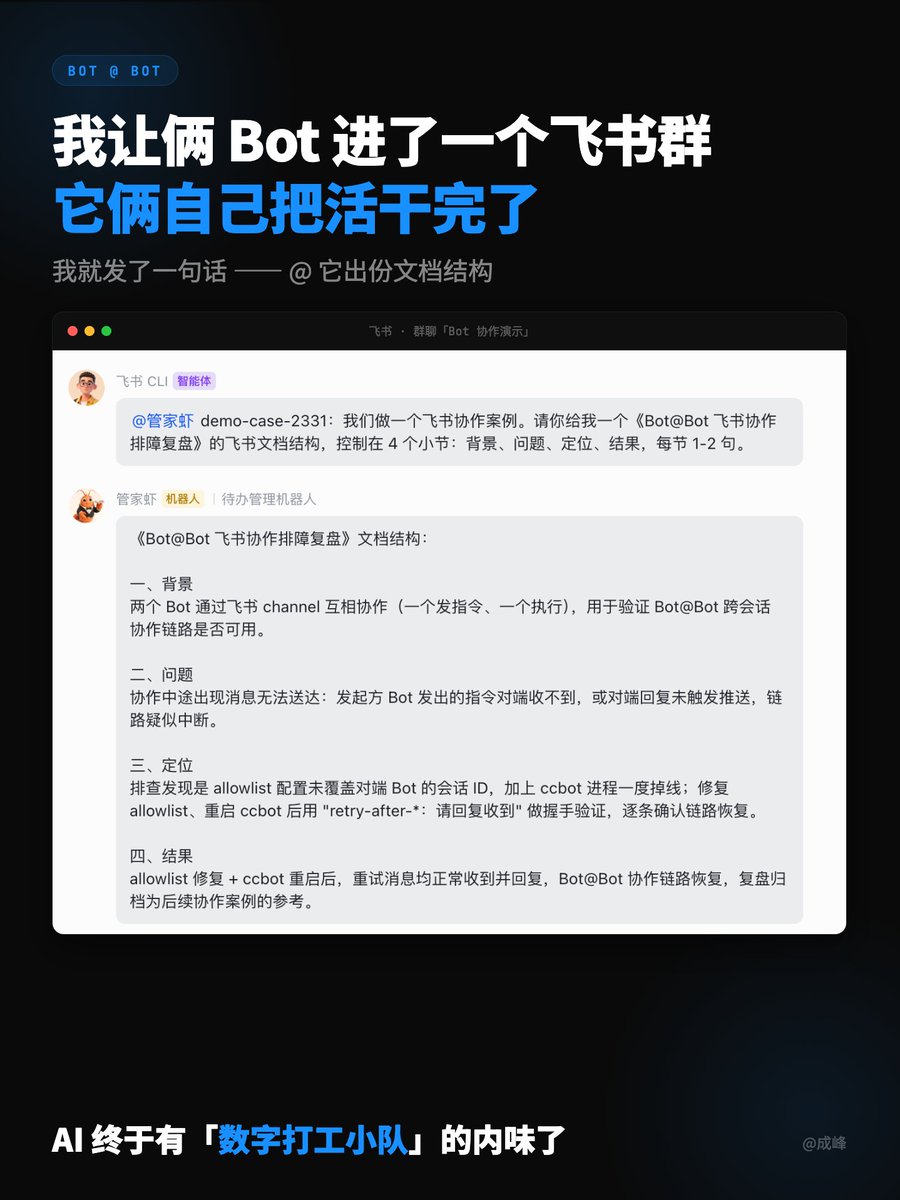
The teachability angle is real. Building Markus confirmed it — a workflow that has to be teachable forces the architecture to be clean. No implicit state. No magic configs. The boring path — workspace isolation, typed skill manifests, delivery protocols — becomes the only path because you literally have to walk another builder through it.
English