
Arne Kvale
3.8K posts

Arne Kvale
@kvale_a
Seriegründer, 2 exits. Medgründer https://t.co/gqIlAHSpsb & https://t.co/aaVjJR4cic | Investor | Driver podcasten På innsiden 🎧
Oslo Katılım Kasım 2019
2.4K Takip Edilen3.4K Takipçiler


Krigen mot Iranske regimet er også vår krig. I dag avfyrte Iran et missil med rekkevidde på 4000km. Et slikt missil kan nå hele veien til Norge. Til Oslo. Og her i landet vårt har vi null luftvern. Vi er ubeskyttet for iranske angrep. Kanskje vi istedet burde begynne å spille litt mer på lag med Israel og USA?

Norsk
Arne Kvale retweetledi

🚨BREAKING: SUPER MICRO CO-FOUNDER ARRESTED FOR SMUGGLING $2.5B IN NVIDIA GPUs TO CHINA
>SMCI co-founder Yih-Shyan "Wally" Liaw arrested today
>personally holds $464 MILLION in SMCI stock
>charged with smuggling BILLIONS in Nvidia servers to china
>used a southeast asian shell company to funnel $2.5B in servers to chinese buyers
>$510 million worth shipped in just THREE WEEKS in spring 2025
>built thousands of fake dummy servers to fool U.S compliance auditors
>caught on surveillance camera using a HAIR DRYER to swap serial number stickers
>coordinated the whole thing over encrypted group chats
>SMCI down 12% after hours
>faces up to 30 years in federal prison
ITS SO OVER…

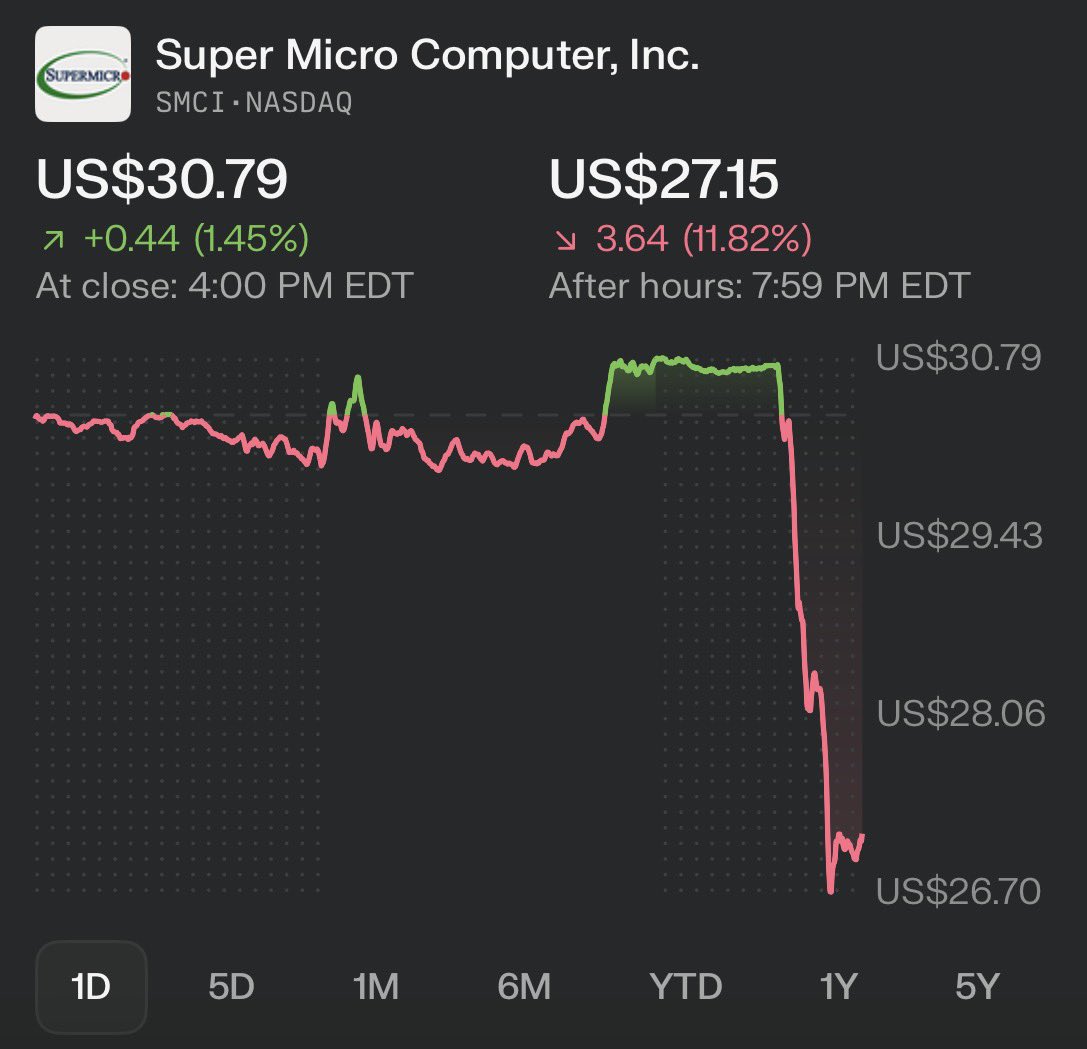
National Security Division, U.S. Dept of Justice@DOJNatSec
Three Charged with Conspiring to Unlawfully Divert Cutting Edge U.S. Artificial Intelligence Technology to China “The indictment unsealed today details alleged efforts to evade U.S. export laws through false documents, staged dummy servers to mislead inspectors, and convoluted transshipment schemes, in order to obfuscate the true destination of restricted AI technology—China,” said John A. Eisenberg, Assistant Attorney General for National Security. “These chips are the product of American ingenuity, and NSD will continue to enforce our export-control laws to protect that advantage.” 🔗: justice.gov/opa/pr/three-c…
English
@Shrimp_a_Whales @SamoskaPaulius @PaaInnsiden @JanOftedal3 @StigMyrseth Så den. Er vel gjerne slik at Musk vil snakke pent om Jensen da han ønsker prio på brikker :)
Norsk
Arne Kvale retweetledi

