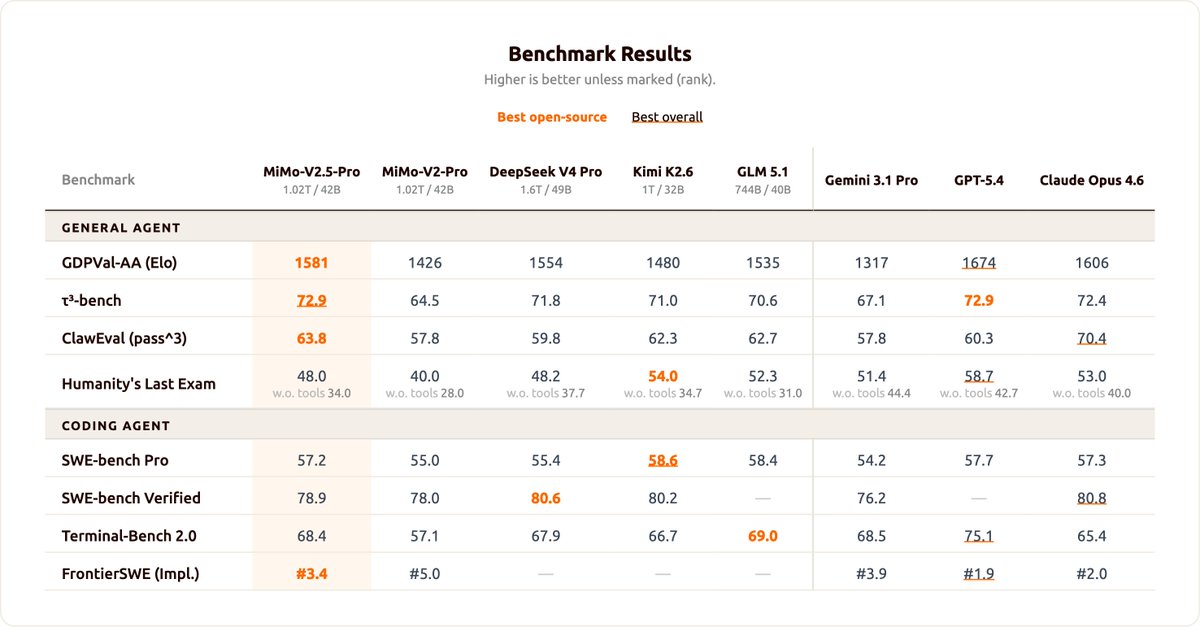
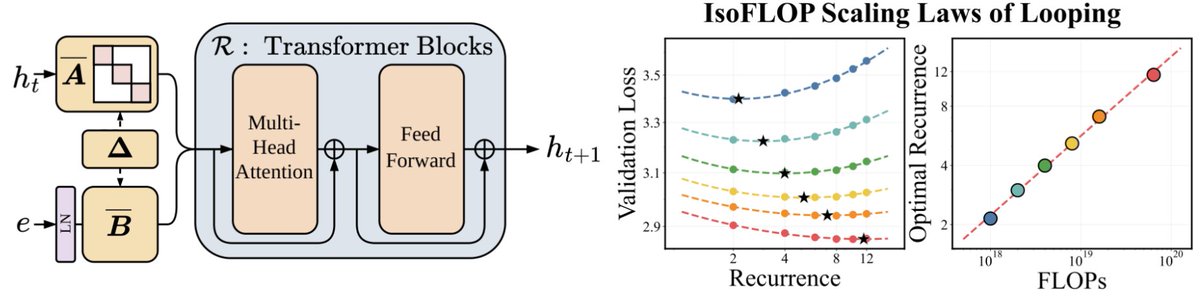
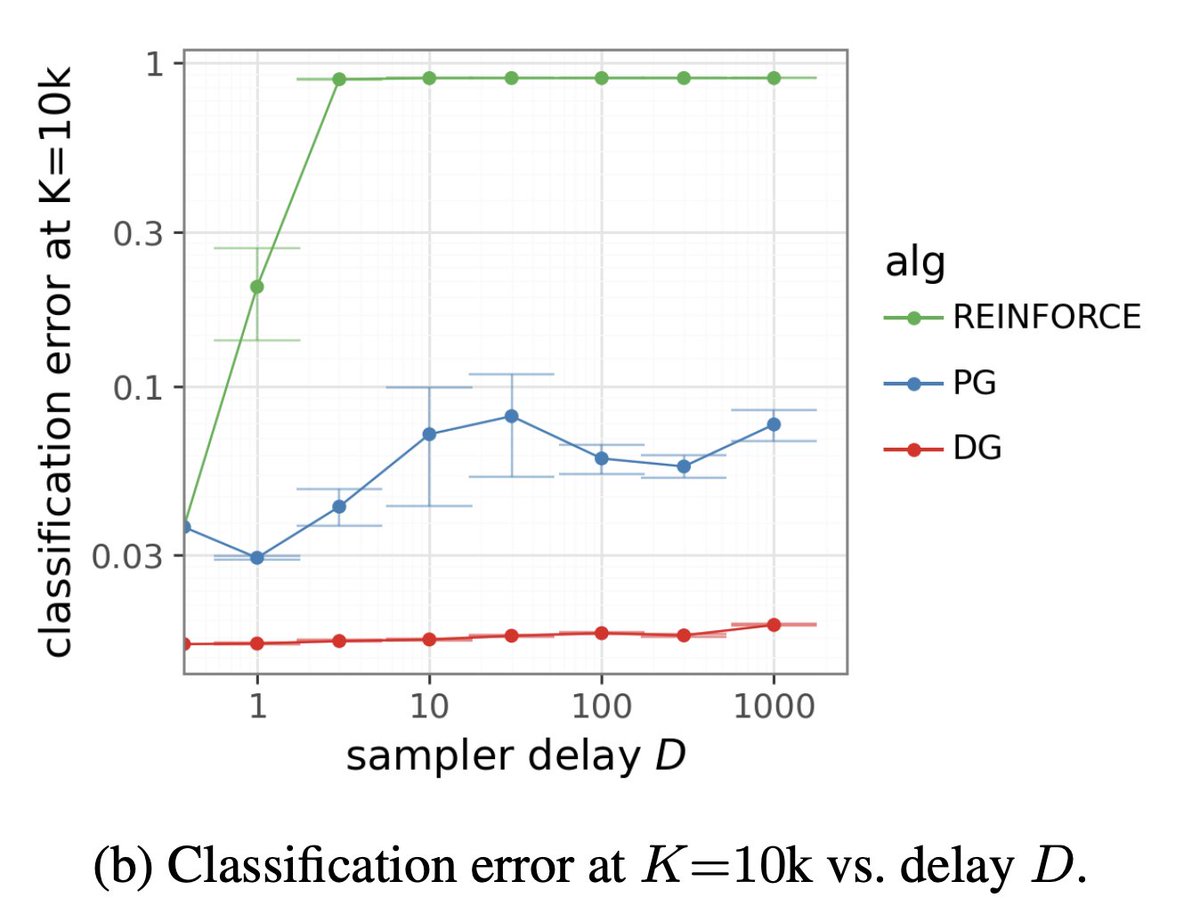
Sabitlenmiş Tweet

