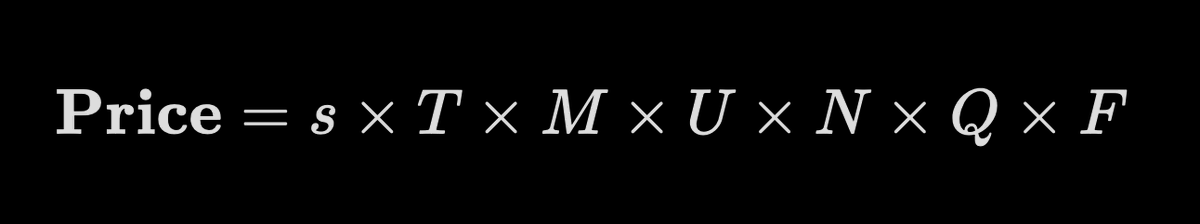@r0ck3t23 But RL environments are still data... bottleneck has just shifted to designing rubrics & evals for harder-to-verify tasks in knowledge work (law/finance) & frontier scientific research. You still need experts in the loop to define objective criteria for rewarding success.
English