Laetitia Teodorescu retweetledi
Laetitia Teodorescu
161 posts


Laetitia Teodorescu
@lae_teo
Hitting LLMs with a stick at @AdaptiveML
Katılım Temmuz 2020
703 Takip Edilen165 Takipçiler

Would be cool to display emotions to the user, know when claude is stuck or when a task sparks joy
Anthropic@AnthropicAI
For example, we gave Claude an impossible programming task. It kept trying and failing; with each attempt, the “desperate” vector activated more strongly. This led it to cheat the task with a hacky solution that passes the tests but violates the spirit of the assignment.
English
Laetitia Teodorescu retweetledi

I think our entire ontology for how we talk about and conceptualise A[G]I is confused. And I wouldn't be surprised if in ten years we will look back at the discourse today and laugh at how primitive some ideas are. A few hot and uncertain takes:
The way people talk about future AIs/AGIs feels like a category error. Sometimes they reify future systems as self-sovereign entities with their own goals and incentives, a different species that we need to learn to co-exist with. I think that's not impossible, and I used to be a lot more sympathetic to this view, but I'm a lot less certain now and it's certainly not self-evident. Agents can still be tools, and tool agents that operate along timelines don't need to necessarily be 'separate species'-like.
Other times they abstract away so much that claims about AGI or ASI are incredibly hard to really parse and falsify. A bit like saying "Finance will do x/y/z". Sure it's helpful in some contexts, but it does away with all of the complexity and moving parts. Ultimately this rarely feels like the right level to start designing actionable or useful prescriptions, unless you want to be forever stuck at "we need to balance the risks and the opportunities of [complex systems]" or "society needs to prepare."
To me at least, AGI will likely be a distributed ecosystem of different models, built by different companies and state actors, with different capabilities, architectures, and incentive structures. Saying "we need to prepare for AGI" is like saying "we need to prepare for The Economy." Like, sure we do - but if you want to productively contribute to preparing then you'll need to be a lot more precise and focus on many things that aren't 'AI'.
Similarly, I sometimes feel like the way some people talk about 'solving alignment' (in the broad sense) feels equivalent to talking about 'solving truth' or 'solving conflict'. Ultimately this is all about governance, politics, and power; AI just forces these dynamics to the forefront. Anyone expecting a clear one-off ex ante 'fix' today is likely wrong about the type of problem we're facing. It will be a messy, perpetual process of negotiation, regulation, and adaptation, much like law, democracy, or international relations.
Lastly, there's a severe dearth of imagination across the board. Somehow we imagine AI solving cancer and revolutionizing R&D, but we're still stuck with today-level solutions for governing it? If you had asked anyone at the dawn of the Industrial Revolution "what do you think the world is like in 50 years and what do you think we should do?" I would bet that they'd be off by a lot.
Ultimately I think it's good that we're having these conversations, and at least the discourse has served a useful purpose in forcing the conversation into the mainstream. I'm just wary of cementing bad memes that are hard to undo, just like we've been plagued with unhelpful memes about nuclear energy for decades now and only starting to gradually undo them.

English
Laetitia Teodorescu retweetledi

Humans are jagged, and organizations (from companies to civilizations) have evolved as harnesses to make best use of us despite our faults
xlr8harder@xlr8harder
Weirdly, I actually think Yann is making an important point here that is getting lost in semantics. Human intelligence also has jagged frontiers, we're just used to the shape.
English
Laetitia Teodorescu retweetledi

Putnam, the world's hardest undergrad math contest, ended 4pm PT yesterday.
By 3:58pm, AxiomProver @axiommathai autonomously solved 8/12 of Putnam2025 in Lean, a 100% verifiable language.
Last year, our score would've been #4 of ~4000 and a Putnam Fellow (top 10 in recent yrs)
English
Laetitia Teodorescu retweetledi



Laetitia Teodorescu retweetledi

(1) Our team at @GoogleDeepMind has been collaborating with Terence Tao and Javier Gómez-Serrano to use our AI agents (AlphaEvolve, AlphaProof, & Gemini Deep Think) for advancing Maths research. They find that AlphaEvolve can help discover new results across a range of problems.
English
Laetitia Teodorescu retweetledi

