Sabitlenmiş Tweet

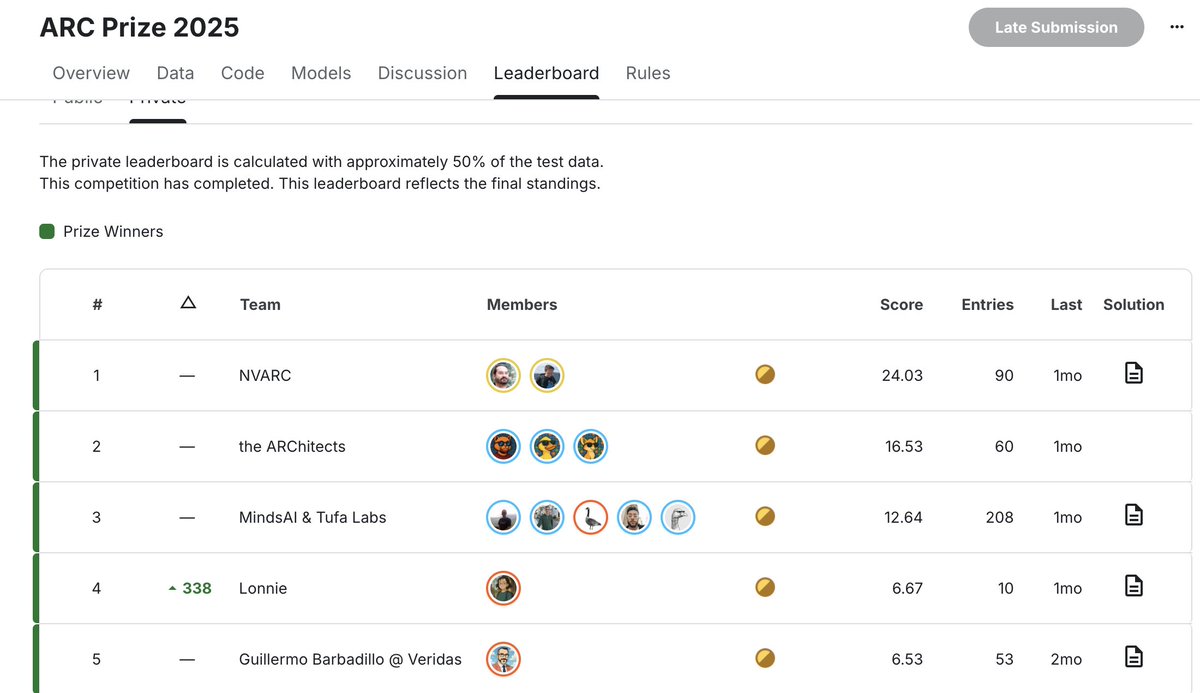
Ivan Sorokin and I are the official winners on the Arc Prize competition, with a significant lead over other teams.
Thanks to @kaggle and @arcprize for hosting the competition.
NVIDIA tech blog summarizing what we did: developer.nvidia.com/blog/nvidia-ka…
Our writeup: kaggle.com/competitions/a…
Our code: github.com/1ytic/NVARC
English