jfanes
331 posts


这是真消息,而且这个新闻我就不评论了,我完全搬运原文。
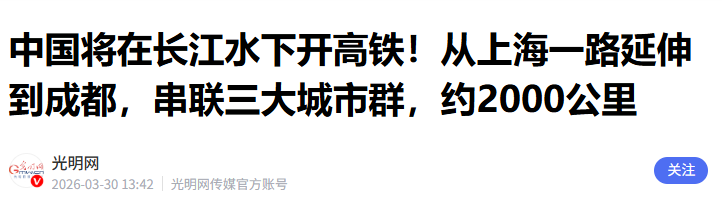
《中国将在长江水下开高铁!从上海一路延伸到成都,串联三大城市群,约2000公里》
“十五五”重大工程——沿江高铁的标志性项目,正在加紧施工。它将从上海一路延伸到成都,串联三大城市群,绵延约2000公里。
沿江高铁总投资超5000亿元,据测算,将带动上下游行业增加值增长近1.5万亿元。
中文
@AlchainHust 作为千问负责人,林俊旸的文章很有价值
肯定了当下agent的训练方式和趋势,算是给我们做agent应用的用户喂了定心丸😂
读得出来他的思考很深刻,但针对混合思考模式的描述有点干巴
花叔的解读很到位,可能很多媒体没很好理解林俊旸的意思
林俊旸的努力方向不一定不对,但是agent的环境要求确实提高了
中文

作为千问负责人,林俊旸的文章很有价值
肯定了当下agent的训练方式和趋势,算是给我们做agent应用的用户喂了定心丸😂
读得出来他的思考很深刻,但针对混合思考模式的描述有点干巴
花叔的解读很到位,可能很多媒体没很好理解林俊旸的意思
林俊旸的努力方向不一定不对,但是agent的环境要求确实提高了
花叔@AlchainHust
中文



