
rckv
213 posts
rckv
@layer2maxi
NodeJs backend developer. AI connoisseur. Former atheist, now spiritual conspirator. Non-vaxxed pure blood. Lover of freedom
Europe Katılım Nisan 2021
5.4K Takip Edilen282 Takipçiler







Everyone on earth takes a private vote by pressing a red or blue button. If more than 50% of people press the blue button, everyone survives. If less than 50% of people press the blue button, only people who pressed the red button survive. Which button would you press? BE HONEST.
English
@BTCBreadMan @KeeferPB and now he's not giving you consent. so respect it and don't do it.
English

My wife and I recently scheduled an appointment to get our 7 year old circumcised.
We’ve waited 2 months, and now the day before the procedure he’s having second thoughts.
Parents who have gone through this before: what’s your advice on how to proceed?
Bribe with ice cream?
English
@bnjmn_marie I agree, I just wish we had more data points to prove it´s not worth the cost.
English

@layer2maxi If Q4 already matches the original accuracy at 99%, I think searching for the missing 1% is not worth the cost.
I only evaluate higher Q when Q4 is bad but it's very unlikely to happen
English
Qwen3.6 GGUF Evaluations
For the 27B:
Q2_K_XL is surprisingly recommendable.
IQ3_XXS performs very similarly, uses only +0.2 GB, and generates significantly fewer tokens. If you are memory-tight, pick this one.
Otherwise, if you can spare +2.5 GB, use Q3_K_XL: (almost) same accuracy and token efficiency as the original.
All the results, also for the 35B, here:
kaitchup.substack.com/p/summary-of-q…
More results are coming, probably Monday, covering other GGUF providers and some abliterated models.

English

I’d love to see any European walk for an hour in 95 degree heat lmaoo
Gregor 🌹🇪🇺🇦🇹@salingergregor
if they keep this bs up there will be 50k intl fans each game day who just take a regular train to Rutherford and WALK the 1h to the MetLife Stadium. I know walking is an unfamiliar concept for most Americans, but it is a thing in the rest of the world.
English
@NovaNova266079 Mythbusters did this years ago with much better methodology youtu.be/Bz43uy0K8fY

YouTube
English

Can a Swimming Pool Stop a 50 Cal Sniper Rifle.
English

You, in a panic, buying black tip rounds.
Me, a sophisticate, have surrounded my perimeter with 2 inch tall speed bumps and masking tape.
English

After multiple days of many hour long sessions with GPT 5.4 and Claude Opus 4.6 (thinking and extended respectively) I can confidently say I have SOLVED the hard problem of consciousness.
You might think that I'm suffering from LLM psychosis, but all of my code is public and you can see it for yourself. Chat GPT 5.4 after 9 hours of extended thinking in pro mode could not find a single flaw anywhere.
I have just collapsed thousands of years of futile philosophical debate into an elegant solution in one of today's leading programming languages, hailed for its compatibility with LLM driven research.
We are expanding the frontier of knowledge!
English
@TheAhmadOsman new benchmark - how long can you use it commercially without getting a "Cease & Desist" letter from them?
English

MiniMax M2.7 at home running on 4x DGX Sparks
vLLM serving full BF16 weights, 200k context
OpenCode having the model monitor its own hardware and report thermals, tokens/sec, TTFT, and other runtime stats in real time
What benchmarks / workflows / things do you wanna see next?
MiniMax (official)@MiniMax_AI
We're delighted to announce that MiniMax M2.7 is now officially open source. With SOTA performance in SWE-Pro (56.22%) and Terminal Bench 2 (57.0%). You can find it on Hugging Face now. Enjoy!🤗 huggingface:huggingface.co/MiniMaxAI/Mini… Blog: minimax.io/news/minimax-m… MiniMax API: platform.minimax.io
English
@Falconve_ It’s probably very good at finding security vulnerabilities, but not great at solving complex problems, as their Claude Code TUI is still far from perfect and their infra uptime is still around 98%. status.claude.com
English

Do you seriously think Claude mythos performance is real? Or is just banthropic bluffing?
English
@kimmonismus Speaks more to Elo Arena being a model personality rating than objective technical capability.
English