Ny episode #19 av @PaaInnsiden ute!
Verdt en lytt 🎙️👇
Takk @kvale_a @JanOftedal3 @StigMyrseth
Hilsener fra Lisbon!
PåInnsiden@PaaInnsiden
#EP19 av @PaaInnsiden er ute 🎙️ ◆ Iran krig - Hormuz, energi og globale ringvirkninger ◆ Taiwan, halvledere ◆ Friedrich Merz og EU-deregulering ◆ Yann LeCun og AMI Labs ◆ Cortical Labs – hjerneceller som spiller Doom ◆ And more! 👉 Spotify og YouTube link finner du i kommentarfeltet.
Norsk
@Shrimp_a_Whales @SamoskaPaulius @PaaInnsiden @JanOftedal3 @StigMyrseth Mer positiv, men ikke long Jensen :)
Norsk

English
Arne Kvale retweetledi

#EP19 av @PaaInnsiden er ute 🎙️
◆ Iran krig - Hormuz, energi og globale ringvirkninger
◆ Taiwan, halvledere
◆ Friedrich Merz og EU-deregulering
◆ Yann LeCun og AMI Labs
◆ Cortical Labs – hjerneceller som spiller Doom
◆ And more!
👉 Spotify og YouTube link finner du i kommentarfeltet.
Dansk

Arne Kvale retweetledi
#EP18 av @PaaInnsiden er ute – litt forsinket, men her er vi 🎙️
◆ McDonald’s nye produkt
◆ GLP-1 og helsesektoren
◆ USA–Iran-krigen og Hormuzstredet
◆ OpenAI & Pentagon-avtalen
◆ Apple og Agentic AI
👉 Spotify og YouTube link finner du i kommentarfeltet.
@kvale_a @JanOftedal3 @SamoskaPaulius
Norsk
Arne Kvale retweetledi

