Sabitlenmiş Tweet

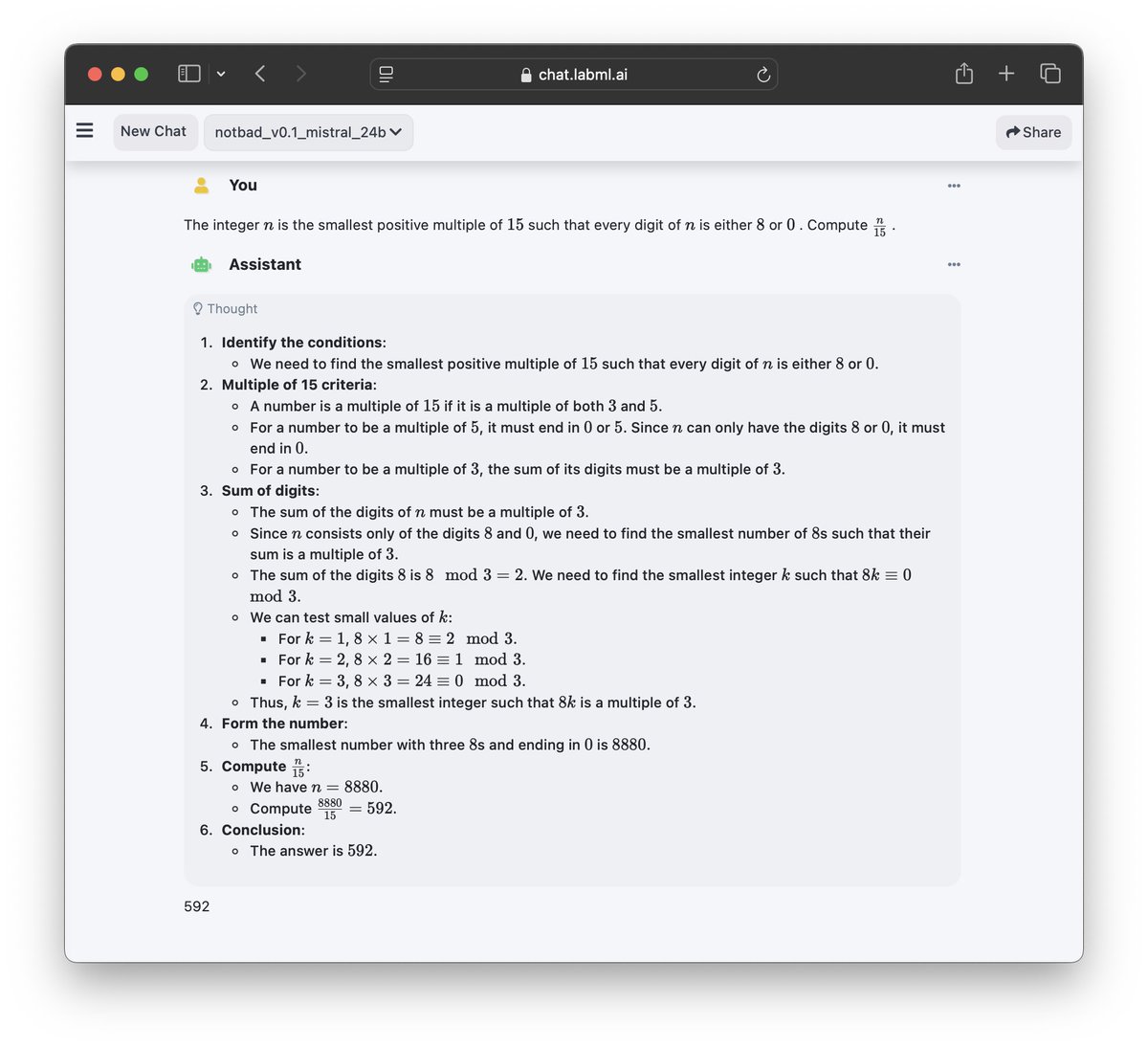
You can now download the Notbad v1.0 Mistral 24B model from @huggingface
huggingface.co/notbadai/notba…
Try it on chat.labml.ai
English
labml.ai
654 posts

