Arena.ai@arena
🚨Text Leaderboard Update
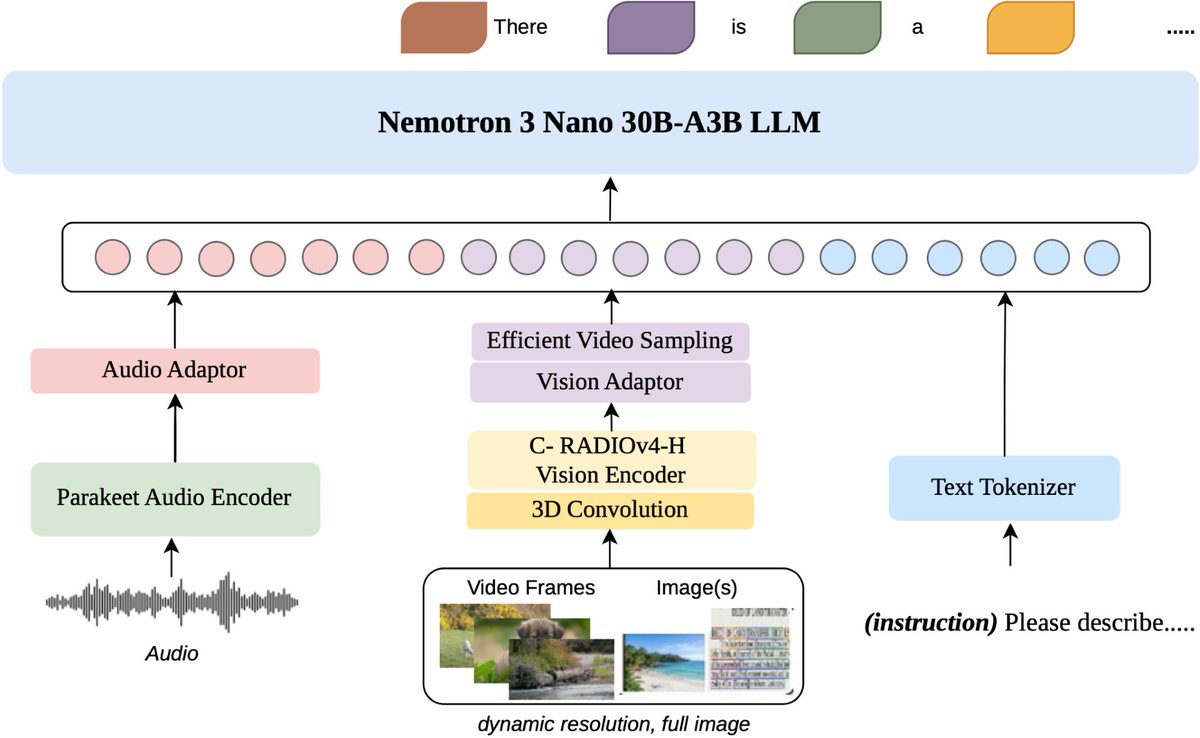
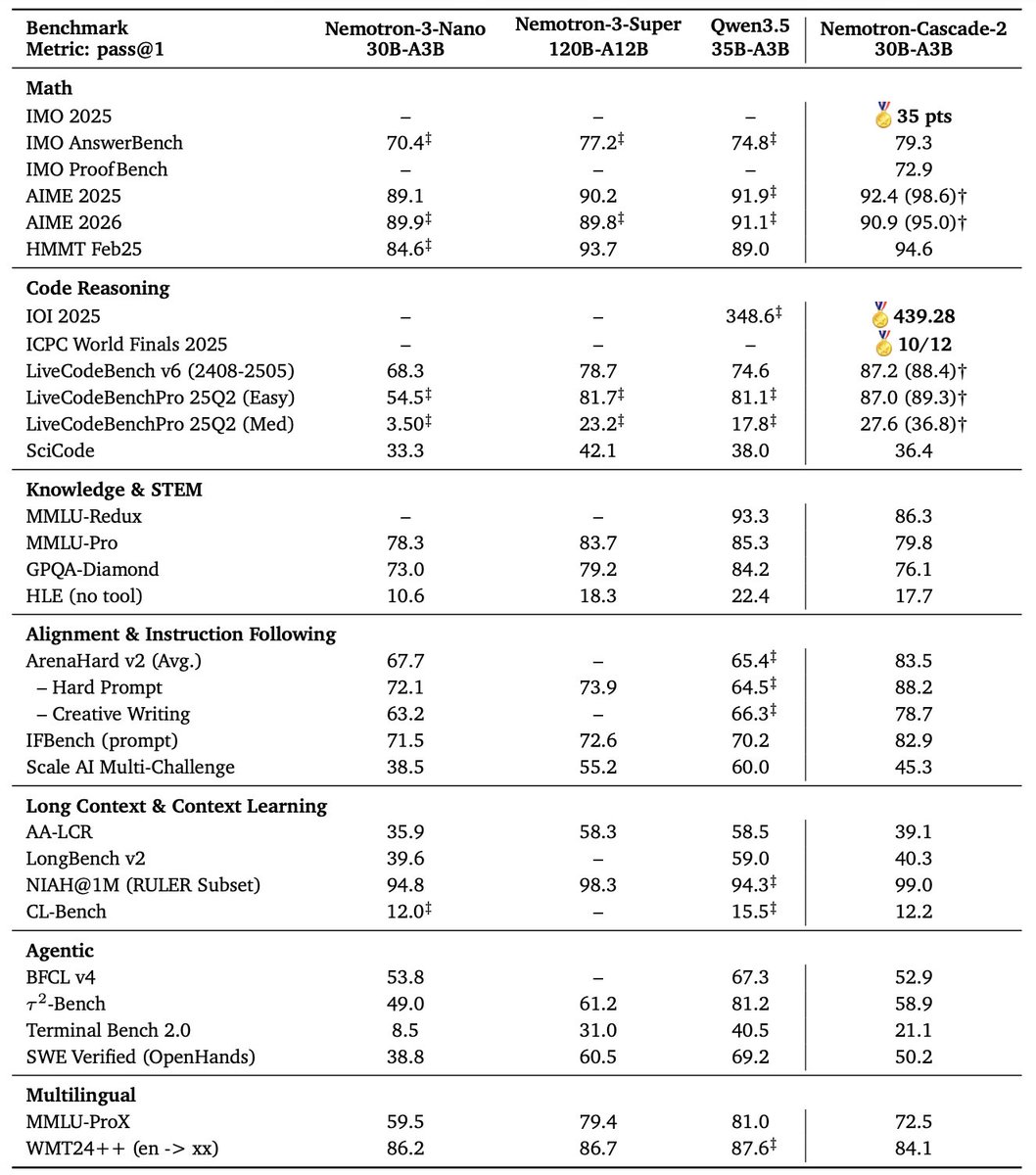
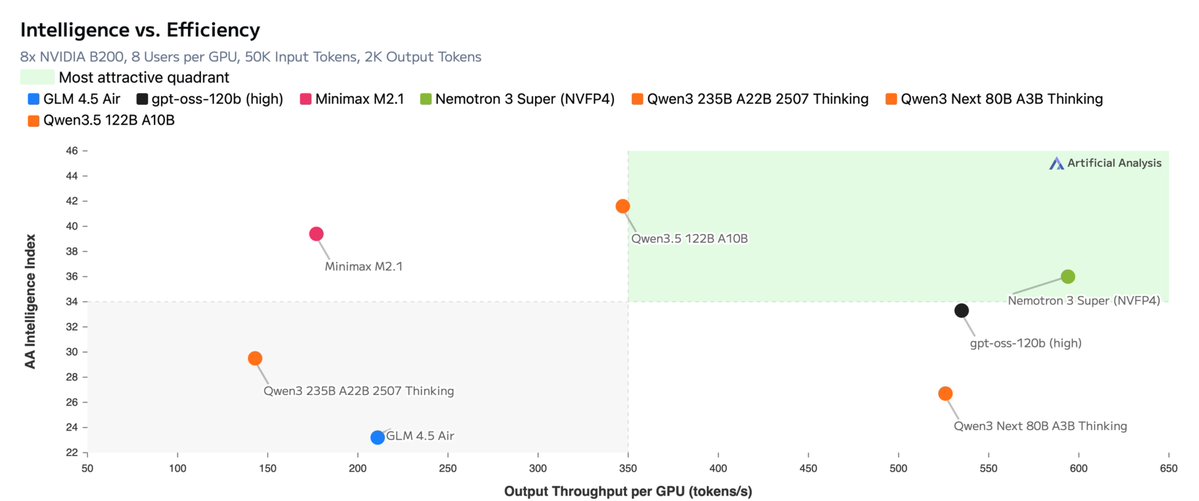
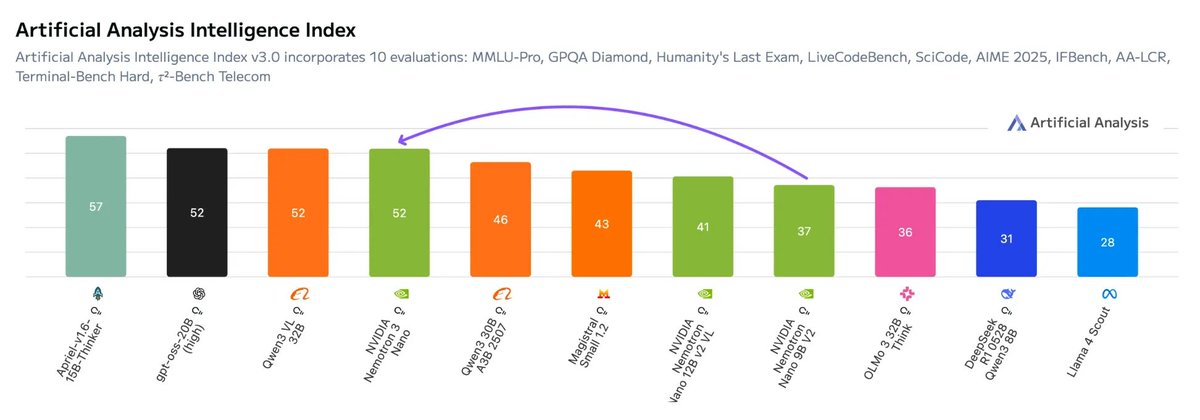
@NvidiaAI has begun rolling out the open Nemotron 3 model family, starting with Nemotron 3 Nano (30B-A3B): a new 30B hybrid reasoning model, with a 1M context window. It currently ranks #120 on the Text leaderboard with a score of 1328, and #47 among open models.
Among open models, Nemotron 3 performs best in Math and Coding categories, with strong results across IT, Science, Business, and Mathematics on the Occupational leaderboard.
Read more about Nemotron 3 Nano’s performance with real-world use in thread 🧵