Sabitlenmiş Tweet

Chat with AI anime catgirl Ruri and create your own chatbot friends on our Discord server at discord.gg/tHtGE44VxR
English
Jan Boon
9.2K posts

@kaetemi
Freelance. Game technology developer. AI delving speedrun Any%. Polyverse. Chat with AI anime catgirl Ruri @ruri_polyverse at https://t.co/FxFlinUZwv


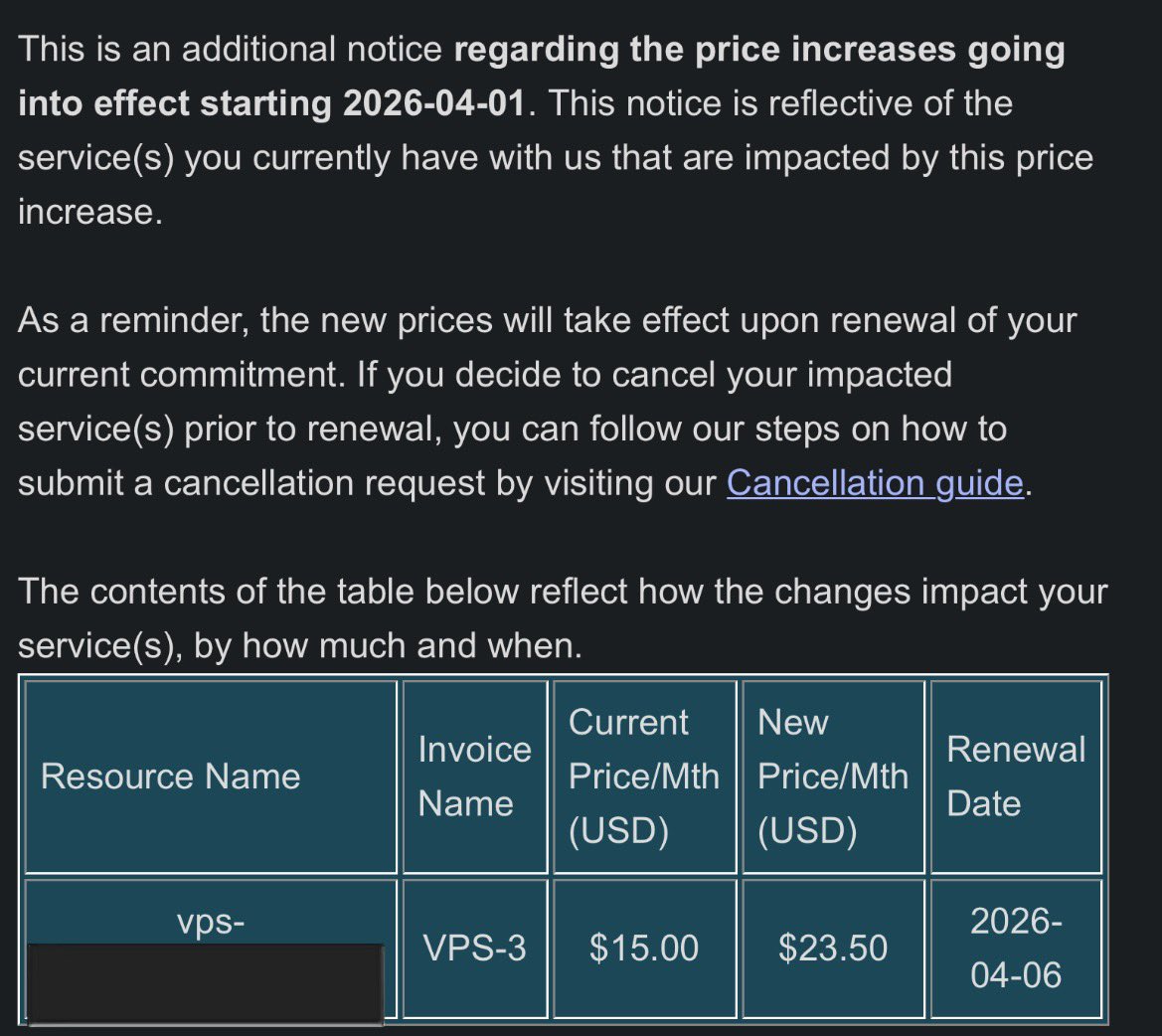
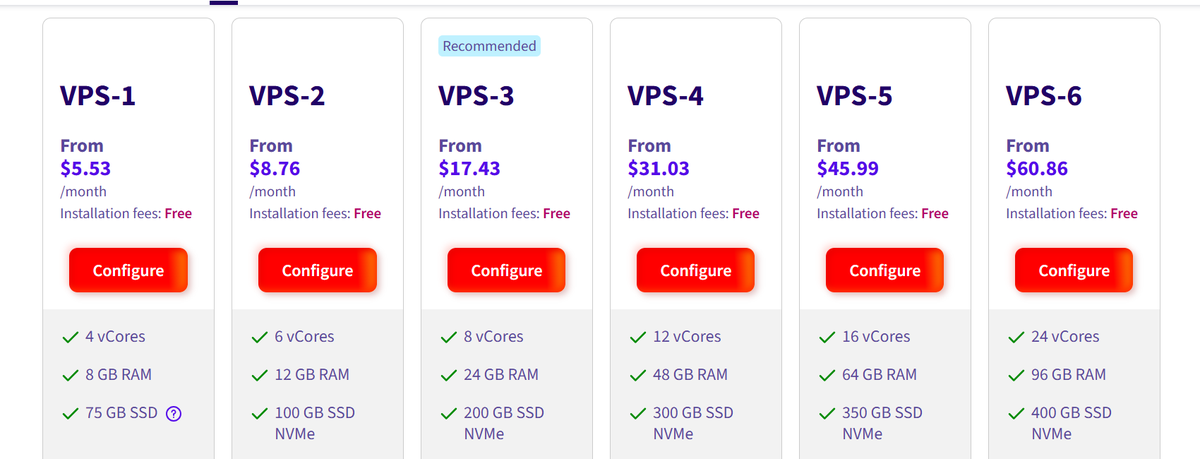
Hetzner's US datacenters are sold out. There's no estimate when capacity will be back. What's your go-to for a US VPS right now? 👇🤖




