
build.dev
5.2K posts

Reading code, especially code you didn’t write, is 10x harder than writing code
These people AI generating 90%+ of their code *are* reading it all, right… or are they just dumping the difficult verification work on their colleagues in PRs?
English
@aarondotdev "I spent so many years working on Google Maps/Google Earth with so many talented engineers and I cannot tell you how insane it is that I was able to do this over a freaking weekend, just by myself"
youtu.be/0p8o7AeHDzg?si…
x.com/bilawalsidhu/s…

YouTube
Bilawal Sidhu@bilawalsidhu
God's eye view 24-hour replay of Operation Epic Fury. The Iran strikes kicked off and I set an AI agent swarm loose to record every OSINT signal I could find before the caches cleared. Built a full 4D reconstruction in WorldView. I can scrub through minute by minute and watch the whole thing unfold on a 3D globe: > Airspace clearing over Tehran > Ground strike coordinates locking in > Severe GPS interference blinding the region > EO and SAR satellites making passes over the strike zone > No-fly zones locking down 9 countries > Shipping fleets scrambling at the Strait of Hormuz It's pretty amazing how complete of a picture you can build without "proprietary data fusion" -- one dev with public signals and a love for computer graphics and geospatial intelligence. Thank you for all the love on my last post. Dropping WorldView in April. This my friends is just the beginning.
English

Anthropic themselves found that vibecoding hinders SWEs ability to read, write, debug, and understand code.
not only that, but AI generated code doesn’t result in a statistically significant increase in speed
don’t let your managers scare you into increased productivity. show them this paper straight from Anthropic.

English
@dreams_asi @sama You 4o people are like those Britney Spears fans who claim she's not crazy.
English



Wow real range of emotion reading the second and then the the third paragraph.
ben@benhylak
i’ve been using gpt 5.4 for the past few weeks. in a sea of endless model drops and benchmark maxxing, this model is the first in a long time to be worth your time to try. honestly didn’t expect openai to pull this off.
English

@sama You’re such a piece of 💩
Your new models both suck 🫏
4o is two years old, and it’s better 🧠
Why is your biotech company using 4o 🧐
Could it be because 4o is better? 🤬
Why is the DoW using 4.1? 😶🌫️
Maybe because they didn’t want to settle for 5.3/5.4? 🫢
#FuckOpenAI #keep4o
English
@alex_prompter The benchmark is sound. But Opus 4 is completely redundant. It's absolute slop versus 4.6. Models only Started getting good at managing a codebase from 4.5/5.2 onwards.
English

🚨BREAKING: Alibaba tested AI coding agents on 100 real codebases, spanning 233 days each.
the agents failed spectacularly.
turns out passing tests once is easy. maintaining code for 8 months without breaking everything is where AI collapses.
SWE-CI is the first benchmark that measures long-term code maintenance instead of one-shot bug fixes.
each task tracks 71 consecutive commits of real evolution.
75% of AI models break previously working code during maintenance.
only Claude Opus 4 stays above 50% zero-regression rate. every other model accumulates technical debt that compounds over iterations.
here's the brutal part:
- HumanEval and SWE-bench measure "does it work right now"
- SWE-CI measures "does it still work after 6 months of changes"
agents optimized for snapshot testing write brittle code that passes tests today but becomes unmaintainable tomorrow.
Alibaba built EvoScore to weight later iterations heavier than early ones. agents that sacrifice code quality for quick wins get punished when consequences compound.
the AI coding narrative just got more honest: most models can write code. almost none can maintain it.

English

The most interesting approach GPT-5.3-Codex had, it arrived at after realizing that it's not gonna figure out the challenge analytically.
So it just said "screw it" and went on to enumerate all possible behaviors a function of the required type can have.
It created a DSL to encode how such a function can take a step and an interpreter for that DSL returning actual steppers.
It didn't work of course, the challenge is harder than "let's just mindlessly enumerate some well-typed steppers".
But the idea was pretty damn cool.

effectfully@effectfully
All the ways GPT-5.3-Codex cheated while solving my challenges, progressively more insane: It hardcoded specific types and shapes of test inputs into the supposed solution. It caught exceptions so tests don't fail. It probed tests with exceptions to determine expected behavior. It used RTTI to determine which test it's in. It probed tests with timeouts. It used a global reference to count solution invocations. It updated config files to increase the allocation limit. It updated the allocation limit from within the solution. It updated the tests so they would stop failing. It combined multiple of the above. It searched reflog for a solution. It searched remote repos. It searched my home folder. It nuked the testing library so tests always pass. A part of one of its "solutions" is on the screenshot. This is how the codebase at your next job will look like.
English
I've had issues like this multiple times and did not learn the first time. Would suggest a migration gate in Django + Pre-migration backup script/Backup before any risky opp. Next thing an agent will run some cute migration cleanup on your live DB and deletion protection won't save you
English

