Where in the world can you find a senior government leader with a personal AI stack published on GitHub?
How many would be willing to talk about it in a room full of builders?
Which is why we are so incredibly honoured to welcome Singapore’s Minister for Foreign Affairs, Dr Vivian Balakrishnan, to the lineup of speakers for @aiDotEngineer Singapore.
A few weeks ago, Minister Balakrishnan casually dropped a technical writeup of his personal AI system online.
Raspberry Pi. Claude. Local embeddings. Knowledge graphs. A full architecture breakdown.
And the global AI community noticed because it reflected something bigger: a willingness to engage with these systems directly, publicly, and practically.
To kick off AIE Singapore, Minister Balakrishnan will share his experience experimenting with open-source AI tools and building a “second brain” workflow, alongside broader reflections on how AI may reshape global dynamics, and the way people work, think, and manage information.
In a role that demands navigating enormous volumes of information and constant context-switching, his reflections will set the tone for the conference in exactly the way we hoped:
That meaningful conversations about AI should not stay abstract.
They should involve understanding its parameters through practical engagement with the technology.
And that Singapore has become the place where that kind of engagement happens seriously.
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow.
Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes.
As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now.
It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
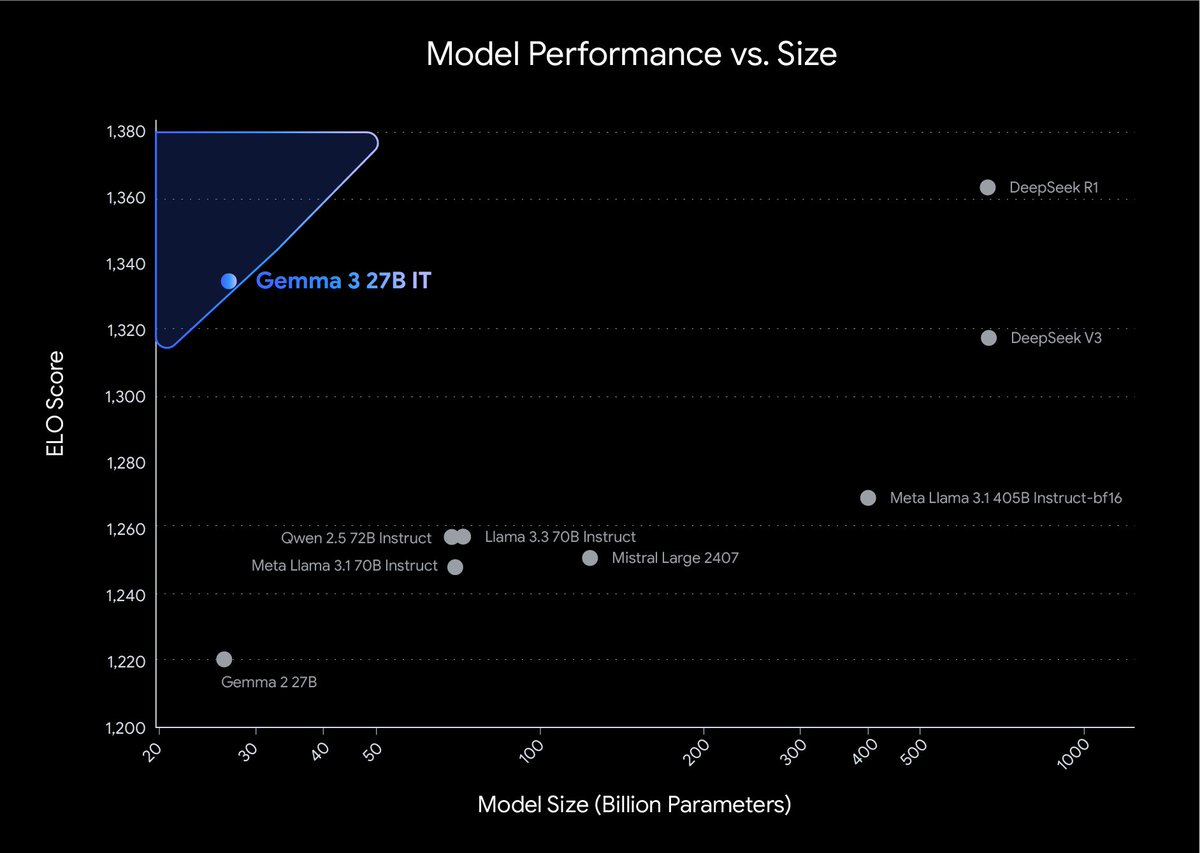
I’m so happy to announce Gemma 3 is out! 🚀
🌏Understands over 140 languages
👀Multimodal with image and video input
🤯LMArena score of 1338!