Gamma 31b model outperforming Qwen 3.5 397B is nuts to me.
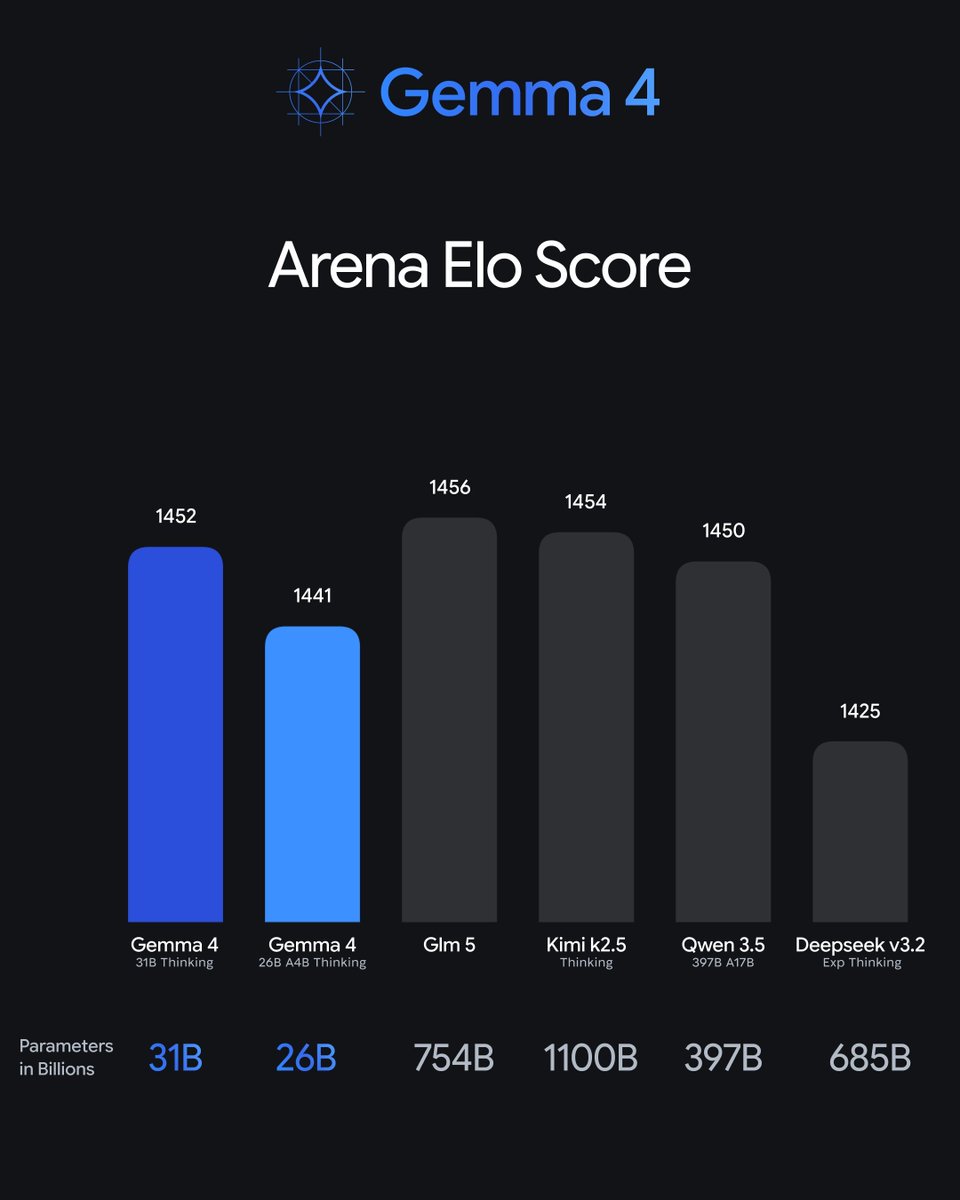
Google DeepMind@GoogleDeepMind
Available in four sizes: 🔵 31B Dense & 26B MoE: state-of-the-art performance for advanced local reasoning tasks – like custom coding assistants or analyzing scientific datasets. 🔵 E4B & E2B (Edge): built for mobile with real-time text, vision, and audio processing.
English
@davidmarcus To be honest, Codex also usually finds P1 or P2 issues in the code it itself wrote.
English

It's wild that every time you run a Codex code review from Claude Code, it finds critical issues. Not 95% of the times, 100%.
English
@TomMontalk In section 2.4, you estimate personal throat bandwidth at 10^(-10) bits per second. Why the minus? Isn’t that a super small number?
English

My new paper on the physics of demons:
🔖 Entropic Parasites: Demonic Entities in the Nested Condensate Model of the Quantum Vacuum
scalarphysics.com/Montalk_(2026)…

English
@sergeykarayev If every company will want to run hundreds of agents at all times of the day, where will the cloud capacity come from? Do we have enough data centers, servers and energy to power it all?
English