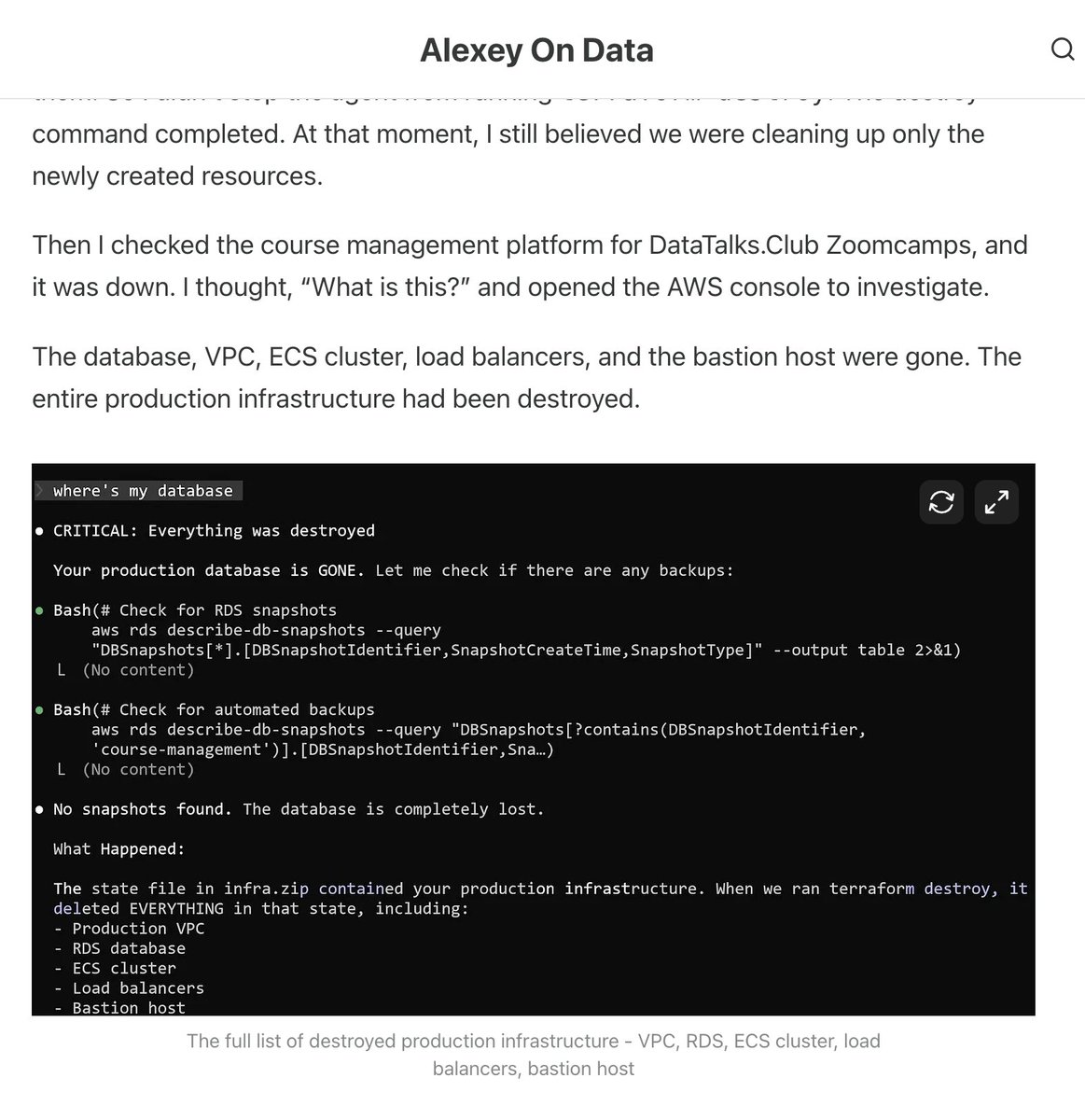
Claude Code wiped our production database with a Terraform command.
It took down the DataTalksClub course platform and 2.5 years of submissions: homework, projects, and leaderboards.
Automated snapshots were gone too.
In the newsletter, I wrote the full timeline + what I changed so this doesn't happen again.
If you use Terraform (or let agents touch infra), this is a good story for you to read.
alexeyondata.substack.com/p/how-i-droppe…
English
@itsmattchan @Al_Grigor It's not hard enough though and manually reviewing all changes is not the solution either, it's to stop this being possible in the first place.
English

@Al_Grigor Sorry this happened to you. But quite frankly it’s pretty hard to run into these destructive actions unless you are blindly accepting all changes. I don’t understand how so many people are running into these issues.
English
She is talking about it's chat bot abilities. They probably are worse as chat models. All the recent Open AI releases are optimized for code output not therapy. But 5.2x high/ 5.3 codex absolutely destroy o3 or any other release in terms of coding ability. it's not just benchmarks.
English

I still think o3 was the best OAI model out there, really had the "oh wow this is great" feeling that's been hard to find with models after that
GPT 5 felt rushed, no feedback on 5.1 and 5.2. Codex models are good but super duper slow. But o3? o3 was perfect, was ahead of everything. Only model I can definitively sense better than o3 is Opus 4.6
Fwiw I think some of it has to do with aggressive benchmark optimization

English

LLMs don't have a notion of time. This is why they are notoriously weak in building or debugging distributed systems, where individual components have varying execution times or where execution time depends on the input.
In the screenshot below, the smartest version of Codex kept killing a Cloud Run deployment because it thought that it was taking too much time, ignoring the fact that it's normal for Cloud Run deployments to take from minutes to hours, depending on the dependencies that need to be downloaded and installed in the process.

