@raw_works Do you use vanilla RLM from DSPy? I tried to use it for LongBench with Qwens but DSPy module has a bunch of problems which required nontrivial changes to make it work
English
Jakub Bartczuk
399 posts

@lambdaofgod
My opinions are not my own. They belong to the gnomes that live in my head

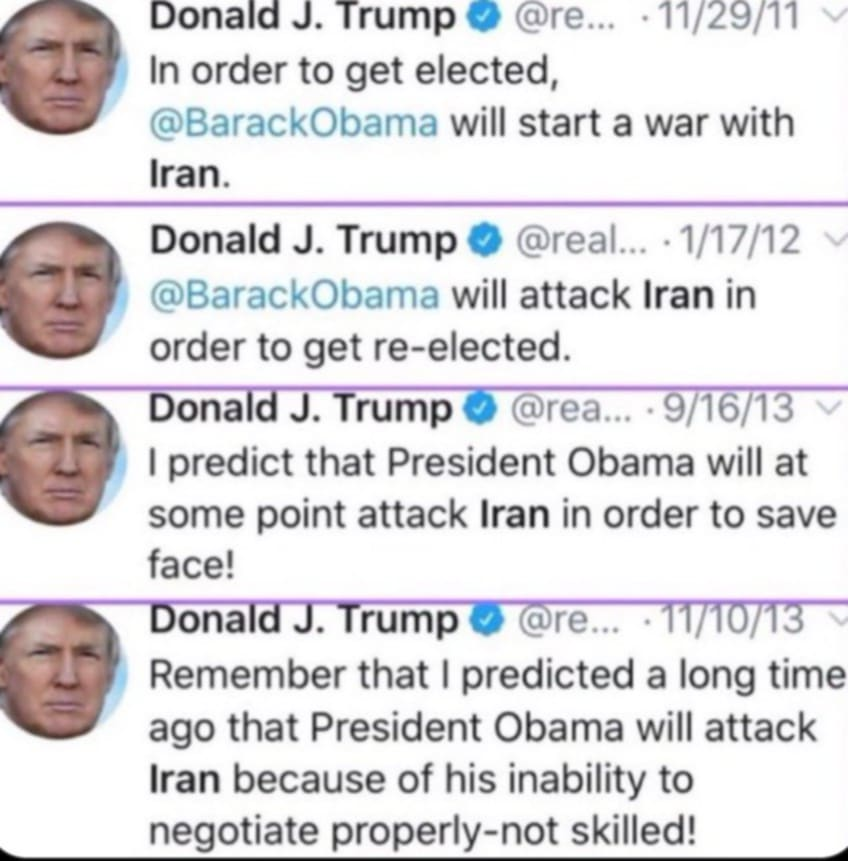
ok so the default DSPy.RLM is literally going to destroy this benchmark before the end of the day. running now for sonnet 4.5... 🏆 Scoreboard (live) RLM: 90/94 (95.7%) Vanilla: 0/94 (0.0%) anyone want to pay for the opus run? 😉



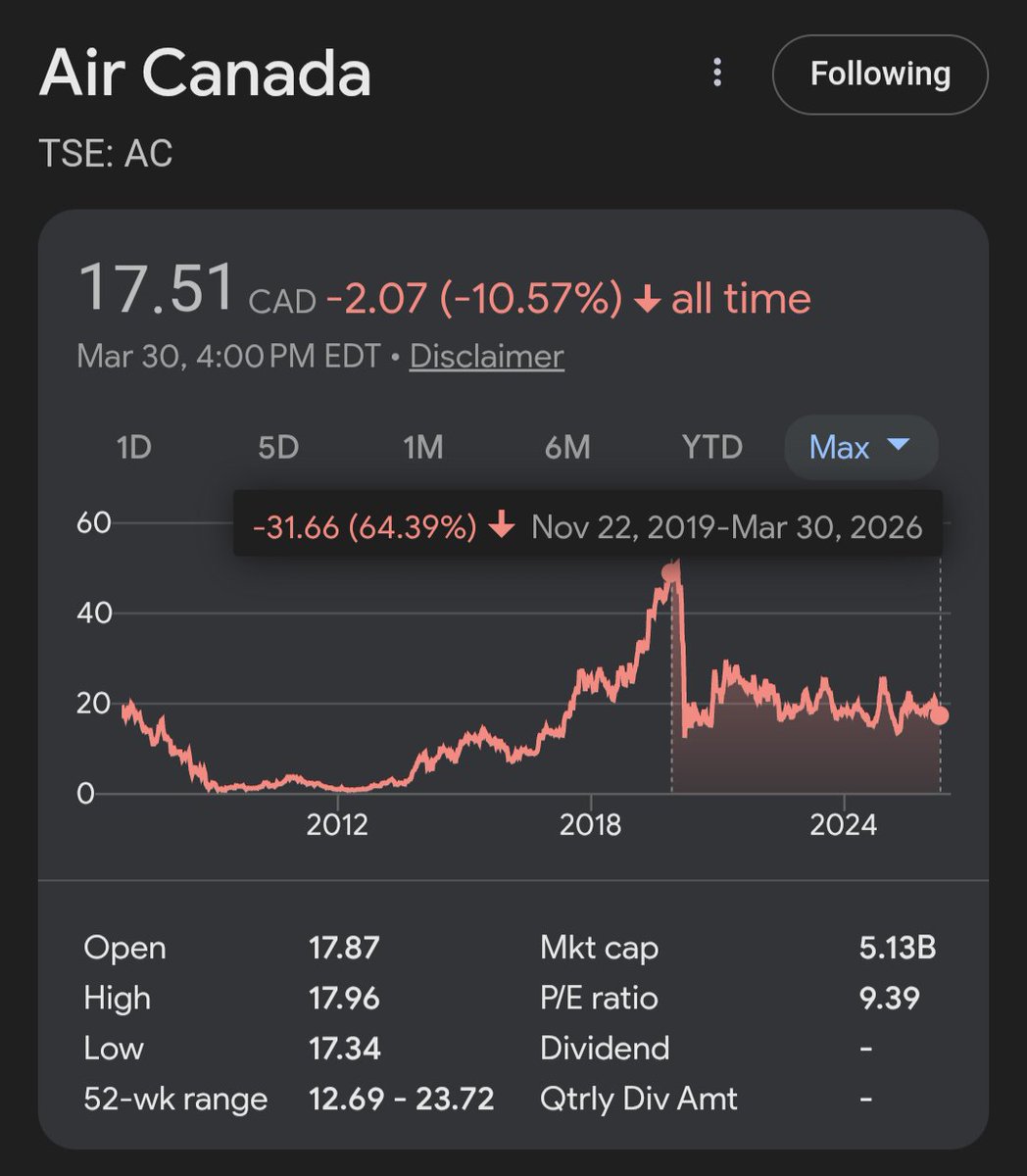
Air Canada CEO to step down over failure to speak French ft.trib.al/WYQO3bF