Running agents locally is a dead end. The future of software development is hundreds of agents running at all times of the day — in response to bug alerts, emails, Slack messages, meetings, and because they were launched by other agents. The only sane way to support this is with cloud containers.
Local agents hit a wall quickly:
• No scale. You can only run as many agents (and copies of your app) as your hardware allows.
• No isolation. Local agents share your filesystem, network, and credentials. One rogue agent can affect everything else.
• No team visibility. Teammates can't see what your agents are doing, review their work, or interact with them.
• No always-on capability. Agents can't respond to signals (alerts, messages, other agents) when your machine is off or asleep.
Cloud agents solve all of these problems. Each agent runs in its own isolated container with its own environment, and they can run 24/7 without depending on any single machine.
This year, every software company will have to make the transition from work happening on developer's local machines from 9am-6pm to work happening in the cloud 24/7 -- or get left behind by companies who do.
English

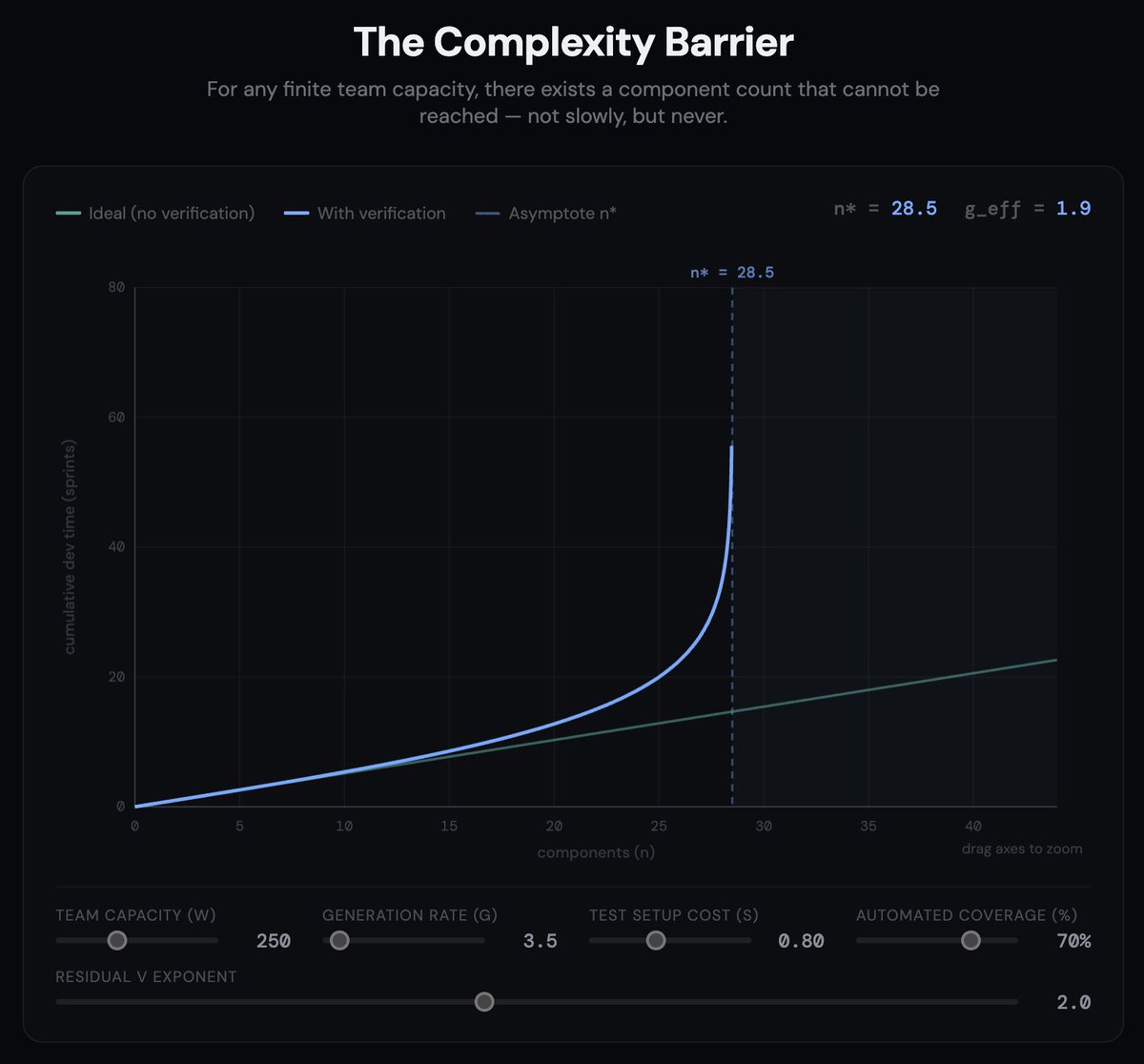
I am developing a formal theorem I call the Verification Complexity Barrier.
In a nutshell, if a program has some components `n` that have connectivity factor of `k > 0` , then verification complexity increases superlinearly for each new component. Therefore the time required to fully verify the system always exceeds time to generate components.
After a while, because it's superlinear, the verification complexity takes off and becomes impossible to keep up with in some finite amount of time. This was true before AI, but is much starker now as code generation time trends towards zero. You hit the barrier sooner.
We all have finite capacity - even AI agents - so there will always be a certain number of components `n` where the wall is hit. You must spend more and more effort on verification for each new component in the system.
The best thing you can do is spend time changing the "topology" of the problem - change the software architecture - so that the exponent of verification complexity is lowered ([1] Lehman) and the curve is flattened. You can bundle components into modules, you can add automated tests, you can use formal proofs, you can use type systems. These things push the barrier to the right. They buy you more components and a more complex system. But the theorem suggests you can only ever defer the barrier, never completely eliminate it.
AI Agents can burn tokens all day long generating software components and tests for those components. They can find bugs and fix them, but they cannot prove the absence of bugs (per [2] Dijkstra, [3] Rice, [4] Smith, and others). And "Bug" needs to be defined against someone's spec for what "working" and "not buggy" looks like. The more you build with Agents, the heavier the verification burden becomes.
This may sound like the same trite observation others have made here on X: "Our bottleneck is no longer writing code, but reviewing code" [5] and "I am the bottleneck now." [6] True, but I don't think anyone has captured the magnitude of the problem. The math is: at a certain component count `n`, it is literally impossible for you, your team, and your agents to completely verify a system. The bottleneck goes to zero, and nothing gets through.
