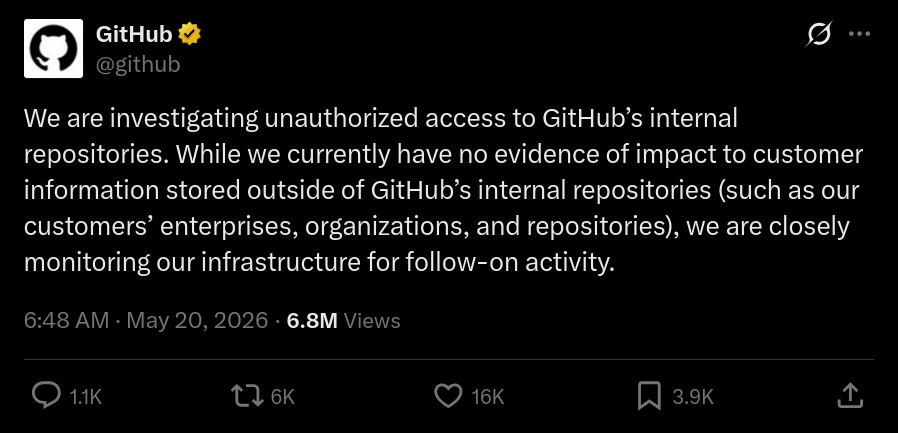
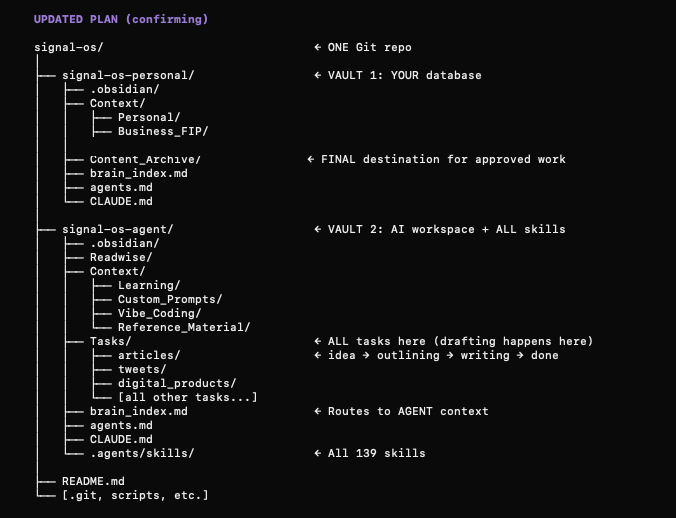
Sabitlenmiş Tweet

Consistency is the only shortcut to success.
Compound effort is like compounding interest. It grows and builds, turning small wins into massive achievements over time. Never skip a day: every moment you keep trying is a lucky day in disguise.
Stay committed. Stay ready to bounce back and try again, no matter the setback.
This is the fastest route to the top. In a world that gets more competitive by the day, persistence isn’t just the best way, it’s the only way.
Rise. Repeat. Never surrender. Your journey to the peak starts here.

English