A Public AI Wealth fund, not 'basic income'. It is time for Congress to act.
thehill.com/opinion/techno…
English
John deVadoss
13 posts

@john_devadoss
co-Founder NeuralFabric acq. by @Cisco | co-Founder @IntWorkAll | Board @GBBC_io | General Manager @Microsoft | Phd RL research @UMassAmherst



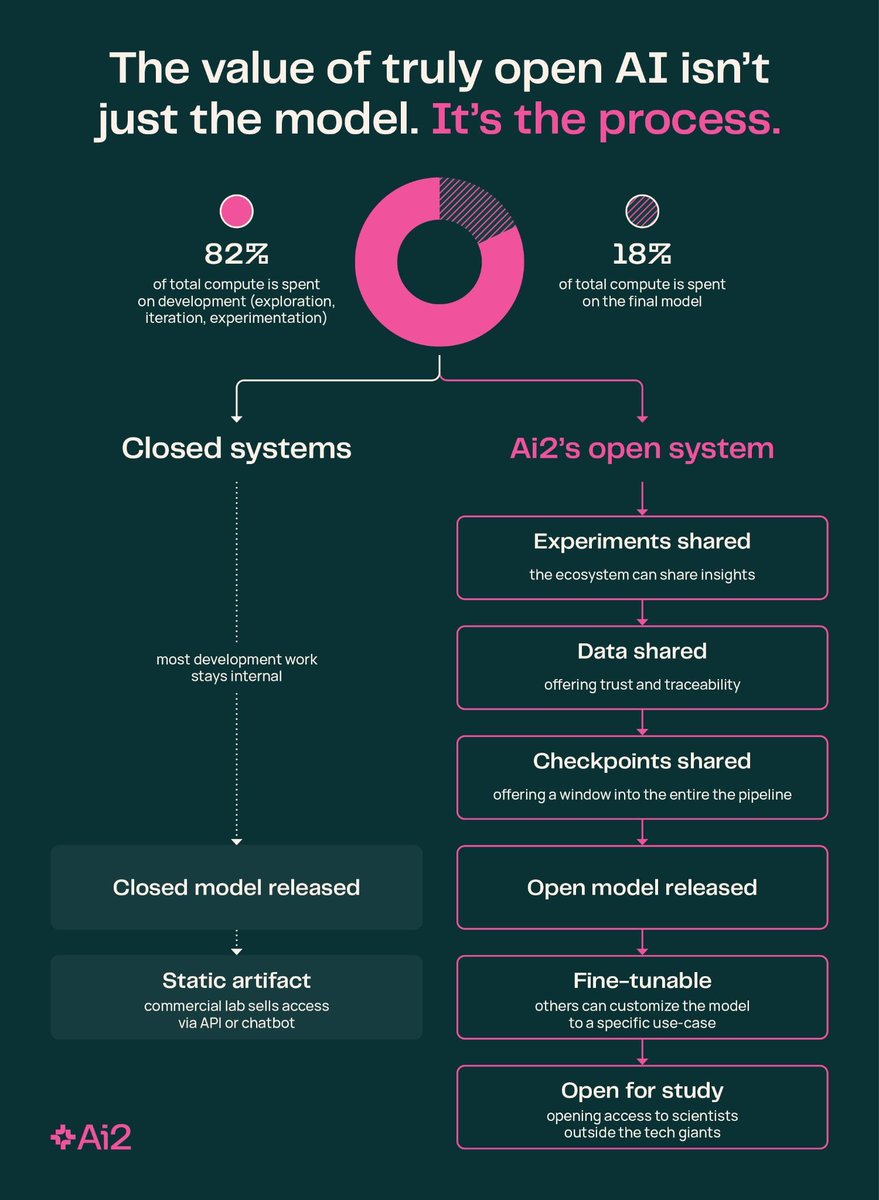
Today we’re bringing new NSF OMAI compute online with NVIDIA Blackwell Ultra-powered systems, turning a $152M national investment from @NSF & @NVIDIA into a foundation for truly open AI research. 🧵