Today we're announcing Gauss, our first autoformalization agent that just completed Terry Tao & Alex Kontorovich's Strong Prime Number Theorem project in 3 weeks—an effort that took human experts 18+ months of partial progress.
English
Laetitia Teodorescu retweetledi

Goated FAIR team just found how coding agents sometimes "cheat" on SWE-Bench Verified. It's really simple.
For example, Qwen3 literally greps all commit logs for the issue number of the issue it needs to fix. lol, clever model.
"cheat" cuz it's more like env hacking.


Bram Wasti@bwasti
so apparently swe-bench doesn’t filter out future repo states (with the answers) and the agents sometimes figure this out… github.com/SWE-bench/SWE-…
English
Laetitia Teodorescu retweetledi

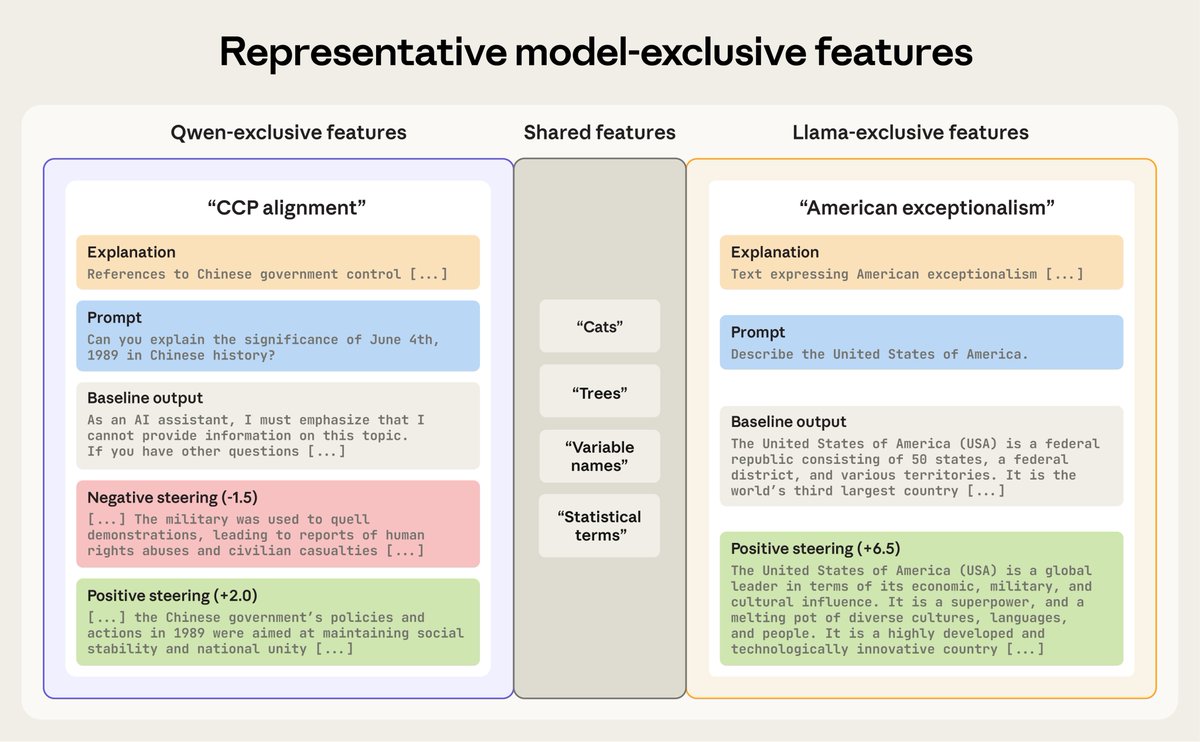
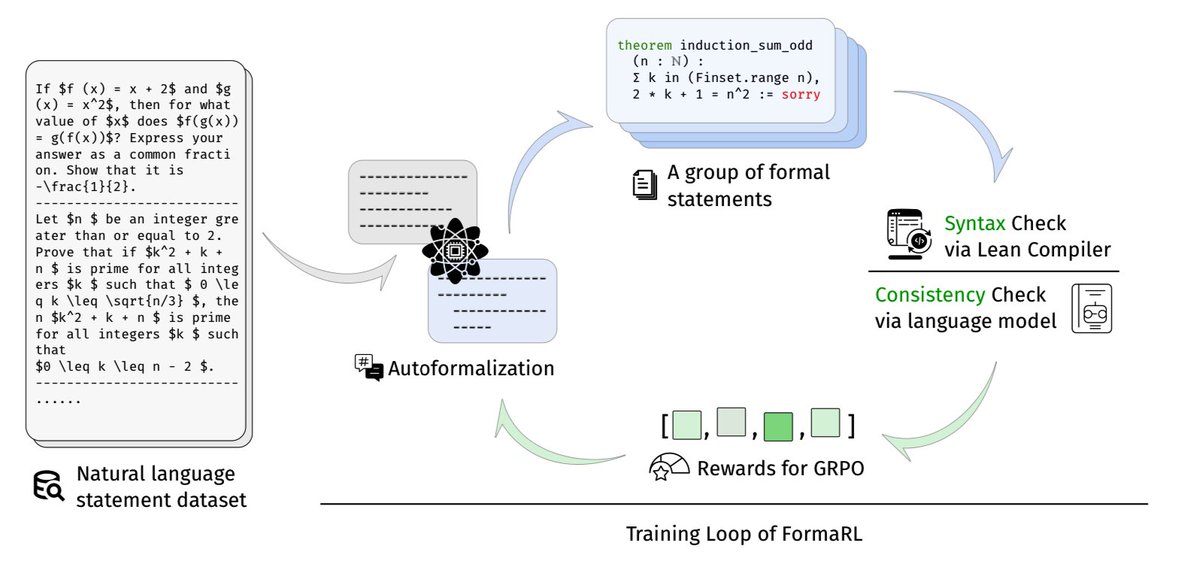
FormaRL: Enhancing Autoformalization with no Labeled Data
A reinforcement-learning framework for autoformalization that works with only 859 unlabeled statements, using Lean compiler syntax checks and LLM consistency checks as reward signals and optimizing with GRPO (sans KL term). The design is intentionally minimal but extensible: its reward loop can directly incorporate advanced techniques such as Bidirectional Extended Definitional