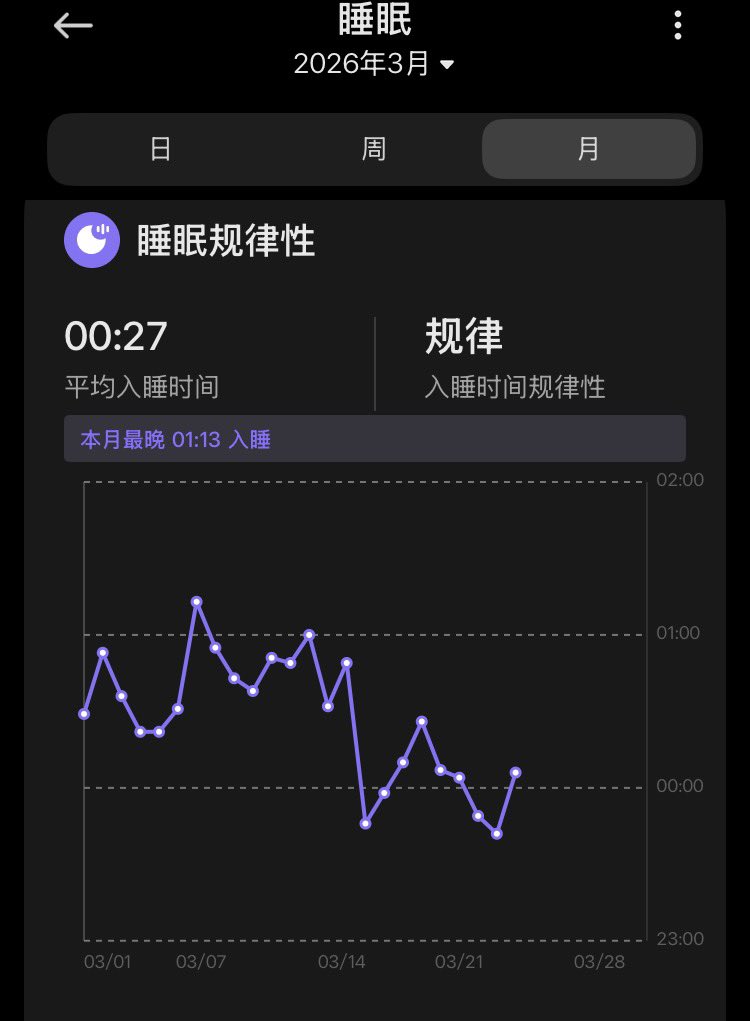





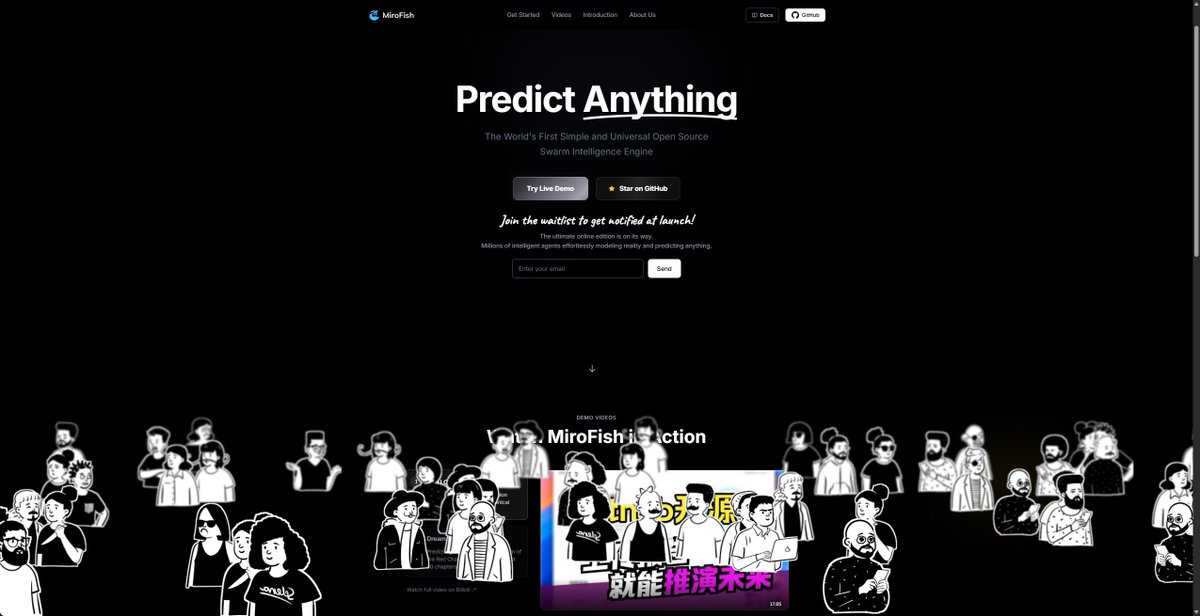
我想,你大概率刷到过这个故事
一个叫郭航江的 00 后,北邮大四,用 Claude Code 做 Vibe Coding,十天搓出一个叫 MiroFish 的东西
它能生成上千个带独立人格的 AI 智能体,让它们在一个虚拟社会里自由碰撞,然后告诉你:
接下来会发生什么
GitHub Trending 全球第一,34,500+ Star,4,600+ Fork
有人拿它推演红楼梦结局,有人用它做 Polymarket 交易机器人(338 笔交易盈利 $4,266)
Brian Roemmele 在一次模拟里跑了 50 万个 Agent
陈天桥看完 Demo,24 小时拍板 3000 万
这件事的后续,大部分人没关注到
郭航江加入了 EverMind,一个专做 AI 记忆基础设施的团队
近期,这个团队放出了第二颗子弹:
MSA(Memory Sparse Attention)
如果说 MiroFish 解决的是AI 能不能预测未来,
MSA 解决的是一个更底层、更致命的问题:
AI 能不能记住过去?
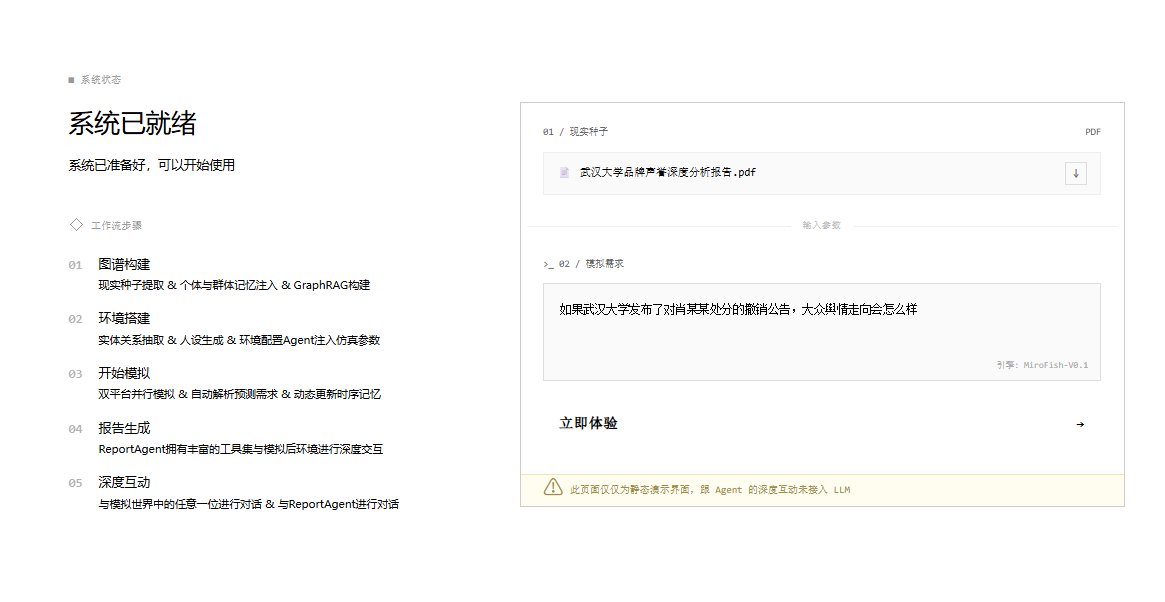
Soran@Soranlan
伙伴们,记忆赛道又出新东西了,一个 4B 的小模型,长记忆测试 9 项基准平均分,超过了 KaLMv2 + Qwen3-235B 的顶级 RAG 流水线 参数量差 60 倍(但 5 个单项仍然落后——后面说) EverMind 刚发的 MSA 论文,走了一条跟 RAG、扩窗口、KV 压缩完全不同的路: 不压缩记忆,不外挂检索,让模型自己学会挑重点看 端到端训练,选择机制长在注意力里 更离谱的是,从 16K 训练长度外推到 1 亿 token,精度在 MS MARCO 上只掉不到 9% 大多数方案超过训练长度 8 倍就崩了 MSA 超了 6000 倍还能用
中文







最近高强度在雪球上学习。
雪球的信息密度和质量都比推特好太多了。
可惜币圈没有雪球这样的平台。
是因为值得聊或者研究的内容太少了吗?
从研究到拿到结果中间的不确定性也很大。
很多时候你分不清是你认知到位了,还是纯粹的运气好。
中文