Sabitlenmiş Tweet

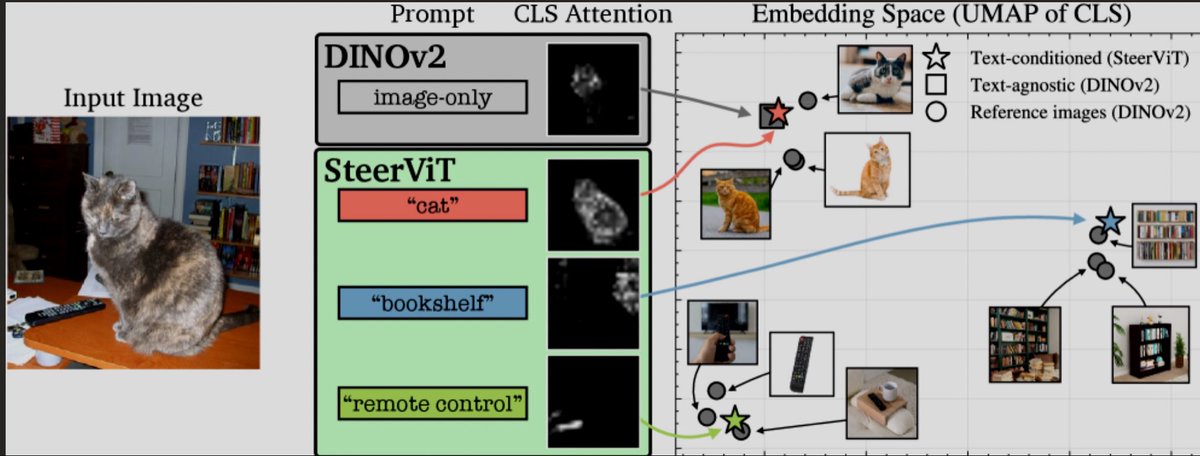
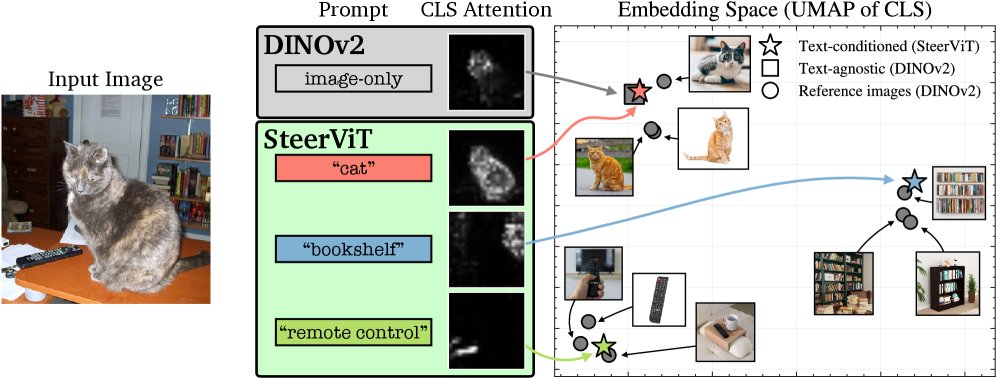
What if you could 𝘵𝘦𝘭𝘭 vision encoders 𝘸𝘩𝘢𝘵 to encode?
Check out our latest work where we introduce 𝗦𝘁𝗲𝗲𝗿𝗮𝗯𝗹𝗲 𝗩𝗶𝘀𝘂𝗮𝗹 𝗥𝗲𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻𝘀.
Manu Gaur@gaur_manu
Pretrained ViTs like DINOv2 or CLIP are great, but they produce fixed, generic representations that encode the most salient visual concepts (e.g., "cat"). In human vision, prior priming with language changes how people parse an image. We believe visual encoders should do the same 🚨 Introducing Steerable Visual Representations, a new family of visual features you can steer with text towards specific visual concepts.
English