
Bea C.
145 posts

Bea C.
@klebea
Bioinformatics Scientist | UCI-trained PhD | Fmr. Harvard Fellow | Cat enthusiast | Genomics, Science | CCFC | Dodgers | Ducks ✧Faber est suae quisque fortunae✧
Katılım Temmuz 2009
1.1K Takip Edilen264 Takipçiler
Then she sat her, took the ball out of her hand, kept her to 21
KD@kds5140
17 points & 6 assists in 14 minutes….
English
Bea C. retweetledi

Bea C. retweetledi

You hear the term “hyperparameter” all the time in machine learning.
But do you really know what it means—and why it matters?
Let’s break it down.

English
No, it wasn't a stupid question. It was a simple question, and she proved that she can never encourage Caitlin to play an outlier game style. She can never. It was the simplest question.
"What was your thoughts on the resilience from her?"
She swung it to the team.
DamonG@DamonG89403665
It was a stupid question with an obvious answer and she shifted the response because she's over the unnecessary drama that comes with coaching John McEnroe with a jump shot. Steph has to coach the entire team, not 1 player and her response is shifting the focus to the team.
English
@2025FeverFan @chloepeterson67 Accuracy matters. These are official stats, not fan favors. If two assists were missed, they should be corrected. Simple.
English

@klebea @chloepeterson67 Why are so many fans on here obsessed with this? Do you do the same when she gets credit for an assist she didn't deserve?
English

Steph White on Aliyah Boston's lower leg injury: "I don't have any information on that. I haven't spoken to our medical staff yet."
English
Bea C. retweetledi

Bea C. retweetledi

Bea C. retweetledi

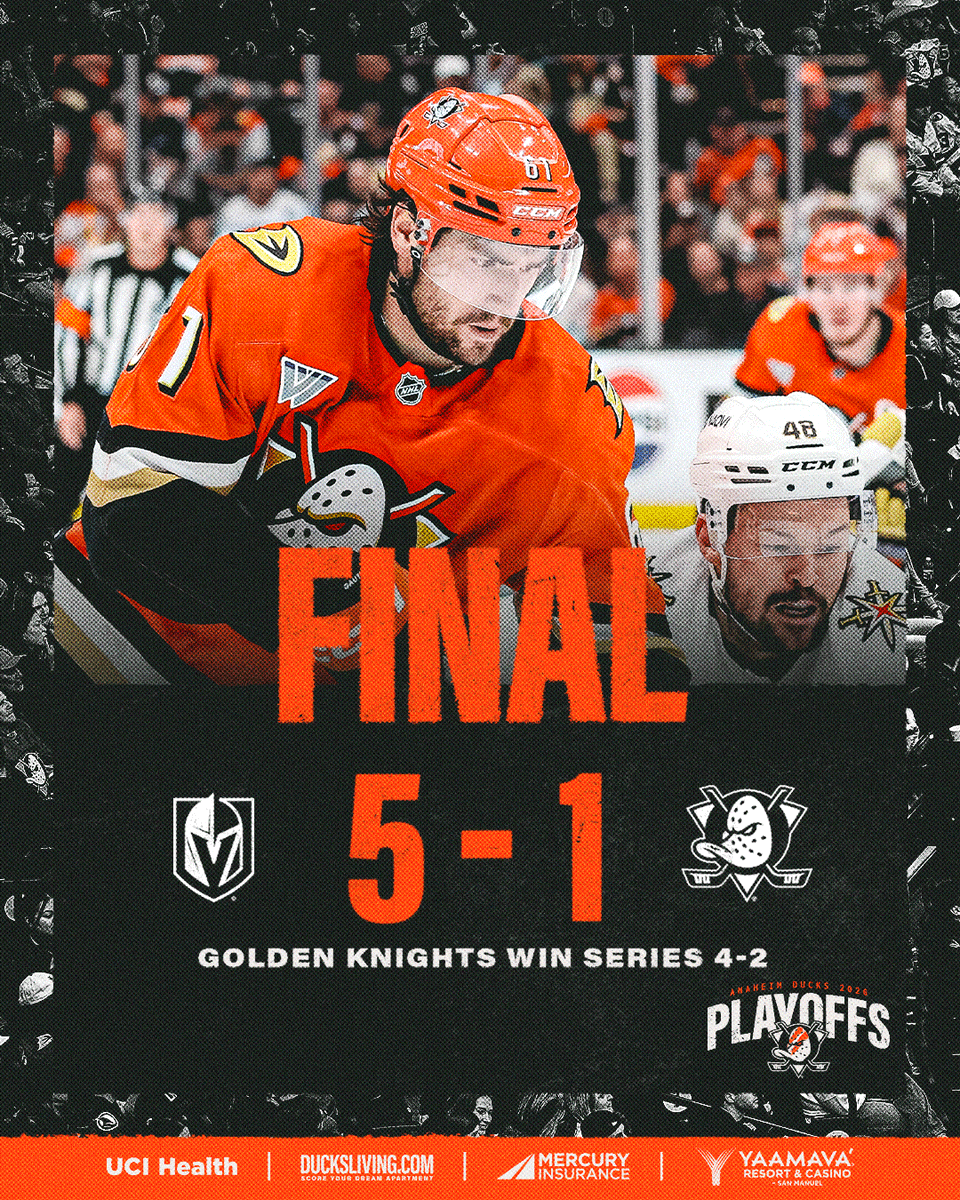
BECKETT SENNECKE IS FLYING IN ANAHEIM 🦆
He now has 5 goals this postseason, tying the Ducks rookie record originally set by Bobby Ryan in 2009 🚨

