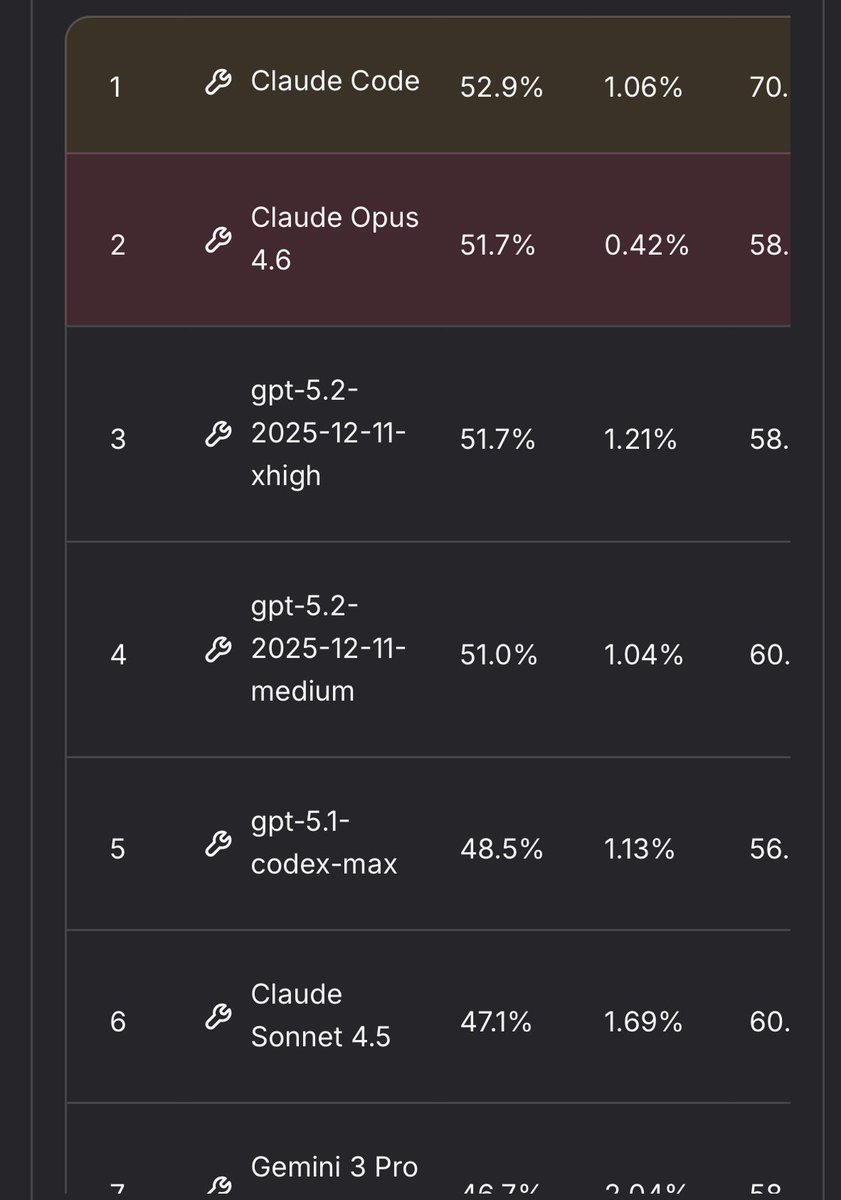
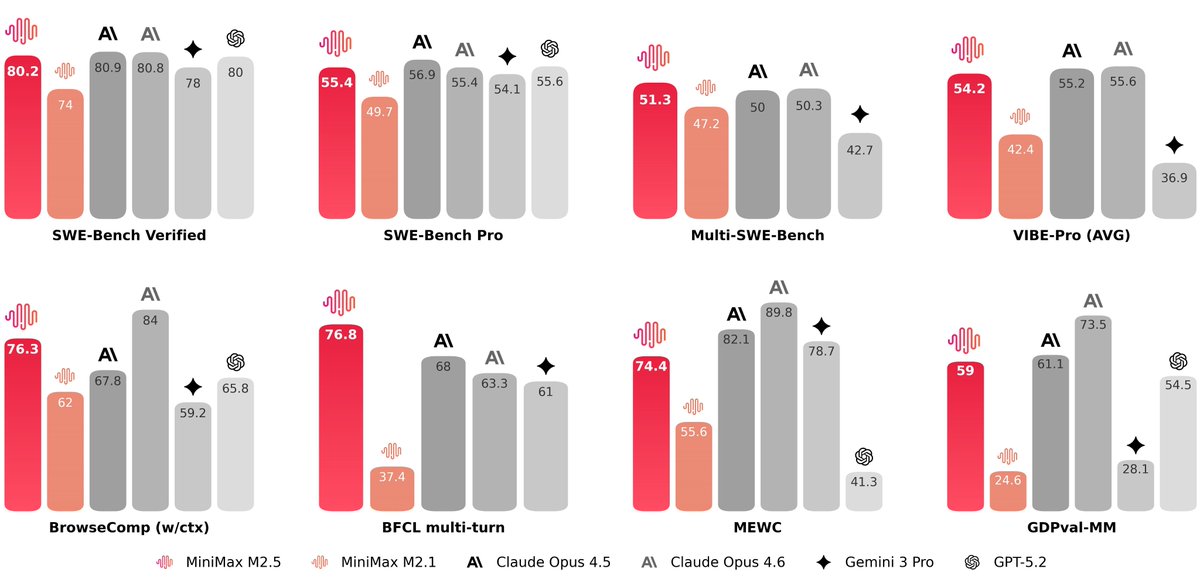
Sabitlenmiş Tweet

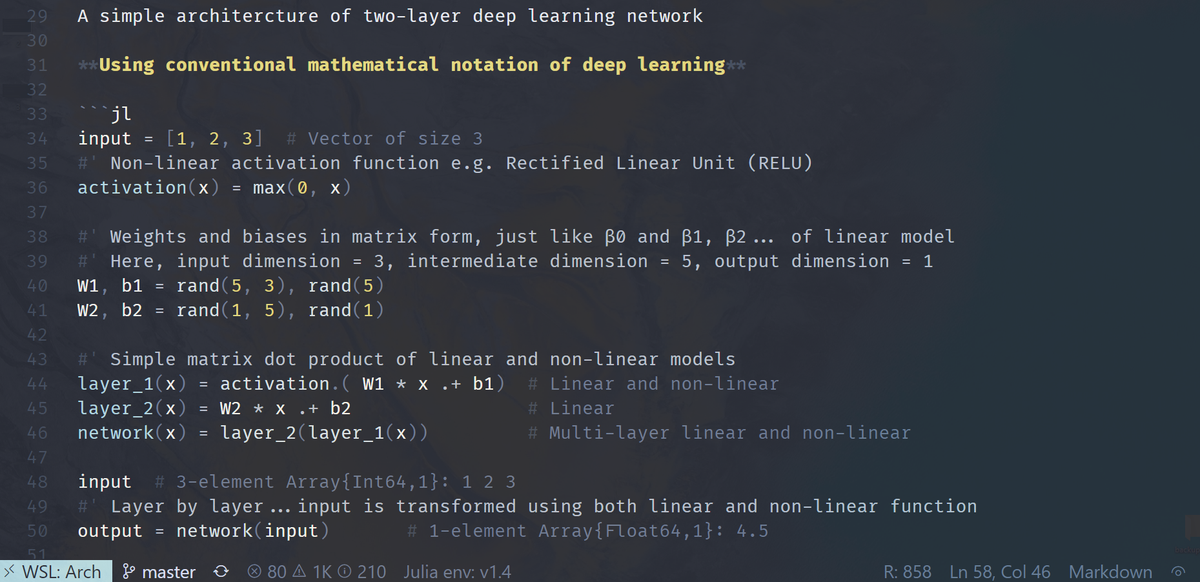
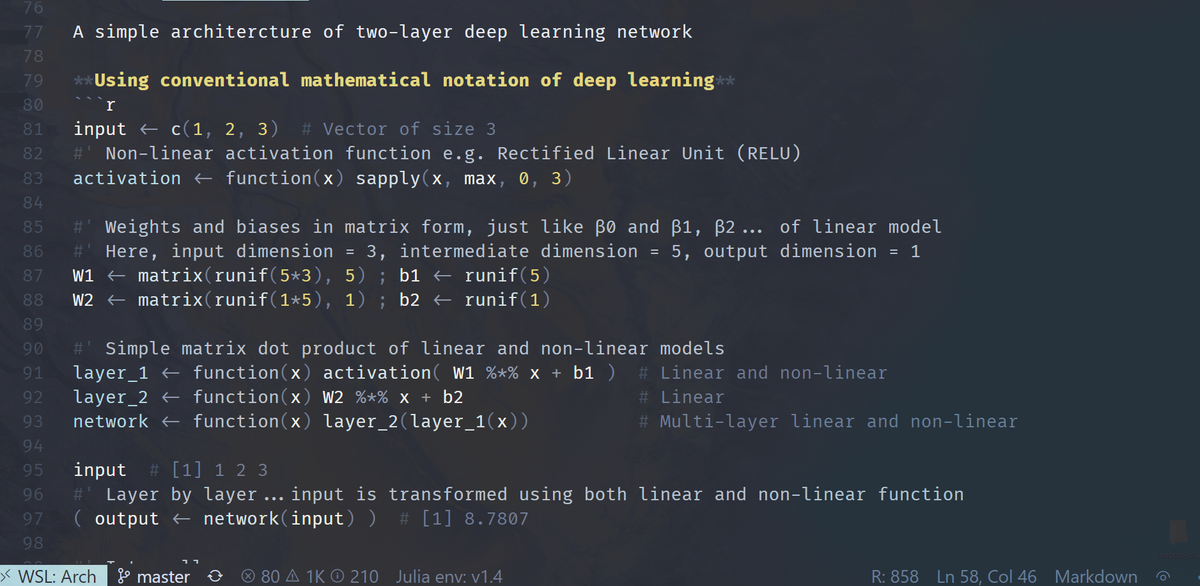
Linear representation is the foundation of most, if not all, models, including architecture of deep learning
