Sabitlenmiş Tweet

Thrilled to introduce our latest work "Compression Represents Intelligence Linearly" 📜✨ on the intriguing relationship between compression efficiency and intelligence in large language models (LLMs) 🤖.
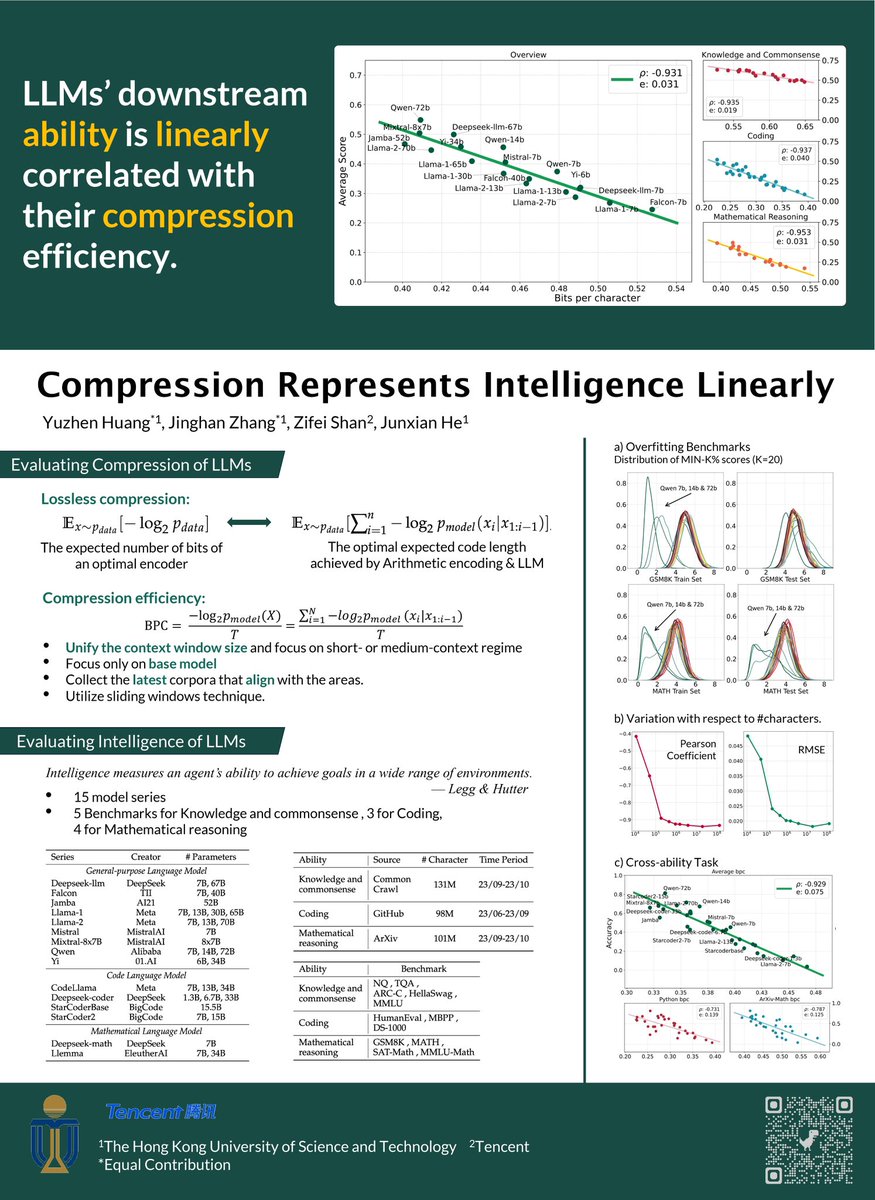
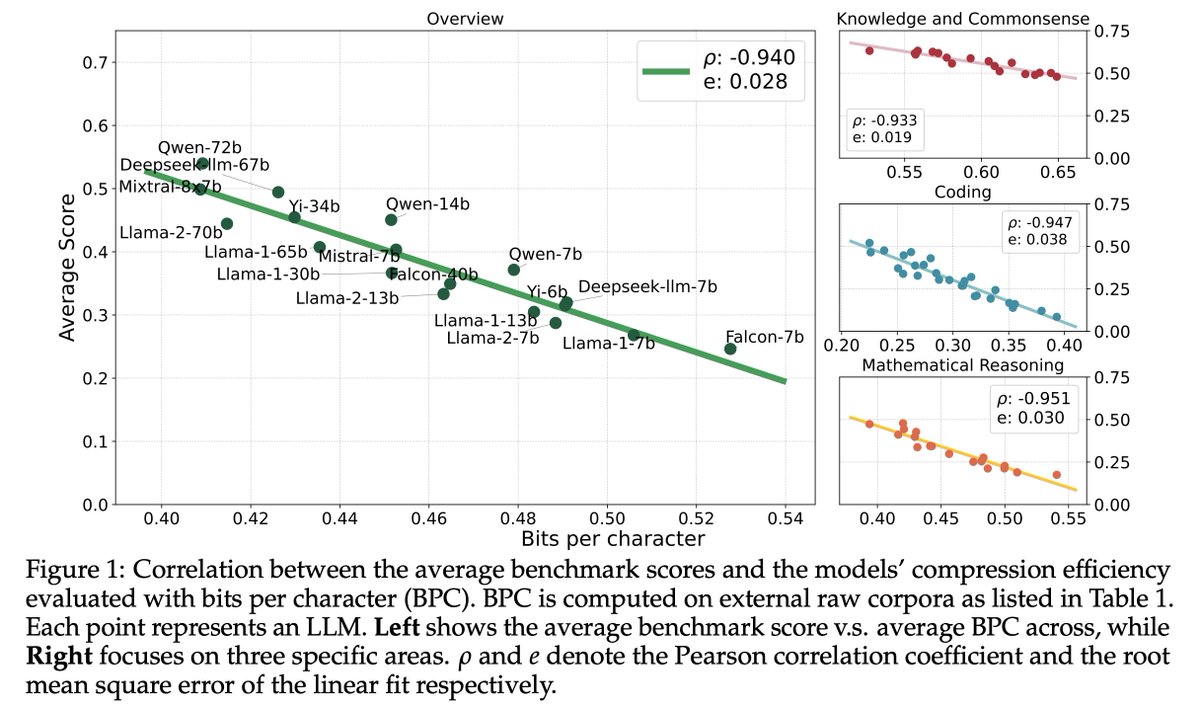
Diving deep into 30 public LLMs from various organizations 🌍, we examined their performance across 12 benchmarks focusing on knowledge and commonsense, coding, and mathematical reasoning 🔍. We find a near-linear correlation between LLMs' ability to compress external text corpora and their intelligence, as measured by average benchmark scores 📊.
This research not only supports the theory that superior compression hints at greater intelligence but also introduces compression efficiency as a reliable, unsupervised metric for evaluating model abilities 🎯.
Dive into our insights and access our datasets & pipelines for your research ➡️
📄Paper: arxiv.org/abs/2404.09937
💻Code: github.com/hkust-nlp/llm-…
📚Dataset: huggingface.co/datasets/hkust…
Great collaboration and many thanks to my collaborators @yuzhenh17 and @junxian_he !!🥰
English