@labmlai
📝 Annotated paper implementations https://t.co/qeO4UTbrJ3

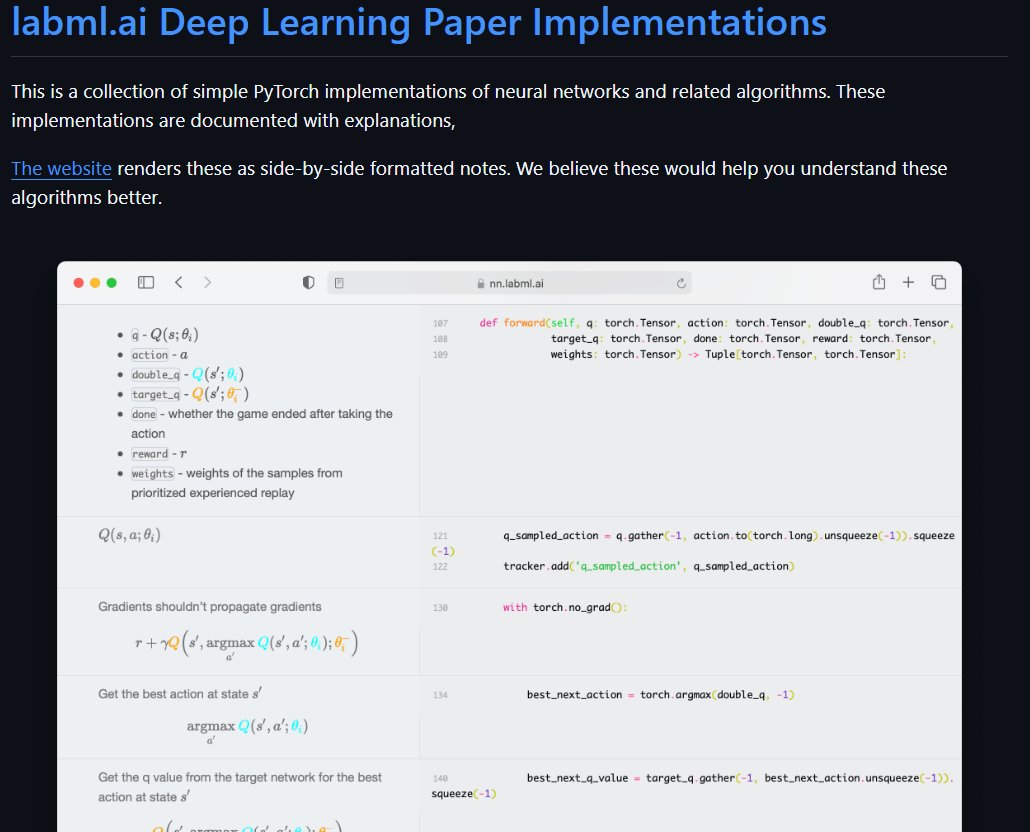







Coded a transformer model in JAX from scratch. This was my first time with JAX so it might have mistakes. lit.labml.ai/github/vpj/jax… This doesn't using any high-level frameworks such as Flax. 🧵👇
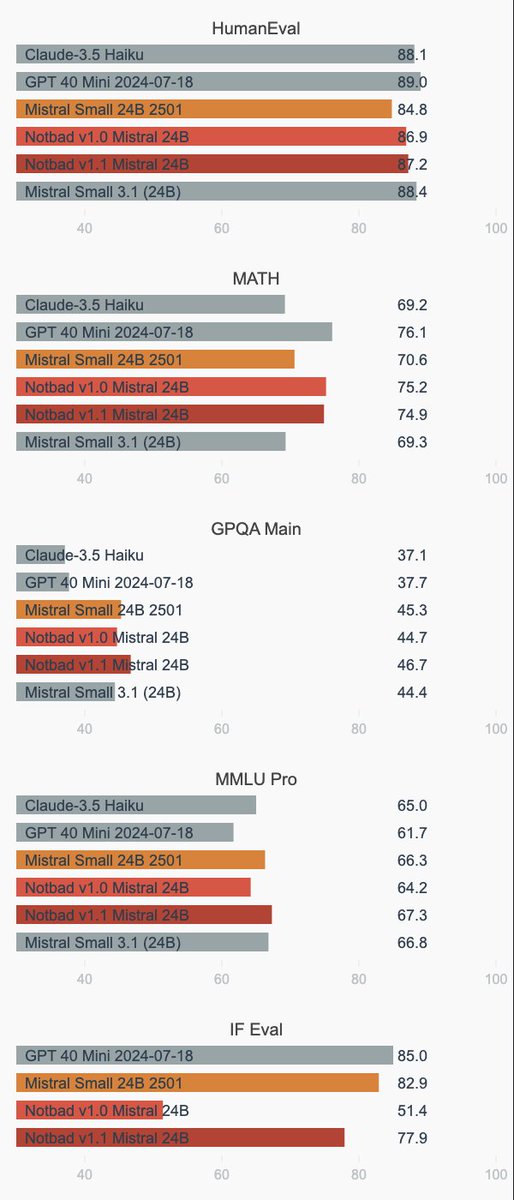
We are releasing an updated reasoning model with improvements on IFEval scores (77.9%) than our previous model (only 51.4%). 👇 Links to try the model and to download weights below