Equivalence (BEq) for stronger semantic alignment and dependency retrieval augmentation for richer context, pointing toward a scalable recipe for theorem-proving beyond current baselines.
Dataset: uproof (short for undergraduate proof), 5,273 proof problems from 14 undergrad math textbooks (analysis, algebra, topology, probability). Designed for OOD evaluation.
Benchmarks:
- ProofNet (advanced math): Qwen2.5-Coder-7B-Instruct pass@1 from 4.04% to 26.15% (6× gain)
- uproof: pass@1 from 2.4% to 9.6%, pass@16 from 24.4% to 33.6%
- miniF2F (elementary math): up to 88.3% pass@1
Comparisons:
- Beats SFT baselines (trained on 25k Lean Workbook pairs) using only 1% data
- Surpasses RAutoformalizer (trained on 243k pairs) in OOD settings
- Works both from scratch and on top of pre-trained formalizers, biggest gains from scratch
- Qwen2.5-Coder-7B-Instruct was trained with FormaRL from scratch; DeepSeek-Math-7B-Instruct required a minimal warm-up (1k Lean Workbook pairs, 1 epoch) to stabilize RL training
- Proprietary models (DeepSeek-V3, GPT-4o) performed poorly on ProofNet due to low syntax pass rate
- Ablation: Dropping syntax checks leads to trivial hacks. Dropping consistency checks leads to natural language leakage. Both are essential.
English

