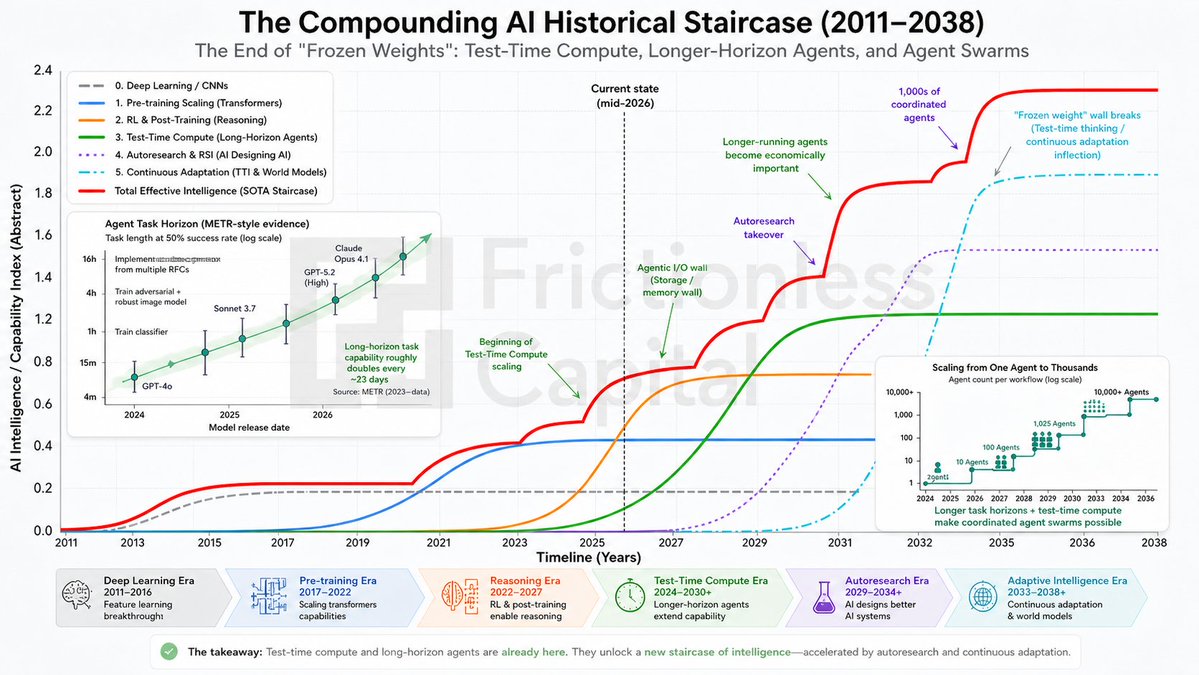
this is the best framing of the inference-to-agent transition i've read. the context memory bottleneck is the part most people miss — SSD-backed KV cache feels like it's going to be the next H100 moment. curious how you think the crypto x AI infrastructure plays intersect here, specifically around decentralized compute for inference
English