
English
Jinyi Li
423 posts

@jinyibruceli
Building products across the US and China. Design & Cognitive Science @UMich. Shipped 200K+ downloads.








Love pushing the boundaries of what constitutes an “edit” with #GeminiOmni. For this one I started with my original generation in @FlowbyGoogle and then edited it with the prompt. “A construction worker in a high-visibility vest and hard hat, standing on a bustling job site with scaffolding in the background. He looks slightly off-camera, wiping his brow and gesturing as he delivers the same lines in a husky voice.”






🚨🇺🇸🇨🇳OPENAI WARNS U.S ABOUT CHINA'S DEEPSEEK AI OpenAI has labeled Chinese AI model DeepSeek a "significant risk" and urged the U.S government to take action. In a letter to the White House, OpenAI’s Chris Lehane warned that DeepSeek’s rapid progress could threaten U.S dominance in AI and pose security risks, alleging potential government manipulation and intellectual property theft. As part of the U.S "AI Action Plan," OpenAI proposed restricting access to advanced AI technology for certain countries, including China. Source: CGTN







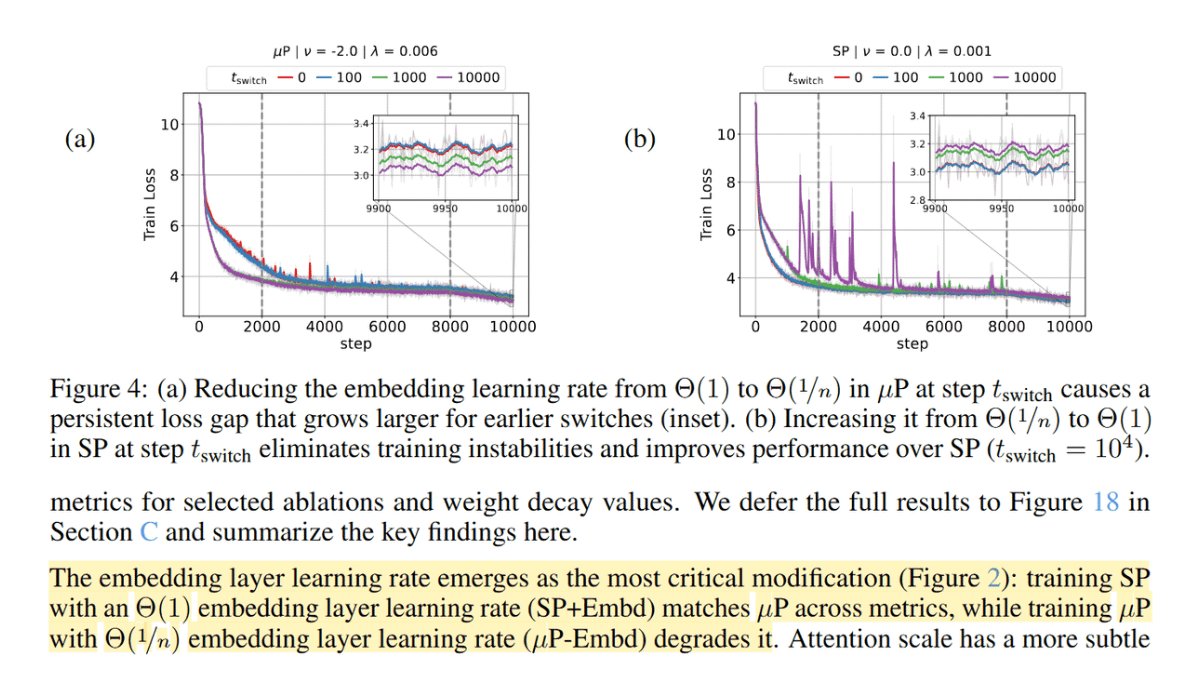
Latest open artifacts (#21): Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6, MiMo 2.5, GLM-5.1 & others. On CAISI's V4 assessment. An eventful month with one flagship release after another interconnects.ai/p/latest-open-…


