
chan
352 posts

chan
@kohdified
Co-Founder and Product @FilereadAI Currently heads down building and hiring!
New York, USA Katılım Aralık 2018
582 Takip Edilen161 Takipçiler


@R44D Harvey's selling the right for firms to tell their clients that they're buying Harvey
English

i've never understood harvey's biglaw strategy.
firms adopted it. rates went up 12%. utilization stayed low.
that's not a coincidence. you can't sell efficiency to someone who profits from inefficiency
Zack Shapiro@zackbshapiro
English
@YichuanM @IAmAaronYang @LiorOnAI This is very interesting. Do you have any insights into how you handle hybrid search approaches where the queries may need to use keywords + metadata?
English

@IAmAaronYang @LiorOnAI That’s a great question! You can refer to our paper for detailed evaluation. arxiv.org/pdf/2506.08276 tldr: we can save 50x storage while incurs less than 10% e2e latency overhead in RAG, and this is especially suitable for low frequency queries scenarios
English

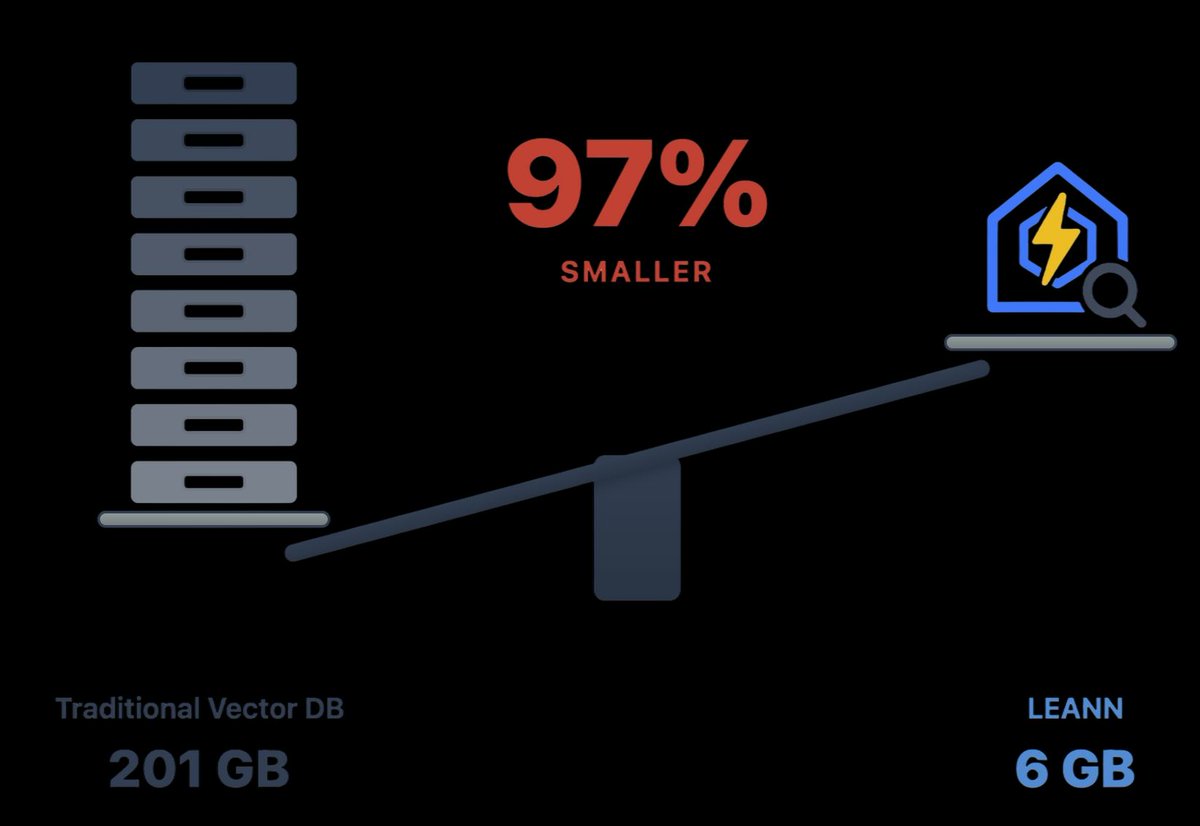
Stop storing embeddings.
A laptop can now index 60 million text chunks using 6GB, not 200GB.
LEANN, a new open-source project flips how vector search works.
𝗧𝗵𝗶𝘀 𝗶𝗻𝗱𝗲𝘅 𝗱𝗼𝗲𝘀 𝗻𝗼𝘁 𝘀𝘁𝗼𝗿𝗲 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀
Instead of saving every vector, it stores a compact graph.
Embeddings get recomputed only when a query actually needs them.
• Graph-based selective recomputation
• High-degree node pruning to keep recall stable
• No accuracy drop versus FAISS-style indexes
𝗧𝗵𝗲 𝘀𝘁𝗼𝗿𝗮𝗴𝗲 𝗴𝗮𝗶𝗻𝘀 𝗮𝗿𝗲 𝗺𝗮𝘀𝘀𝗶𝘃𝗲
Email archives shrink from gigabytes to megabytes.
Browser history fits in single-digit MBs.
A 60M-document corpus fits on a laptop SSD.
𝗜𝘁 𝗿𝘂𝗻𝘀 𝗲𝗻𝘁𝗶𝗿𝗲𝗹𝘆 𝗹𝗼𝗰𝗮𝗹
No cloud calls. No telemetry.
Everything stays on-device with zero ongoing cost.
𝗜𝘁 𝘂𝗻𝗹𝗼𝗰𝗸𝘀 𝗹𝗼𝗰𝗮𝗹 𝗥𝗔𝗚 𝗮𝘁 𝗻𝗲𝘄 𝘀𝗰𝗮𝗹𝗲
You can semantically search files, emails, chats, codebases, and live MCP sources.
All from one local index, without changing your workflow.
English