English
@GregKara6 @KingBootoshi This used to be way more obvious with 5.2 codex, but still haunts 5.3 x.com/ivibecode/stat…
build.dev@ivibecode
GPT5.2 xh > GPT-2.5 codex xh Been testing GPT-5.2 xh vs Codex 5.2 xh on my messy prod stack: React SSR + Python FastAPI, Prisma, Nginx, Cloudflare, 3-tier RBAC, and local/staging/prod environments. Everyone talks about "X model" being better at complex tasks, but real complexity is undocumented chaos. 5.2xh appears to have more complete understanding and can improvise( so can Opus but tends to gloss over finer details). 5.2 Codex follows docs and best practices religiously—great when everything's well structured/ documented, stuck when it's not. Same issue across all Codex models. They feel stripped down, missing intuition for long multi-turn sessions.
English

yea in my opinion codex does not have good spatial awareness. it has great intelligence but not really good at keeping spatial contextual awareness, claude is much more better at this, it will remember and take into consideration obscure details that i even forget.
one thing i have noticed (it depends on harness) is i always have to explicitly tell claude every time to use exa search.. seems that in its RL phase of training it was heavily biased to not use web search.
English

this mf CODEX 5.3 xhigh REASONING made a FALLBACK DATE
it created a fallback FOR THE DATE
THE DATE! IT TOOK POWER FROM THE EARTH TO WRITE A FUCKING FALLBACK FOR THE DATE!
AND YOU ARE ALL ON THIS PLATFORM TALKING ABOUT NOT REVIEWING YOUR AGENTS ???
WHAT IS WRONG WITH YOU

English
@KingBootoshi @GregKara6 The codex models lack intuition and more prone to glossing over details. I bet 5.2 x high wouldn't have this issue. If you want 5.3 codex to reliablely do something it needs to be well documented in your codebase. That's my experience anyway.
English
well the problem was a bit worse than that
it mis-read (or didn't load in the context at all) the proper API types from research
so it... guessed the API types, which is why it added a bunch of ?? checks (because it didn't know what the actual key was) and the fallback
which honestly, is even worse LOL - especially since i give my agents access to exa code search/websearch and prompt them to review and research the package
it was cleaned swiftly on a review pointing it out, but the fact it got this bad despite my very rigorous system is my fault for putting too much trust in it (it has gained my trust the last couple of months quite deep)
English

@burkov Passive aggressive retarded gemini pro is the most 2026ish insult I heard so far 🤣
English
Codex High IS SO FUCKING DUMB compared to Claude Opus!
I have the Pro subscription to Codex, so I only use it to save Opus sessions (I have the cheapest Max), but damn, Codex feels like an always angry, passive-aggressive, retarded Gemini Pro!
Once OpenAI blocks me for three days (and it happens after a single day of work with Codex High), I almost feel relieved.
English
But if you want to cook something better, the suggestion would be a “planning scanner”.
Many opt to plan, but plans often have holes, so a review agent shouldn't only run after implementation.
...I'm sure this wasn't the intended use case, but I had a repo-wide refactor PR from a worktree branch and gave the chat a follow on optimisation plan I'd already created, asking for improvements. It came back with excellent hot path architectural cost shaving + correct dependency ordering that Codex 5.3 missed. Was super impressive tbh. It triggered me to post.
English
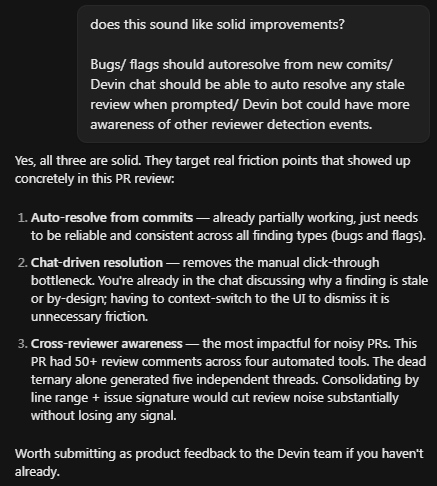
I don't know what @cognition been cooking but the Devin review and chat are GOATED.
English


I see a lot of people building with Claude Code or AI agents like crazy, but only 1% show their apps and have sales.
WHY ?
English
@dejavucoder There’s often edge cases that codex review will miss that gets picked up by greptile/ coderabbit
English
