mach nine
8.7K posts


mach nine
@itsmach9
interested in human learning, computing, and open money

It cannot be understated just how wrong these 'experts' were.





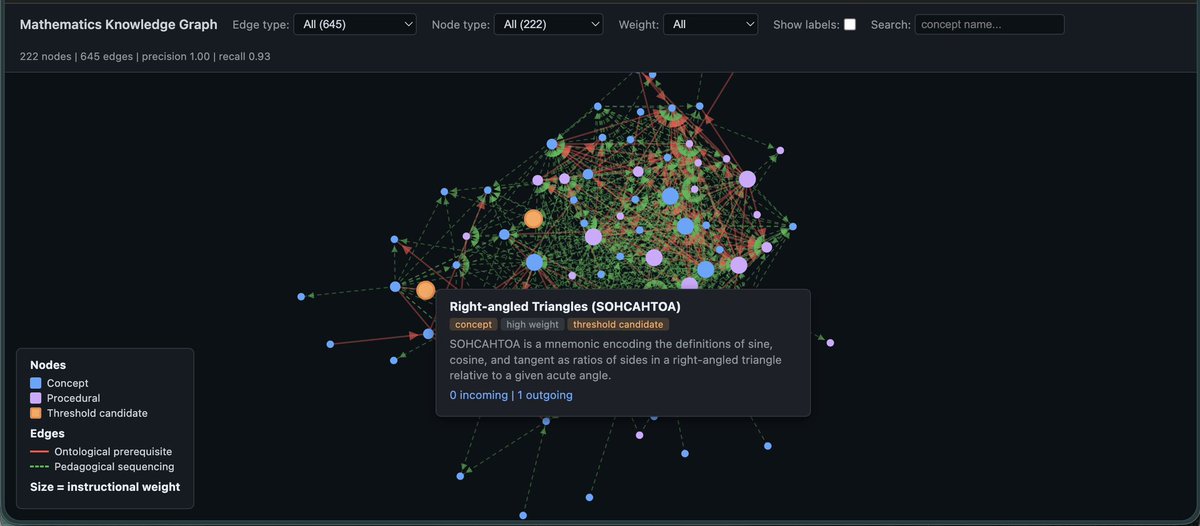
My conversation with @jliemandt on why the future of education is better than you think. 0:00 The current education system 7:01 What makes Alpha School different 11:01 What are the results 23:20 Current classroom struggles 26:40 What does mastery mean? 35:37 Changing the education system 39:19 Teaching through AI 44:27 How do you solve motivation? 57:01 What makes a good teacher? 1:01:04 Coaching 1:05:17 What life skills matter? 1:08:18 Doing hard things 1:13:25 AI Monitoring 1:21:08 Effort vs. IQ 1:24:40 What happens after Alpha School? 1:38:21 The Genius of Jack Welch 1:45:49 Trilogy IPO: the choice to not go public 1:51:40 Physical vs. virtual learning 2:03:18 Does Paying Kids To Learn work? 2:11:01 What Is Success For You? (Includes paid partnerships)






We raised $5M led by Dragonfly to build a global lottery

In the coming days, employers will see a stream of resumes of once-in-a-lifetime quality folks. An important thing to understand is that Epic never lowered our hiring standards as we grew, and the layoff wasn't a performance-based "rightsizing" as companies call it nowadays. It's a sound bet that anyone with Epic Games on their resume is in the top few percent of their discipline.










the hierarchy of local AI users: tier 1: "can it run on my macbook?" tier 2: "what GPU do i need?" tier 3: buys a 3090 and asks chatgpt how to use it tier 4: actually reads the llama.cpp docs tier 5: has 4 terminal windows open and doesn't know which one to close tier 6: the model is building games while you sleep i'm somewhere between 5 and 6

