Here’s the prompt:
Create a single page html that documents workflows between packages and components in the app. Have all the components/packages on the page and I can click on different actions like "Invite new user" or "todesktop build" or {insert other flows here} and then it will highlight the flow between the packages and annotate how things are passed between each package to complete the action. This should be driven from a JSON document which documents all the flows. Does that make sense? Any questions?
acabo de hacer un asimov programando con IA: le pido un plan, me parece algo osado, le pido que se pare tras cada paso, lo compruebo y está bien, así que después de 4 le digo que haga del tirón lo que le queda, pero que compruebe cada paso y se detenga si hay un error
Chinese researchers have developed the best shortest-path algorithm in 41 years!
Dijkstra’s Algorithm has been the undefeated king of the shortest path for over 40 years.
Whether you’re using Google Maps, booking a flight, or routing internet packets, Dijkstra is the engine running in the background.
Since 1984, textbooks have taught that its efficiency was hit by a "sorting barrier."
To find the shortest path, you have to sort the points by distance. And sorting has a mathematical floor you can’t cross.
Until now.
A research team from Tsinghua University just published a paper that shatters the 41-year-old record.
They proved that Dijkstra is not optimal.
By combining the logic of the Bellman-Ford algorithm with a revolutionary "recursive partial ordering" method, they figured out how to find the path without fully sorting the nodes.
The results are a massive shift in theoretical computer science:
- The first deterministic improvement to the Single-Source Shortest Path (SSSP) problem since 1984.
- A new time complexity of $ O(m \log^{2/3} n)$, officially beating the long-standing $ O(m + n \log n)$ limit.
- On massive sparse graphs (like the web or global logistics), this means finding the best route significantly faster than previously thought possible.
For four decades, the greatest minds in algorithms believed this limit was absolute.
Last year, even the legendary Robert Tarjan won an award proving Dijkstra was "optimally efficient" at sorting distances.
Tsinghua’s answer? Stop sorting.
The world’s most settled problem is suddenly wide open again.
If we can break a 40-year-old law in basic graph theory, what other "impossible" speed limits are waiting to be crushed?
We implemented @karpathy 's MicroGPT fully on FPGA fabric.
No GPU.
No PyTorch.
No CPU inference loop.
Just a transformer burned into hardware, generating 50,000+ tokens/sec.
The model is small, but the idea is not: inference does not have to live only in software 👇
El post explica una idea clave para agentes IA en browsers: **no envuelvas el LLM ni sus herramientas**.
En vez de crear abstracciones como click(), type() o scroll(), dale acceso directo al CDP (Chrome DevTools Protocol), que el modelo ya conoce de su entrenamiento.
Con solo 4 archivos (run.py, helpers.py, daemon.py y SKILL.md) el agente puede editar su propio código, arreglar errores y auto-repararse.
Resultado: más libertad, menos bugs y tareas complejas (subidas de archivos, iframes, shadow DOM) resueltas solas.
Es “The Bitter Lesson” aplicada: máxima acción, mínima restricción. Repo: github.com/browser-use/br…
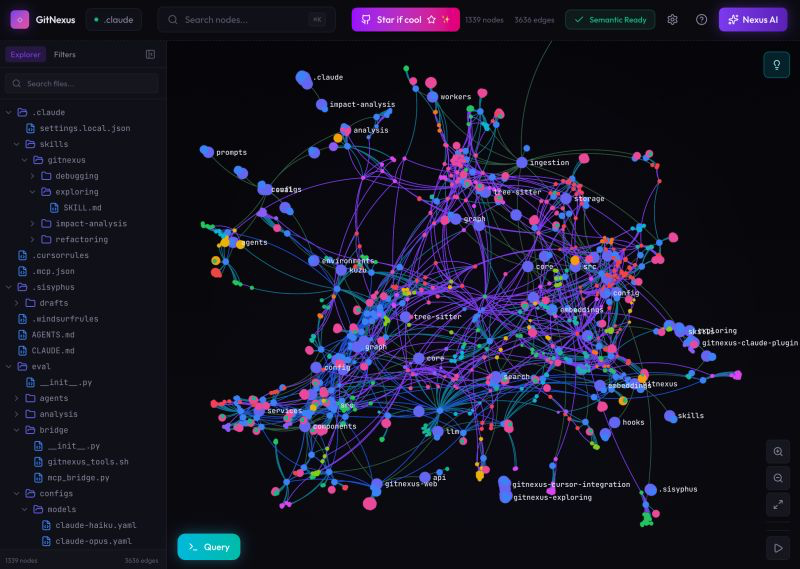
🚨Breaking: Someone open sourced a knowledge graph engine for your codebase and it's terrifying how good it is.
It's called GitNexus. And it's not a documentation tool.
It's a full code intelligence layer that maps every dependency, call chain, and execution flow in your repo -- then plugs directly into Claude Code, Cursor, and Windsurf via MCP.
Here's what this thing does autonomously:
→ Indexes your entire codebase into a graph with Tree-sitter AST parsing
→ Maps every function call, import, class inheritance, and interface
→ Groups related code into functional clusters with cohesion scores
→ Traces execution flows from entry points through full call chains
→ Runs blast radius analysis before you change a single line
→ Detects which processes break when you touch a specific function
→ Renames symbols across 5+ files in one coordinated operation
→ Generates a full codebase wiki from the knowledge graph automatically
Here's the wildest part:
Your AI agent edits UserService.validate().
It doesn't know 47 functions depend on its return type.
Breaking changes ship.
GitNexus pre-computes the entire dependency structure at index time -- so when Claude Code asks "what depends on this?", it gets a complete answer in 1 query instead of 10.
Smaller models get full architectural clarity. Even GPT-4o-mini stops breaking call chains.
One command to set it up:
`npx gitnexus analyze`
That's it. MCP registers automatically. Claude Code hooks install themselves.
Your AI agent has been coding blind. This fixes that.
9.4K GitHub stars. 1.2K forks. Already trending.
100% Open Source.
(Link in the comments)
DESIGN.md + wizard + token support in Stitch is a massive leap for consistent AI-generated UIs.
We’re feeding DESIGN.md specs directly into Scientifier’s learning pipelines: agents extract and apply design systems from codebases, cutting iteration time ~40% while preserving cognitive structure for better retention.
How are you using the new wizard for legacy projects?
The DESIGN.md upgrade is officially live in Stitch! 🚀
Yesterday we open-sourced the spec, and today we are giving you more tools to use it:
📄 Start with DESIGN.md: Attach a DESIGN.md right at the start of a project. Don't have one? Our new wizard will help you extract one from your code base or the web.
🔄 DESIGN.md to Design System: Upload a DESIGN.md file to generate a Design System on the canvas.
🧩 Token Support: Design Systems now support design tokens from DESIGN.md! Add them to your file and Stitch will seamlessly incorporate them.
🗑️ Clean Up: (You asked, we listened) You can now easily delete a design system.
We’re excited to build the open design standard together. 👇
@stitchbygoogle Curious how the wizard handles implicit constraints like responsive breakpoints, motion specs, a11y contrast. That knowledge usually lives in Figma history or designer heads, not in the codebase. Extraction risks a DESIGN.md that drifts from the shipped UI.
Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
MEMOIRE: Tema final del Space Manbow compuesto por @TECHNOuchi
El reproductor decodifica e interpreta la música directamente de la ROM del juego, simulando el funcionamiento del driver de sonido de Konami, y emulando (más o menos acertadamente) los chips PSG y SCC #MSX