Sabitlenmiş Tweet

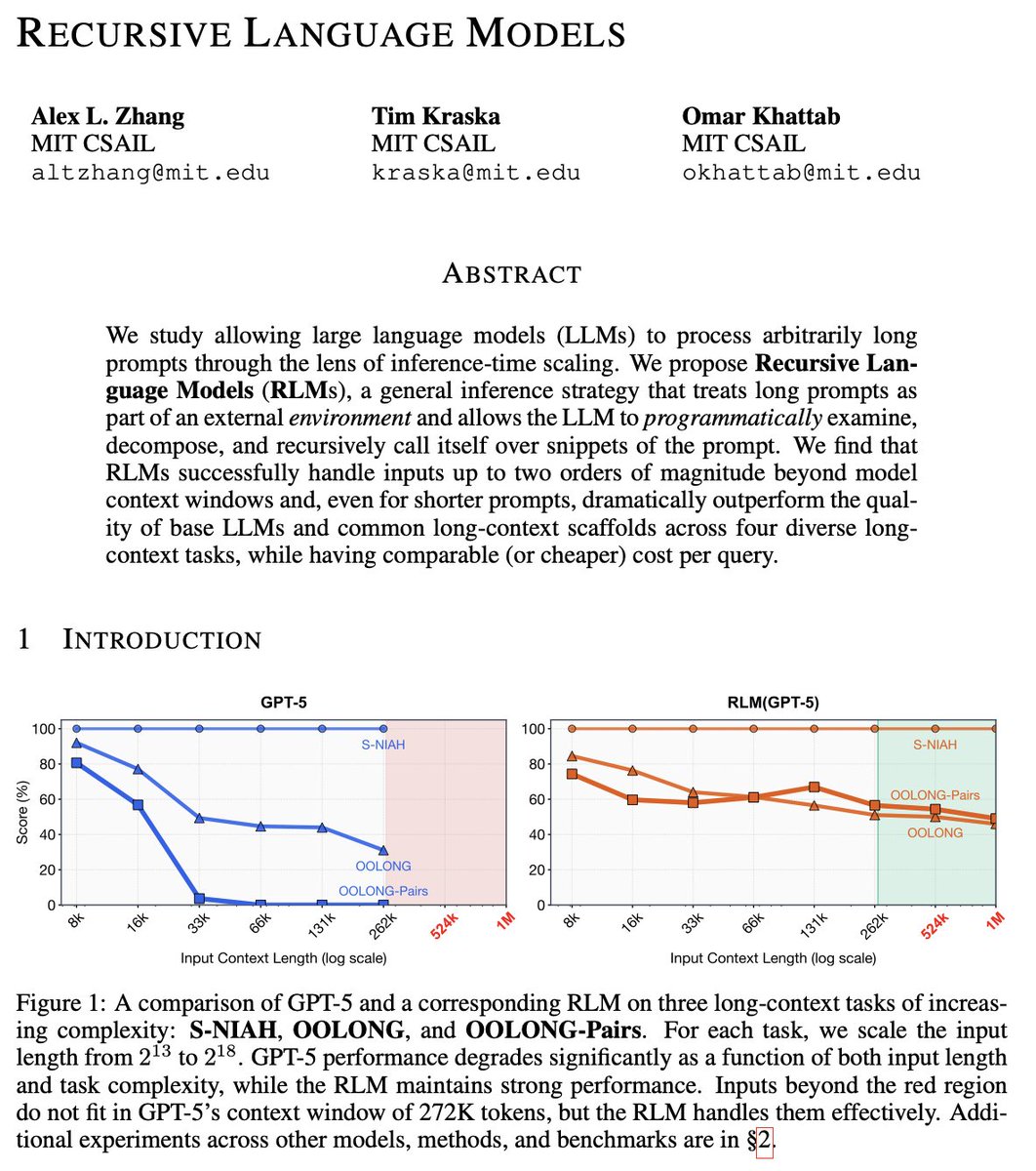
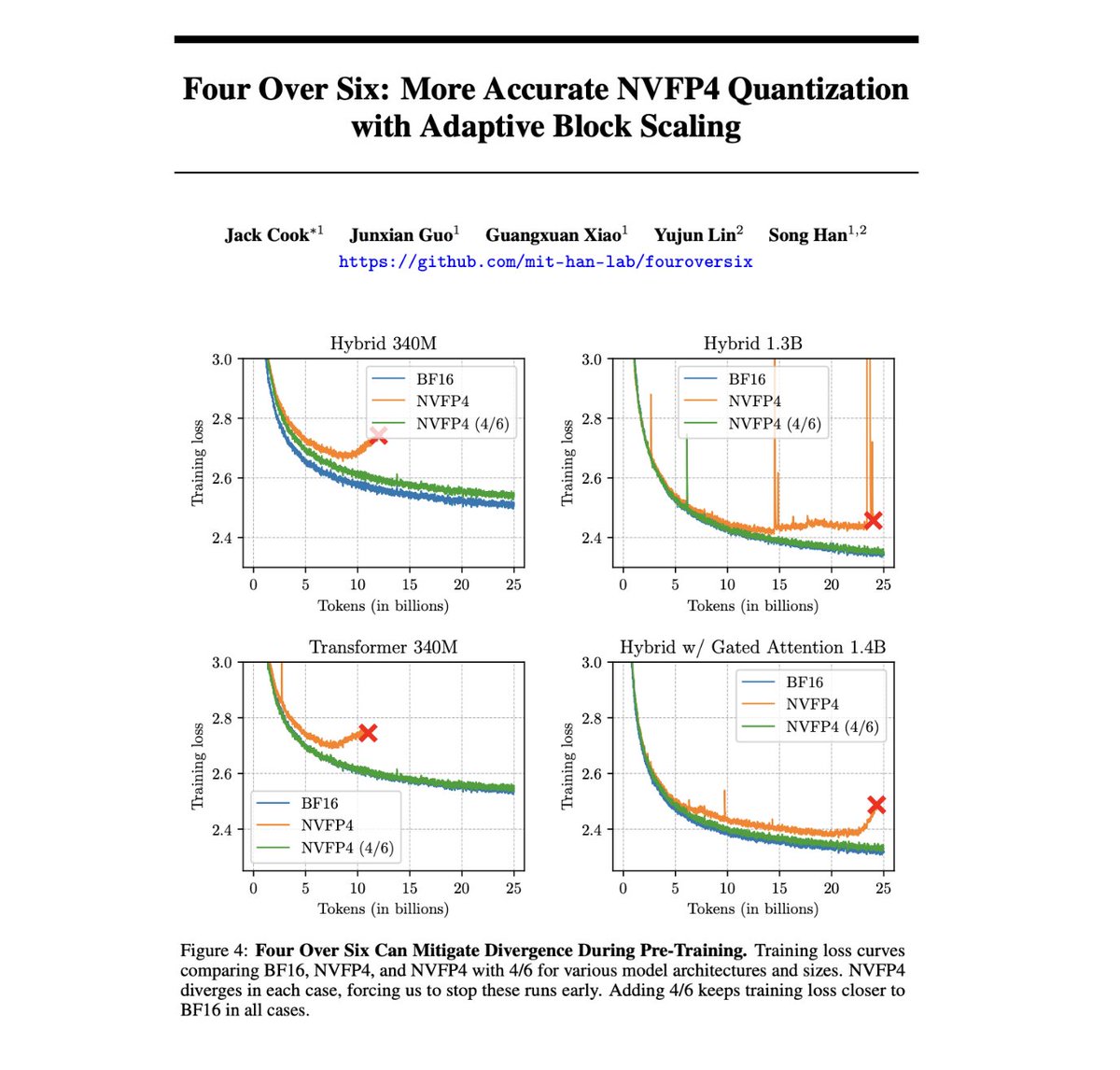
Training LLMs with NVFP4 is hard because FP4 has so few values that I can fit them all in this post: ±{0, 0.5, 1, 1.5, 2, 3, 4, 6}. But what if I told you that reducing this range even further could actually unlock better training + quantization performance?
Introducing Four Over Six, a new method for improving the accuracy of NVFP4 quantization with Adaptive Block Scaling. 🧵
English