Feel free to see it in simple codes I shared for both #julialang and #RStats. You can play around with it too
See images and link: gist.github.com/kar9222/82c767…

Women in Statistics and Data Science@WomenInStat
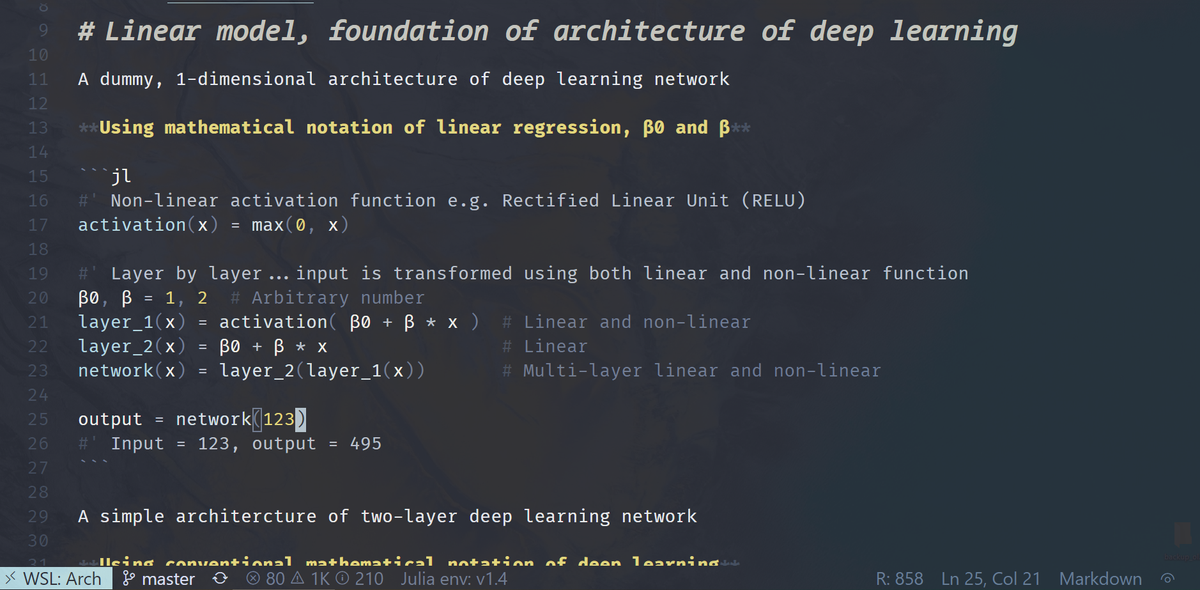
How about deep learning? Super non-linear, right? Well, as a function of some non-linear activations, it's IJALM. You can put lipstick on a linear model, but it’s still a linear model. Fit it w/least squares … w/ bells & whistles like dropout, SGD, & regularization. 11/
English