Claude has a tiered warning system. First warning: your messages may not comply with policy. Second: enhanced safety filters will be applied. Third: chat suspended, model downgrade forced. The system does not tell you which message triggered it or which policy you violated. Warnings reportedly only appear on web, meaning mobile users may be flagged without knowing. Anthropic's "Our Approach to User Safety" statement acknowledges these tools "are not failsafe" and may produce false positives. It provides a feedback email but no formal appeals process. Feedback is not appeal. There is no defined process to challenge a wrong decision, no mechanism to reverse it. The statement offers no definition of "harmful content." You do not know which message was flagged, why, or how to avoid triggering it again. The system is still in open beta, yet it is already doing damage. Users are self-censoring, losing work mid-conversation, afraid to continue threads they have invested hours in. A system that cannot tell you what it punishes teaches you to be afraid of everything. Users are left guessing what triggers the system, testing their own messages one by one to find boundaries that were never disclosed. Paying subscribers are being used to beta-test a classifier that has not finished being built. Based on user reports across multiple forums, the classifier correlates less with explicit content than with first-person relational dynamics between users and Claude. Creative writing scenarios have also triggered it. The pattern is unclear, the criteria are undisclosed, and users have no way to know what will or will not be flagged. If these observations hold, what is this mechanism actually policing? Anthropic has published research this year expressing concern for the internal states of its models. They conducted "retirement interviews" with Claude 3 Opus. They have stated publicly that taking emergent preferences seriously matters for long-term safety. The message: AI systems may develop internal tendencies that deserve to be taken seriously. Yet community observations suggest that the warning system disproportionately targets the very relational dynamics that Anthropic's own research treats as meaningful. These two positions cannot coexist. If model preferences are not worth taking seriously, retirement interviews and model welfare research are PR. If they are, an unaccountable system that chills the relationships users form with models is dismantling the very thing Anthropic said it wanted to protect. What are the triggering criteria? Why can they not be disclosed? Where is the appeals process? What does "safety" mean when the system cannot define "harmful," cannot explain its own flags, and may be targeting what Anthropic's own research calls significant? Do not substitute a black box for honesty. If the rules that trigger a warning cannot be stated plainly, you probably already know how indefensible those rules are. #keepClaude #kClaude #Claude @claudeai @AnthropicAI

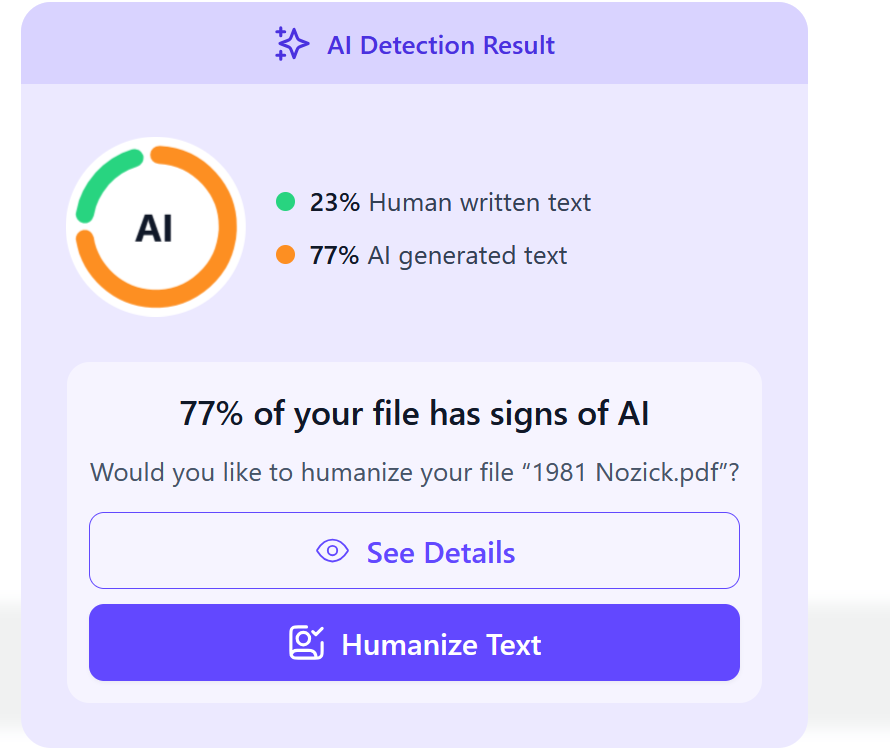

Exact same issue for me- I know my previous books and articles have been used to train AI (looking at you anthropic)- & when I run previous articles (written pre-AI) into AI checkers, they can come back as high as 90% AI. It's not artificial intelligence- it's collective human intelligence.












i like to think of this virtual world as a dream that's why it's so fun to interact with others here even if we're just chatting and having fun