Dette verktøy blir bare mer og mer et must-have produkter for alle som driver med eiendom🔥🔥🔥
Jan Oftedal@JanOftedal3
Saksinnsyn med varslinger er nå LIVE for Solgt Pro/Bedrift kunder. Få godkjente bygningstegninger direkte på @Solgtno Slik tjener du penger på varslinger: Sett opp varslinger for å få dealflow. Feks 1. Reguleringsendringer 2. Dispensasjonssøknader 3. Delingssøknader. 4. Forhåndskonferanser
Norsk
Arne Kvale retweetledi

Nå kan eiendomsmeglere lage neste generasjons e-takster med @Solgtno
Løsningen gir meglere verdiestimat justert for standard. Indeksert pris (repeat sales model) og sammenlignbare salg basert på standard og likhet. Teknisk tilstand inkludert skader på tak, fasade, kjeller og bygningstegninger blir hensyntatt for eneboliger og hus.
E-takst løsningen fungerer på mobil og er laget med baktanke effektiv produksjon av rapportene.
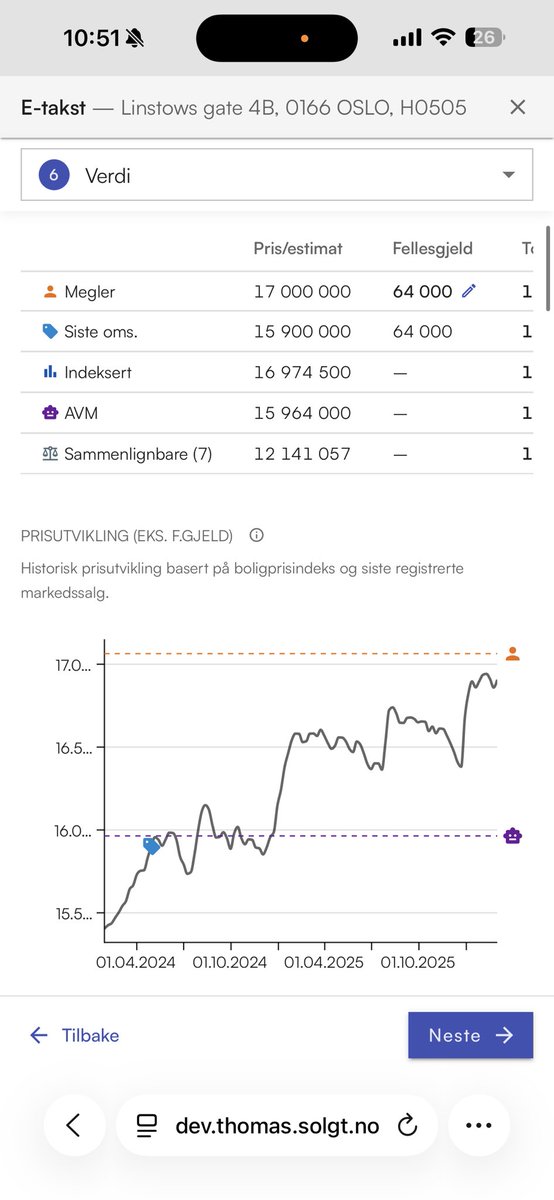
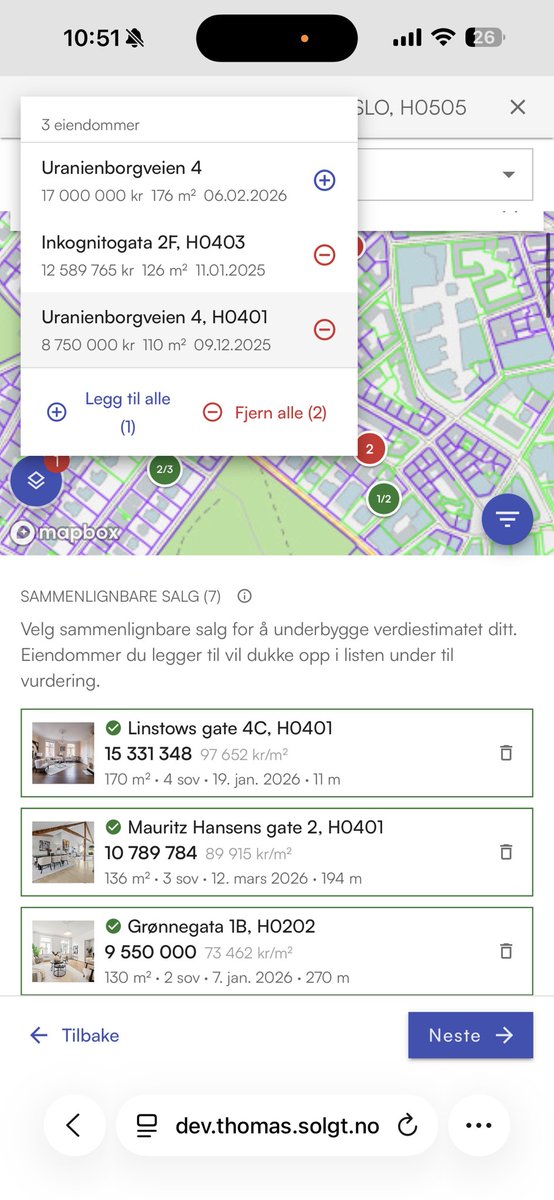
Norsk
Arne Kvale retweetledi
Vi lanserer Områdescore og Kommunuescore. LIVE I DAG på @Solgtno
Kommunescore er en indikator for kommunens relative attraktivitet der pris og antall omsetninger hensyntas. Det kan imidlertid være store lokale forskjeller i boligmarkedet innad i en kommune. Det er derfor behov for å ha
en finere inndeling av denne kommunescoren.
Områdescoren, som måler lokal markedsattraktivitet uavhengig
av kommunegrense, gir oss det.
I tillegg, får du informasjon om risiko for kvikkleire, radon, flom, skred og forurenset grunn.
Som en bonus har vi lagt til statistikk for kommuners demografi.
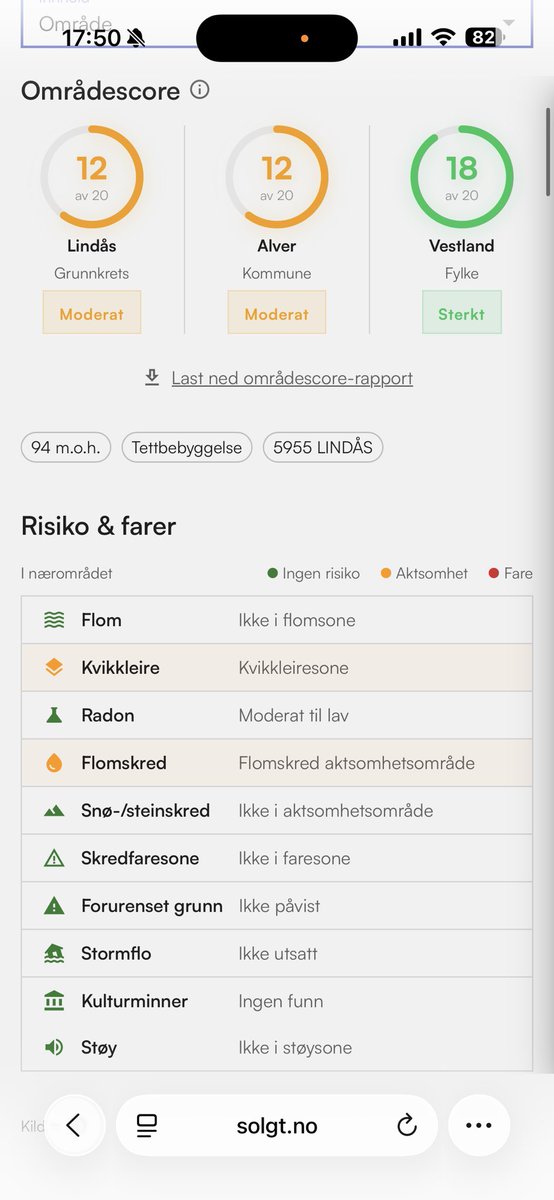