Introducing Mixedbread Wholembed v3, our new SOTA retrieval model across all modalities and 100+ languages. Wholembed v3 brings best-in-class search to text, audio, images, PDFs, videos... You can now get the best retrieval performance on your data, no matter its format.


🧵For the last seven years, I kept re-implementing the same pattern: A parallel map loop that divides the work among several processes or threads. My very first attempts were built on Python’s standard tools, e.g., multiprocessing.map... ↩️




New OpenAI repo: Symphony github.com/openai/symphony TLDR: it's an orchestration layer that polls project boards for changes and spawns agents for each lifecycle stage of the ticket You will just move tickets on a board instead of prompting an agent to write the code and do a PR


Oracle just told every AI company on earth the same thing. Your models are worthless. Not the technology, talent or the billions spent training them. But the data they were trained on. Larry Ellison, the man who built Oracle into the backbone of global enterprise just dropped a bombshell. He said ChatGPT, Gemini, Grok, and Llama, all of them are training on the exact same data. The entire public internet, every Wikipedia page, Reddit thread and every news article. That means they're all converging essentially becoming the same product with different logos. Ellison's word for it is commodities. But here's where it gets dangerous. He says the real gold isn't public data, It's private data. The medical records in hospital systems, the financial data in bank vaults. The supply chain secrets of every Fortune 500 and guess where most of that data already lives. Not Google, Amazon or Microsoft but inside Oracle. Oracle databases hold most of the world's high value private enterprise data. So Oracle just launched something called AI Database 26ai. It lets the top AI models, ChatGPT, Gemini, Grok, Llama reason directly over a company's private data, without that data ever leaving the vault. They're using a technique called RAG, Retrieval Augmented Generation. The AI doesn't train on your data, it searches it in real time. Think about what that means. A bank could ask AI to analyze every loan it's ever made without exposing a single customer record. A hospital could have AI diagnose patients using its full medical history without violating HIPAA. A defense contractor could let AI reason across classified operations without data leaving a secure environment. Ellison is betting this is bigger than the training market. Bigger than the GPU boom. Bigger than the data center buildout. He called it the largest and fastest growing market in history. The numbers back the ambition. Oracle's remaining performance obligations just hit $523 billion. That's contracted revenue not yet delivered and $300 billion of it comes from OpenAI alone. Cloud revenue hit $8 billion in a single quarter, OCI grew 66 percent and GPU revenue surged 177 percent. But here's the part nobody's talking about. If private data becomes the real AI moat, then whoever controls the database controls the future of AI. And that's a level of power that should make everyone uncomfortable.



How does OpenAI balance long-term research bets with product-forward research fundamentals? I’ve been getting this question a lot lately, usually framed as a suggestion that Jakub (@merettm) and I are pushing an increasingly product-focused agenda. That characterization is simply wrong. Foundational research has been core to OpenAI from the start, and today we run a research program with hundreds of exploratory projects - much like the ones that led to our reasoning-model breakthrough. The majority of our compute is allocated to foundational research and exploration - and not product milestones. Anyone who has spent time with me or Jakub knows we are the last people in the world who would push for the advancement of products over the advancement of research. We’re in the business of creating an automated scientist, and capabilities that were considered grand challenges just a few years ago (like IMO-level mathematical reasoning) now emerge as normal parts of the research process. We’re also seeing our models accelerate researchers worldwide, helping advance work across biology, mathematics, physics, and even our own research. Jakub and I put a lot of effort into ensuring that research stays focused on uncovering algorithms that will scale to the compute we’ll have a year from now. We protect mindshare and amplify discourse on exploratory work. We do this while recognizing that we’re also a deployment company - and that deployment gives us access to even larger-scale compute, richer feedback, and more room for exploration. Our researchers are passionate about having their work out in the world, and a special slice of our org is dedicated to making sure our deployments are delightful for end users. Our goal isn’t to turn research into a quarterly race. It’s to build a durable research engine - one that compounds learning over time and consistently turns long-horizon exploration into real, measurable advances, while ensuring those advances become valuable in the real world. That’s the roadmap we’re executing on. And while there have been ups and downs over the last decade (as you expect with any research program), I think most of our researchers would share my strong optimism today.