💥 Pitch your startup:
- Max 6 words
- Add your link
Seen by 50,000 people last week.
Yes, it counts as marketing, go!🚀
English

chan retweetledi


I got rejected by 144 investors before raising $150M for my $200M+ rev/year startup.
After 144 rejections, I started questioning our approach.
Were we solving the right problem?
What were we doing wrong?
Why weren’t investors seeing what we were seeing?
Were we the right team to build this?
We tried everything: different pitch angles, new deck structures, and reframing the problem.
Then came the 145th meeting, where we closed our first growth round.
That yes made everything worth it. But getting there took years of mistakes and hard work.
We went through a lot of trial and error just to figure out what resonates with investors.
We tried dozens of approaches to figure out what made investors engage.
Some landed, most didn't. But each iteration taught us something about what builds conviction versus what just sounds good on paper.
And once we cracked that code, our Series C closed faster than expected.
And today, I see so many founders in the exact same position I was in 10 years ago: grinding through rejections, questioning everything, and trying to figure out what works.
So today I want to give you the resource I wish I had back then:
Something that shows you exactly how to structure these conversations and navigate the entire process
(because the fundraising cycle can be a big distraction and take a toll on you as a founder).
So I've partnered with Notion's Startups Team to create the essential fundraising resource that helps you avoid the mistakes that cost me years.
Here's what you are getting:
• The actual decks I used to raise $150M for Super[.]com (Series B, C)
• 50 real examples from funded startups like Eleven Labs and Artisan AI
• A searchable database of 10,000+ investors - angels, VCs, and accelerators you can reach out to immediately (this alone would take months to build manually)
• An AI-powered fundraising agent built into Notion with step-by-step prompts (no separate ChatGPT needed)
Want access?
• Like and share this post
• Comment "FUNDRAISE"
• Follow me so I can DM you the link
I'll send it over ASAP.
P.S.: If you are serious about fundraising (now or in the future), you should grab it right away.
English


Azure is down and so is half the internet.
The other half.
StatusGator is monitoring the situation. But our Early Warning Signals algorithm has detected unacknowledged issues at scores of services.

English

don't onboard new users.
don't increase revenue.
adam@theCTO
don’t announce anything. don’t take the early dopamine.
English
day in the life of a prompt engineer
how long until we get these videos?

English
chan retweetledi
@leebarnby @Dorialexander If you want to retrieve those w/ text, you need to decompose them into a form that can be searched via keywords (e.g. "Who are the CEO's direct reports and what are their titles in the org-chart?").
English

@Dorialexander Also why do you need advanced capabilities for understanding graphs and charts? They are just representing data and it would be better to deal directly with that and avoid the representation-decoding stage.
English

Not sure if it’s outdated but text RAG is completely unsolved. So is OCR. And so is the mythical chat with pdf.
jason liu@jxnlco
Text-based RAG is already outdated. The real competitive edge in AI is building systems that can actually understand charts, graphs, and images - not just text. If you're not learning Visual RAG now, you're already behind the curve in enterprise AI development.
English
English

announcing our $83M funding.
s/o to our great investors @a16z @BainCapVC @pebble_bed @AbstractVC @HF0Residency
read the story 👇
English

Well Vasek, you brought it up first, so I can't be blamed now! 😄 I was holding back from tagging you until Manus became more stable... But no worries everyone, any issues are totally on our end - @e2b is an amazing technology!
Vasek Mlejnsky@mlejva
If Manus was mentioned on cnbc showing the Manus's computer which is @e2b sandbox does it mean e2b was transitively on CNBC? 😆
English

Who are some underrated designers, developers & projects that deserve more recognition? Give them a shoutout 👇
English