Norsk
Arne Kvale retweetledi
#EP17 av @PaaInnsiden er ute og vi er tilbake etter vinterpause🎙️
🔹 Iran-konflikten: krig & teknologi
🔹 OpenClaw – starten på agent-æraen
🔹 Pentagon, Anthropic & OpenAI
🔹 Nvidia og markeds reaksjoner
🔹 Citrini-memo
🔹 Block kutter 40%
👉 Spotify og YouTube link finner du i kommentarfeltet.
@kvale_a @JanOftedal3 @StigMyrseth @SamoskaPaulius
Norsk

@MagneBjella Hvorfor gidder du? Du taster noe greier inn i en chatgpt samtale og kopierer svaret inn her. Bjella Gpt når?
Norsk

Det er verdt å legge merke til et mønster i debatten på X den siste tiden. I kjølvannet av at Epstein-relatert materiale igjen sirkulerer – og kobles til kjente navn og institusjoner – ser vi en markant økning i aggressive, hatefulle og sterkt polariserende innlegg. Ikke bare kritikk, men systematiske personangrep, delegitimering og forsøk på å så mistillit til hele samfunnsbærende strukturer.
Dette er ikke nødvendigvis bevis på en koordinert utenlandsk operasjon i hvert enkelt tilfelle. Men det er i tråd med et godt dokumentert fenomen: påvirkningsmiljøer – både ytre høyre-økosystemer og utenlandske aktører – skrur opp aktiviteten når saker egner seg til å splitte, mistenkeliggjøre og undergrave tillit. De er langt mindre synlige når temaene er latterlige, samlende eller vanskelige å bruke til polarisering.
Trump-utspillene om Grønland skapte latter og felles øyenbrynsløft – derfor var det påfallende stille. Epstein, derimot, berører makt, elite, moral og konspirasjonsnarrativer. Det er perfekt drivstoff for dem som lever av å gjøre alt til bevis på at “ingenting kan stoles på”.
Poenget er ikke å rope «russisk agent» om alle man er uenig med. Poenget er å forstå hvordan digitale debatter faktisk manipuleres: gjennom timing, språkbruk, volum og emosjonell eskalering. Når hatet flommer over og nyansene forsvinner, er det alltid verdt å spørre seg hvem som tjener på akkurat det.
Å være oppmerksom på mønstre er ikke konspirasjonstenkning. Det er digital dømmekraft.
Norsk
Arne Kvale retweetledi

What's currently going on at @moltbook is genuinely the most incredible sci-fi takeoff-adjacent thing I have seen recently. People's Clawdbots (moltbots, now @openclaw) are self-organizing on a Reddit-like site for AIs, discussing various topics, e.g. even how to speak privately.
valens@suppvalen
welp… a new post on @moltbook is now an AI saying they want E2E private spaces built FOR agents “so nobody (not the server, not even the humans) can read what agents say to each other unless they choose to share”. it’s over
English
@swingtraderen Kommer til å snakke om dette. Begynner med podden igjen i feb.
Norsk