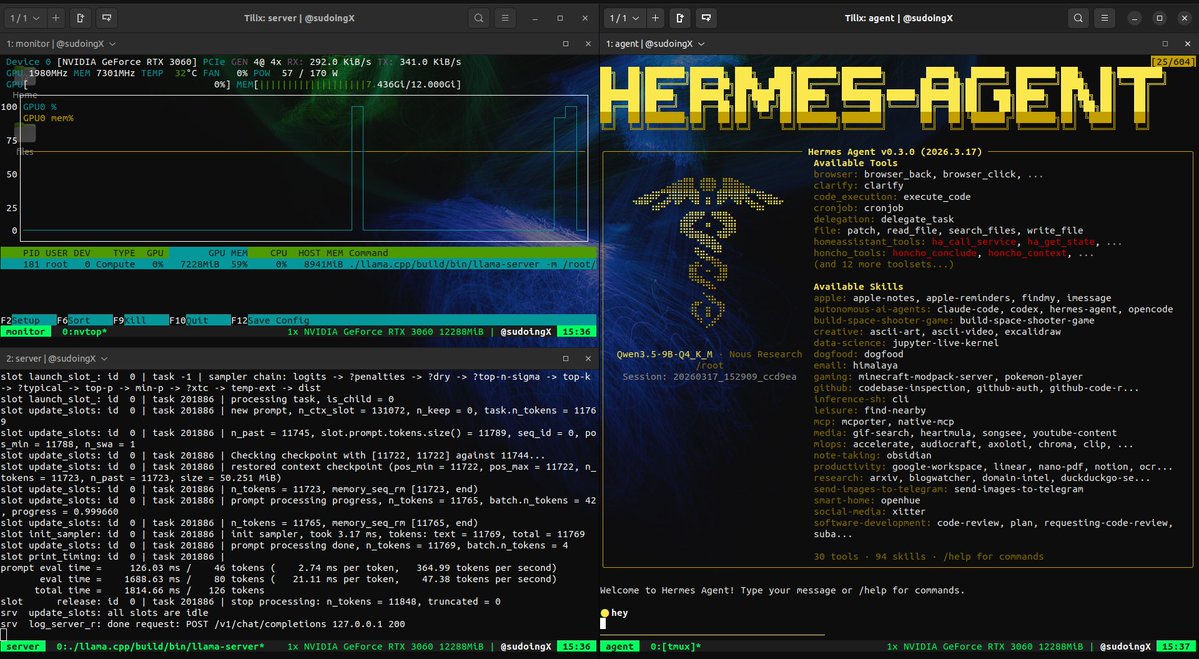

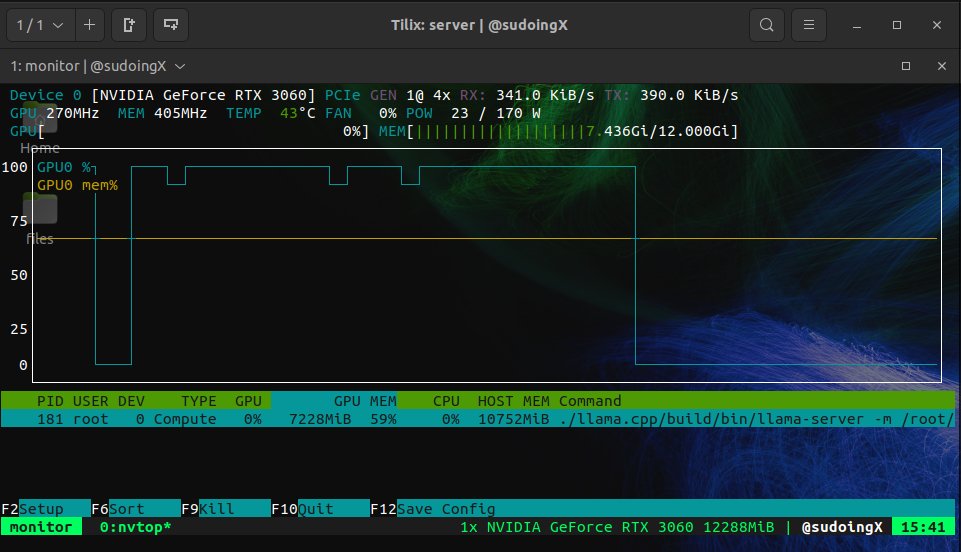
this is what 12 gigs of VRAM built in 2026. a 9 billion parameter model running on a 5 year old RTX 3060 wrote a full space shooter from a single prompt. blank screen on first try. i came back with a bug list and the same model on the same card fixed every issue across 11 files without touching a single line myself. enemies still looked wrong so i pushed another iteration and now the game has pixel art octopi, particle effects, screen shake, projectile physics and a combo system. all running locally on a card that was designed to play fortnite. three iterations. zero cloud. zero API calls. every token generated on hardware sitting under my desk. the model reads its own code, finds what's broken, patches it, validates syntax and restarts the server. i just describe what's wrong and it handles the rest. people are paying monthly subscriptions to type into a browser tab and wait for a server farm to respond. meanwhile a GPU you can find used on ebay is running a full autonomous hermes agent framework with 31 tools, 128K context window and thinking mode generating at 29 tokens per second nonstop. the game still needs work. level upgrades don't trigger and boss fights need tuning. but the fact that i'm iterating on gameplay balance instead of debugging whether the code runs at all tells you where this is headed. every iteration the game gets better on the same hardware. same 12 gigs. same 9 billion parameters. same RTX 3060 from 5 years ago your GPU is not a gaming card anymore. it's a local AI lab that never sends your data anywhere.