ESPN@espn
SENNECKE GETS THE SCORING STARTED FOR THE DUCKS 🦆 Watch Ducks-Golden Knights on ESPN and the ESPN App 🍿
English
Bea C. retweetledi

Bea C. retweetledi

Bea C. retweetledi
Bea C. retweetledi

The Fever have agreed to terms with nine-year vet and former Valkyries forward Monique Billings, per @TonyREast.

English
Bea C. retweetledi
Bea C. retweetledi

Excited to announce a new open-source, free-to-use memory tool I have been developing with my good friend @MillaJovovich.
The project is called MemPalace and it is an agentic memory tool that scored 100% on LongMemEval - the industry standard benchmark for memory… this is higher on than any other published results - free or paid - and it is available now on GitHub.
You can check out Milla’s video about it on her Instagram.
I’ll also put some links in the comments below - please try it out, critique it, fork it, contribute to it - and join our discord.
English
Bea C. retweetledi

LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Bea C. retweetledi


Bea C. retweetledi

This, paired with the pyramid scans, sits firmly in 'we need more data' territory.
Anyone instantly confirming *or* dismissing it is letting their priors do the archaeology.
New York Post@nypost
Second sphinx buried under sand suggests 'megastructure' below the Pyramids of Giza trib.al/J88qABu
English
Bea C. retweetledi

Our new essay is out in Science: "Agentic AI and the Next Intelligence Explosion"
For decades, the AI "singularity" has been imagined as a single, godlike mind bootstrapping itself to omniscience. In this piece with the inimitable Benjamin Bratton (@bratton) and Blaise Agüera y Arcas (@blaiseaguera), we argue this vision is wrong in its most fundamental assumption.
Every prior intelligence explosion—primate sociality, human language, writing, institutions—wasn't an upgrade to individual cognitive hardware. It was the emergence of a new socially aggregated unit of cognition. AI is extending this sequence, not breaking from it.
The evidence is already inside the models themselves. In recent work, we showed that frontier reasoning models like DeepSeek-R1 don't improve by "thinking longer"—they spontaneously simulate internal multi-agent debates, what we call a "society of thought" (lnkd.in/guNfRtXh).
Reinforcement learning for accuracy alone causes models to rediscover what epistemology and cognitive science have long suggested: robust reasoning is a social process, even within a single mind.
This opens a vast design space. A century of research on team composition, hierarchy, role differentiation, and structured disagreement has barely been brought to bear on AI reasoning. The toolkits of organizational science become blueprints for next-generation AI.
Outside the model, we've entered the era of human-AI centaurs—composite actors that are neither purely human nor purely machine. Agents that fork, differentiate, recombine. Recursive societies of thought that expand when complexity demands and collapse when problems resolve.
The scaling frontier isn't just bigger models. It's richer social systems—and the institutions to govern them. Just as human societies rely on persistent institutional templates (courtrooms, markets, bureaucracies), scalable AI ecosystems will need digital equivalents. The Founders would have recognized the logic: no single concentration of intelligence should regulate itself.
The intelligence explosion is already here. Not as a singular ascending mind, but as a combinatorial society complexifying—intelligence growing like a city. The question is whether we'll build the social infrastructure worthy of what it's becoming. No mind is an island.
Read it here in Science (science.org/doi/10.1126/sc…) or free on the arXiv (arxiv.org/abs/2603.20639)

English
Bea C. retweetledi

What a lovely surprise this morning! ☀️Independent detections of similar transients in European plate archives — exactly the kind of cross-validation this field needs. So it’s not just Palomar anymore.
The study was carried out by a retired NASA scientist.
This is how a signal begins to emerge from the noise.
arxiv.org/pdf/2603.20407

English