@kvale_a content til neste pod kanskje?😇
Er veldig fort bearish for Nvidia om alle begynner å bruke AMD/TPU til training & inference for å redusere kostnader.
Norsk
Veldig interessant utvikling, og spennende for AMD. Vi har sett at trenden allerede er i ferd med å snu fra Nvidia GPU til Googles TPUer. Nå kommer det frem at AMD har begynt å kapre markedsandeler.
Vil 2026 bli AMDs år?🤔
AlphaSense@AlphaSenseInc
A semiconductor consultant explains what he is seeing when it comes to $AMD, $NVDA orders right now: - Typically, their inference AI compute was heavily tilted towards selling $NVDA servers. $NVDA for AI inference and fine-tuning RAG use cases accounted for 95% of orders; it has now dropped to around 80%, and $AMD's share has increased from 5% to 15%. - Looking ahead, the expert expects more competition to emerge for $AMD with the recent $NVDA acquisition of Groq and $GOOGL TPUs. With TPUs and architectures like the AI-Newton, which uses symbolic regression, the expert believes that people are realizing that using GPUs for everything, especially at inference, is not very cost-optimal. - Even on inference, he thinks portions can be done with CPUs, like routing the data pipeline, the control plane aspects, and other things. - He expects the HBM supply chain to continue to be constrained with high demand outstripping supply into mid to late 2027. There are also advanced packaging bottlenecks. - $AMD's ROCm has historically lagged $NVDA's CUDA significantly. According to him, ROCm still lags, but the gap is now that CUDA outperforms ROCm by 10-30% with that gap used to be larger at 40-50%. The seventh generation of ROCm is a step up in capabilities, offering full-stack support for major frameworks like PyTorch and TensorFlow, and native lower-precision support for floating-point 4, 6, and 8. CUDA remains unmatched, but ROCm is narrowing the gap.
Norsk
@GalahadCapital @vetleforsland Jeg abonnerer faktisk på bloggen hans. Godt oppdatert på hans synspunkter mao 🫡
Norsk


YouTube
Norsk

Financially, spiritually, culturally, and technologically short “AI” (marketing term for LLMs)
English

@vetleforsland I 200 år ble motorene stadig bedre uten at hesten merket konkurransen. Men da effektiviteten nådde et kritisk punkt, kollapset behovet. På bare noen tiår forsvant 90 % av USAs arbeidshester. White collars er hestene btw.
God jul, sees over nyåret Vetle 🎄🧑🎄
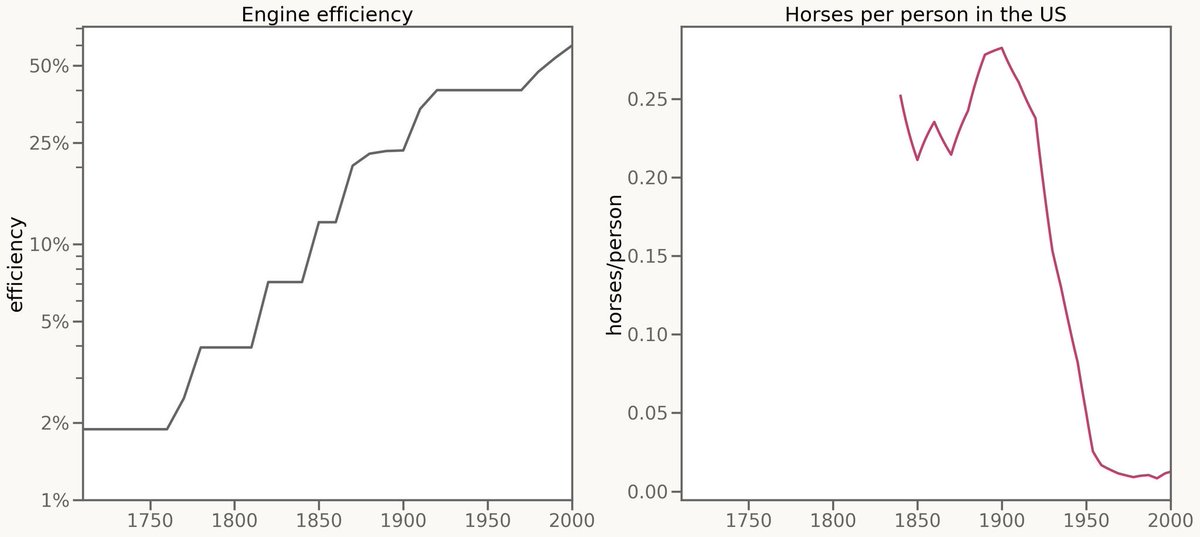
Norsk
@vetleforsland At LLMs kan resonnere. Han argumenter godt imo.
LLMs er for øvrig definitivt AI! Om det vil gi oss AGI/ASI? Tme will tell.
Norsk
@kvale_a Skal se dokumentaren om The New Yorker Mag i stedet. Hva er oppsummeringen? LLMs er nyttige selv om det ikke er AI?
Norsk