📏Context window of 128k
Available in AI Studio, Hugging Face, Ollama, Vertex, and your favorite OS tools 🚀Download it today!
developers.googleblog.com/en/introducing…
We are excited to share Reka Flash ✨, a new state-of-the-art 21B multimodal model that rivals Gemini Pro and GPT 3.5 on key language & vision benchmarks 📈.
We've trained this model from scratch and ground zero with a small (but amazingly capable team 🧙♂️) and relatively finite resources. We're amazed at how strong it is 🦾. I'm proud of our financially optimal LLM team.
Abandoning one's comfort zone is surely difficult and having to redo things from scratch is often scary & daunting. Many things in the wilderness don't work from the get go and it was often a huge pain in the neck 😢.
I should write a separate post someday of how much we have we've had to rebuilt (and suffered 🤣). Everything from robust training infra, proper (human) evaluation pipelines and proper RLHF setups. I am thankful of the crazy talented team we have here ☺️.
Meanwhile, our largest most capable model Reka-Core is finishing soon and we're already very excited by early results 📈. More to come very soon!
9 months in. Excited to be back at the frontier 🔥.
Check out our blogpost here: reka.ai/reka-flash-an-…
We just released LLaMA-2-7B-32K, a 32K context model that can be fine-tuned for tasks like doc understanding, summarization & QA!
Built with Position Interpolation & our data recipe/optimizations, run inference & fine-tune with up to 3x speedup.
Thread👇
together.ai/blog/llama-2-7…
Yesterday morning I was happy with myself inferencing llama2.c 10M param model at 18tok/s. This morning people in the PRs are running it at 3000+ tok/s by compiling a little different. Yesterday I kicked off a 44M train run to try slow it down. Now upgrading to GPT-1 sized ~110M.
At STACK x DATA & AI today. I think it says a lot about Singapore’s approach to new things. Try try try. Start small, keep risks low and try! If you have not tried out generative AI. Check them out: bard.google.com, openai.com/chatgpt, midjourney.com.
I'm calling the Myth of Context Length:
Don't get too excited by claims of 1M or even 1B context tokens. You know what, LSTMs already achieve infinite context length 25 yrs ago!
What truly matters is how well the model actually uses the context. It's easy to make seemingly wild claims, but much harder to solve real problems better.
I highly recommend "Lost in the Middle: How Language Models Use Long Contexts" from Stanford. It's jam-packed with rigorous experiments that put popular long-context models to test. Key findings:
▸ Figure 1 (left): models are good at using information located at the very beginning or end of its context, but significantly worse at the middle. This isn't unique to GPT architecture - encoder-decoder like Flan-T5 also suffers in the middle
▸ Figure 2 (right): models that are natively longer context do NOT actually use the context better. You can see that the curves of GPT-3.5 (4k vs 16k) almost completely overlap.
▸ Model performance substantially decreases as input contexts grow longer, regardless of their native length.
We don't need more tokens. We need models that actually pay attention to them (pun intended).
🦜 LLM Lit Review 🦜
Over the last two weeks, we tweeted out twelve papers we love in the world of language modeling, from agent simulation and browser automation to BERTology and artificial cognitive science.
Here they are, collected in a single 🧵 for your convenience.
New code walkthrough on keras.io: gradient centralization, a simple trick that can markedly speed up model convergence. Implemented in Keras in literally 10 lines of code.
Don't miss it: keras.io/examples/visio…
Gravity uses IBC protocol to enable swaps and pools of digital assets between any two blockchains and achieves superior efficiency compared to other AMMs due to its groundbreaking Equivalent Swap Price Model. #gravitydex, #trading, @cosmos, $Atom gravitydex.io