaderboard win. It’s a systematic teardown of how and why large language models keep failing at reasoning even when benchmarks say they’re doing great.
The paper does one very smart thing upfront: it introduces a clean taxonomy instead of more anecdotes. The authors split reasoning into non-embodied and embodied.
Non-embodied reasoning is what most benchmarks test and it’s further divided into informal reasoning (intuition, social judgment, commonsense heuristics) and formal reasoning (logic, math, code, symbolic manipulation).
Embodied reasoning is where models must reason about the physical world, space, causality, and action under real constraints.
Across all three, the same failure patterns keep showing up.
> First are fundamental failures baked into current architectures. Models generate answers that look coherent but collapse under light logical pressure. They shortcut, pattern-match, or hallucinate steps instead of executing a consistent reasoning process.
> Second are application-specific failures. A model that looks strong on math benchmarks can quietly fall apart in scientific reasoning, planning, or multi-step decision making. Performance does not transfer nearly as well as leaderboards imply.
> Third are robustness failures. Tiny changes in wording, ordering, or context can flip an answer entirely. The reasoning wasn’t stable to begin with; it just happened to work for that phrasing.
One of the most disturbing findings is how often models produce unfaithful reasoning. They give the correct final answer while providing explanations that are logically wrong, incomplete, or fabricated.
This is worse than being wrong, because it trains users to trust explanations that don’t correspond to the actual decision process.
Embodied reasoning is where things really fall apart. LLMs systematically fail at physical commonsense, spatial reasoning, and basic physics because they have no grounded experience.
Even in text-only settings, as soon as a task implicitly depends on real-world dynamics, failures become predictable and repeatable.
The authors don’t just criticize. They outline mitigation paths: inference-time scaling, analogical memory, external verification, and evaluations that deliberately inject known failure cases instead of optimizing for leaderboard performance.
But they’re very clear that none of these are silver bullets yet.
The takeaway isn’t that LLMs can’t reason.
It’s more uncomfortable than that.
LLMs reason just enough to sound convincing, but not enough to be reliable.
And unless we start measuring how models fail not just how often they succeed we’ll keep deploying systems that pass benchmarks, fail silently in production, and explain themselves with total confidence while doing the wrong thing.
That’s the real warning shot in this paper.
Paper: Large Language Model Reasoning Failures

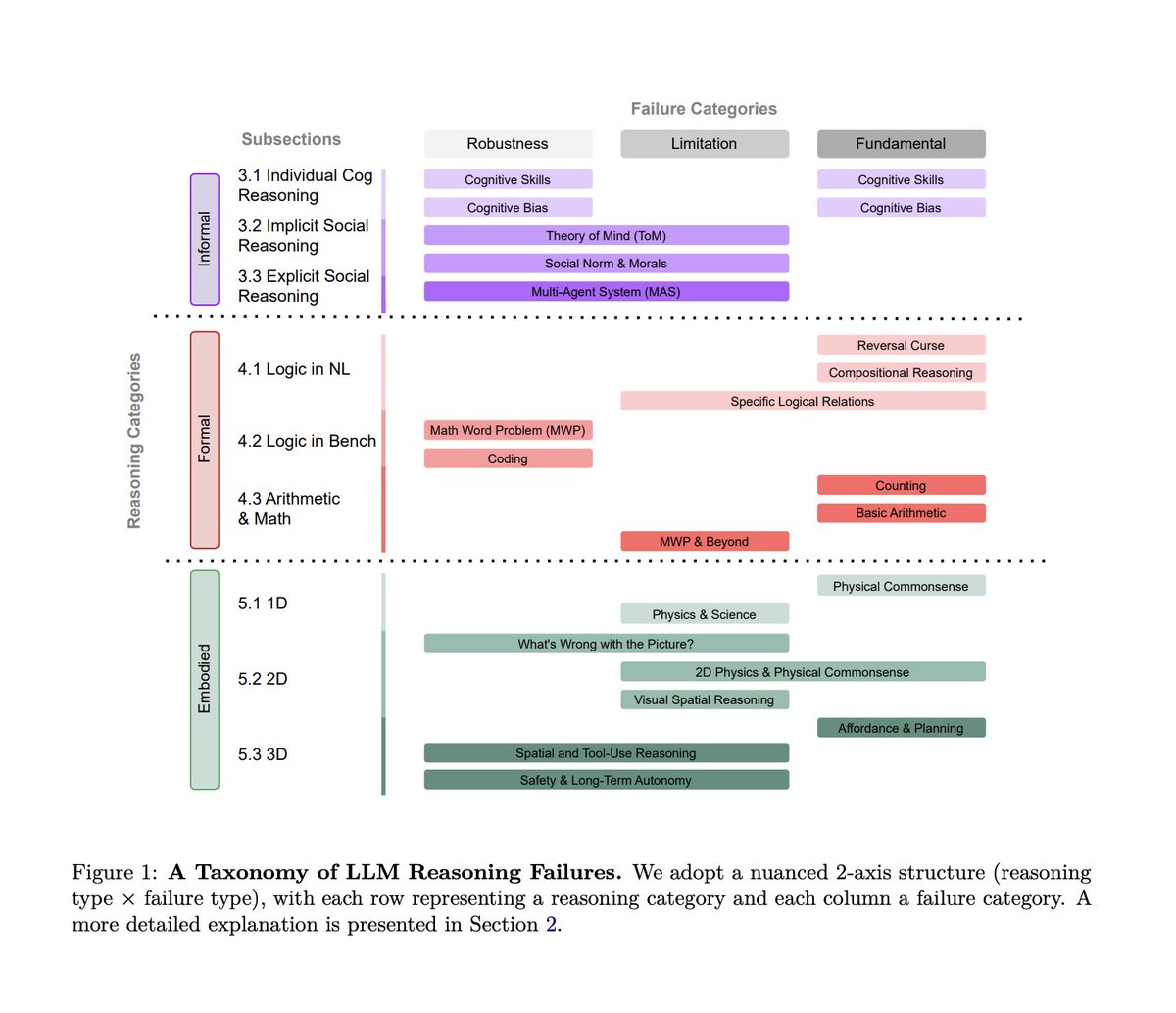
English

the desperation is intensifying..

Kailin@imkailin
Who is building agentic Quickbooks. want, need #BuildinInPublic
English