Sabitlenmiş Tweet

questions will become more important than answers in the age of AI.
Mark. my. words.
English
Naveesh /looping
2.2K posts
@krapstarr
Indian firmware with American Operating System



Kimi K3 has received far more love than we expected, and our GPUs are feeling it. Over the past 48 hours, demand has pushed close to the limits of our current capacity. To protect the experience of existing subscribers, we're temporarily pausing new subscriptions and prioritizing compute for current members. Existing subscribed users are not affected. We're adding capacity as fast as we can and will reopen new subscription spots in batches. Going forward, we'll also split membership into two more focused plans: Kimi Membership for Kimi Web, App, and Work; and Kimi Code Membership for coding workflows. This will help us match compute more precisely and keep the experience stable. Thank you for your patience and understanding!




Qwen3.8 is launching and going open-weight soon!🌐 With a massive 2.4T parameters, this model is continuously evolving. We believe it’s one of the most powerful model available today, compatible to leading frontier AI models , second only to Fable 5. You don't have to wait to test it. Just now, the Qwen3.8-Max-Preview made its debut on Alibaba’s Token Plan, Qoder, and QoderWork. Be among the very first to try it out. Can't wait to hear what you build. Stay tuned! 🚀 Token Plan international:qwencloud.com/pricing/token-… China:platform.qianwenai.com/pricing/token-…

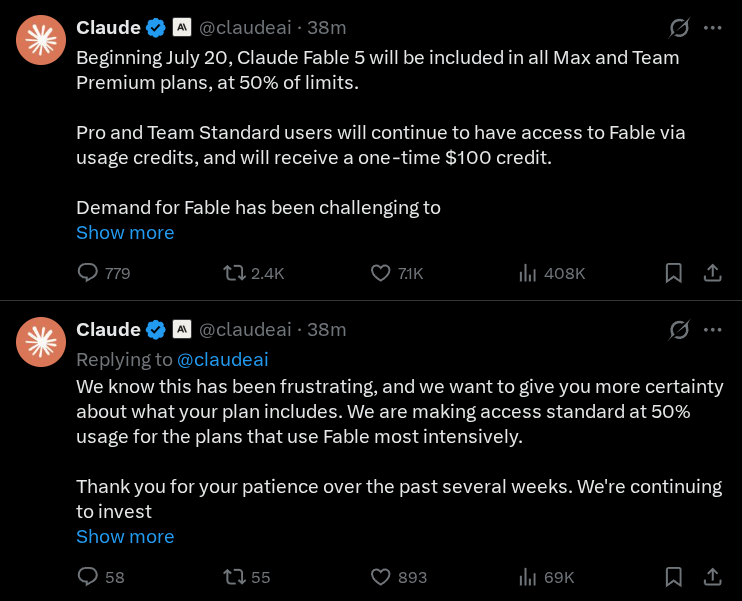
Beginning July 20, Claude Fable 5 will be included in all Max and Team Premium plans, at 50% of limits. Pro and Team Standard users will continue to have access to Fable via usage credits, and will receive a one-time $100 credit. Demand for Fable has been challenging to predict, which is why we rolled it out to subscription plans in stages, extending access several times as we secured additional capacity.



Beginning July 20, Claude Fable 5 will be included in all Max and Team Premium plans, at 50% of limits. Pro and Team Standard users will continue to have access to Fable via usage credits, and will receive a one-time $100 credit. Demand for Fable has been challenging to predict, which is why we rolled it out to subscription plans in stages, extending access several times as we secured additional capacity.

Fable at 50% discount... Kimi just gauranteed Anthropic won't remove Fable from Claude subs on July 19th 🤣 Can't wait to drive intellgence down even cheaper

Beginning July 20, Claude Fable 5 will be included in all Max and Team Premium plans, at 50% of limits. Pro and Team Standard users will continue to have access to Fable via usage credits, and will receive a one-time $100 credit. Demand for Fable has been challenging to predict, which is why we rolled it out to subscription plans in stages, extending access several times as we secured additional capacity.