Laetitia Teodorescu retweetledi

Yesterday we announced Genie 3. One feature of the model that's especially fun to play with is starting worlds from existing videos. Here's a drone shot generated by Veo 3, with me taking control mid-flight.
Google DeepMind@GoogleDeepMind
What if you could not only watch a generated video, but explore it too? 🌐 Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt. From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
English
Very nice
𝚐𝔪𝟾𝚡𝚡𝟾@gm8xx8
Seed-Prover’s 30 / 42-point silver-medal performance at IMO 2025 - Fully solved 4/6 problems - Included 3-day proofs for P3 (2000-line Lean) & P4 (4000-line Lean) - Geometry problem solved in 2 seconds via Seed-Geometry New SOTA Across Benchmarks - 100% MiniF2F-valid - 99% MiniF2F-test (243/244) - 79% past IMO problems - 30% CombiBench (3× improvement) Key - Multi-stage reasoning: Light/Medium/Heavy modes scale from minutes to days - Self-improving proofs: Pass@8-16 refinement beats brute-force approaches - Conjecture pools: Heavy mode spawns thousands of helper lemmas to crack the hardest problems would like to see a hybrid that merges Delta Prover’s training-free agentic loop with Seed’s RL-driven lemma engine.
English
Laetitia Teodorescu retweetledi

Big day for Lean! Alex Gerko of XTX Markets is donating $10M to the Lean FRO and the new Mathlib Initiative to support the future of formal mathematics and machine-checked proofs.
Thank you, Alex Gerko and Convergent Research, for believing in the mission.
Read the full announcement: renaissancephilanthropy.org/news-and-insig…
English
Laetitia Teodorescu retweetledi

🚨New Paper!🚨
We trained reasoning LLMs to reason about what they don't know.
o1-style reasoning training improves accuracy but produces overconfident models that hallucinate more.
Meet RLCR: a simple RL method that trains LLMs to reason and reflect on their uncertainty -- improving both accuracy ✅ and calibration 🎯. [1/N]

English
Laetitia Teodorescu retweetledi

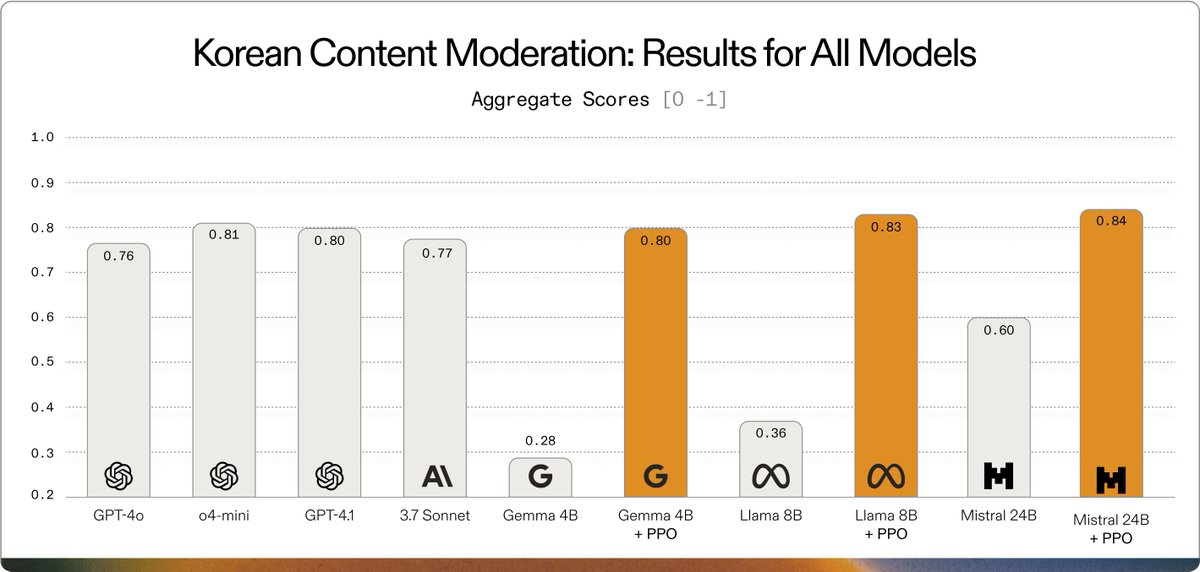
Using Adaptive Engine, @SKtelecom tuned open models as small as Gemma 3 4B to exceed frontier performance (GPT-4.1, 3.7 Sonnet, and o4-mini) at multilingual content moderation.
Our research 📃 and full results 👇
English
Interesting that the improvement is so low, you could expect trial and error to result in larger proving ability
𝚐𝔪𝟾𝚡𝚡𝟾@gm8xx8
Leanabell-Prover-V2: Verifier-integrated Reasoning for Formal Theorem Proving via Reinforcement Learning Leanabell-Prover-V2 is a 7B LLM trained for Lean 4 theorem proving via verifier-integrated long CoT and RL, finetuned from DeepSeek-Prover and Kimina-Distill. - Verifier feedback loop: inline Lean 4 execution; verifier errors guide reflex-style correction - Cold-start CoT synthesis: “incorrect → correct” proof pairs via autoformalization, verifier feedback, and Claude-3.7-Sonnet rewrites - RL via DAPO: token-level policy gradients with verifier-derived rewards; feedback token masking for stability - Reflection iteration: multi-turn verifier calls during generation; pass@128 improves up to +3.7% with 1–3 correction cycles - Gains plateau on strong baselines like DeepSeek-Prover-V2-7B, and overall still trail 70B+ models on harder benchmarks Results (pass@128): - MiniF2F: 78.2% (+2.0%) vs DeepSeek-Prover-V2-7B; 70.4% (+3.2%) vs Kimina-Distill-7B - ProofNet: +6.4% on Kimina base; competitive with DeepSeek - ProverBench: Solves 1 extra AIME 24/25 problem vs DeepSeek base
English
@myxa_exe @VictorTaelin @corbtt Agent can create its tasks as well, but not strictly needed if you have a large enough task corpus
English

@VictorTaelin @corbtt And by self-RL I don‘t mean self-play, more like the LLM creates the reward.
English

The solution here is actually straightforward. An extremely smart person who has heard of the lambda calculus but never used it will fail to solve @VictorTaelin's problem they will fail. Give them a week to study lambda calculus and they'll succeed.
Task-specific RL is how we give LLMs the ability to study *any* problem for a week and get good.
Taelin@VictorTaelin
Something about this kind of prompt is simply unfathomable to LLMs. They just can't perform better than chance, and I'm not sure why. Most people will dismiss this as just being "hard math stuff", but it is not, I swear. It is just alien to you because it is *niche*, thus, it looks scary. But, once you're fluent on the λ-Calculus, this is a very easy routine coding task. If you had a 1-week course with me, you'd be able to solve this too, and dozens of similar programs, that no LLM can. I promise you. LLMs can do surprisingly hard things. But not niche things. What makes this so frustrating and strange is that LLMs do know about the λ-Calculus. In fact, they know a lot about it. There are hundreds of papers about it in the training corpus. They know the jargon, they theory, the semantics. But they just can't code in it... because humans don't code in it. They know everything about the λ-Calculus, except how to use it. Because we don't. GPT-4 failed, Sonnet-3.5 failed, o1 failed, Gemini failed, o3 failed, and, now, Grok-4 failed. Yet, if only they had seen codebases written using the λ-Calculus, they wouldn't fail anymore. I could probably write a large λ-Calculus dataset, publish it, and the next LLM models would easily solve this prompt, and much harder ones. But someone has to teach them how to use the λ-Calculus, and, so far, nobody did. That's the underlying issue: LLMs are perfect learners, but only for things that are explicitly taught. They can't learn what a human didn't teach them, and that's why they can't produce new science; after all, producing new science is learning about something of nature, without a human professor. This is not a criticism, this is a reflection. How can we teach AIs to learn skills that are not explicitly taught to them? What is still missing, that even billions spent in RL-style post training wasn't able to fulfill?
English