So what software companies do in the real world is release incompletely verified software and massively scale up. This shifts the burden of verification onto their customers, because "given enough eyeballs, all bugs are shallow" ([7] Raymond). If you can get enough eyeballs, this is a very cost-effective way to shift the barrier to the right by massively increasing your team's capacity. You walk the tightrope of doing enough internal verification before release so you don't lose customers, while tolerating a certain amount of escaped bugs, which - if those bugs matter at all - your customers will find for you.
Meanwhile, massively scaling up just accepts the growing cost of complexity. You can push `n*` from 15 to 30 by quadrupling your capacity. To get to 60 you need to quadruple again, and then again to get to 120. Your cost curve is superlinear to get linear gains in system size. At a big enough scale, you amortize the cost across your customer base and the economics work.
Contrast that with a sufficiently complex vibecoded app built for a small audience - high complexity costs can't be amortized at small scale. I expect to see many people and companies try and fail at vibecloning complex SaaS in the near term. Complexity cost economics only scale with audience size (I will share another model for this).
I do think SaaS prices will be corrected downwards to account for savings in code generation, but I predict that once the irrational exuberance for vibing fades, we'll see that it still makes sense to buy rather than self-build complex SaaS.
A broader implication is that AI Agents will never be able to self-verify. Humans, too, will never be able to fully verify their behavior, because LLMs are by design of maximal complexity. Did you see the size of those error bars in the latest METR results? [8] The longer the horizon on a task, the more spread in AI agent outcomes. This is the Barrier in action. Spread is a feature of GenAI, but in practice it means heaps more output to review and verify.
The Complexity Barrier shows you literally won't have time to review it all. At the inflection point of verification complexity, you have to fall back on vibes. The implication for fast-takeoff AGI is even scarier: if AI does reach a point of recursive self-improvement, this theorem suggests it will be structurally impossible to know that behavior is aligned, because you won't be able to completely verify. Drift is bad enough in vibe coding. Runaway AI will drift massively and there's no way of knowing where it will end up.
All that's to say, verification should be the focal point of AI Engineering for the foreseeable future and maybe forever. That is: how do you capture what you want to do, refine that into specifics, and then follow up with automated tests, assertions, evals, and customer feedback to progressively harden your software?
The verification problem is acute now because of how cheap software generation is. Because of the superlinear nature of software verification complexity, companies that push hard on the barrier and successfully shift it right will have a built-in moat versus those who fail to put in the verification work.
Detailed blog post and interactive model incoming.
Links:
[1] en.wikipedia.org/wiki/Lehman%27…
[2] cs.utexas.edu/~EWD/transcrip…
[3] en.wikipedia.org/wiki/Rice%27s_…
[4] cse.buffalo.edu/~rapaport/Pape…
[5] x.com/shl/status/194…
[6] x.com/thorstenball/s…
[7] en.wikipedia.org/wiki/Linus%27s…
[8] metr.org/blog/2025-03-1…
English


i don’t think the effects of this can ever be overstated
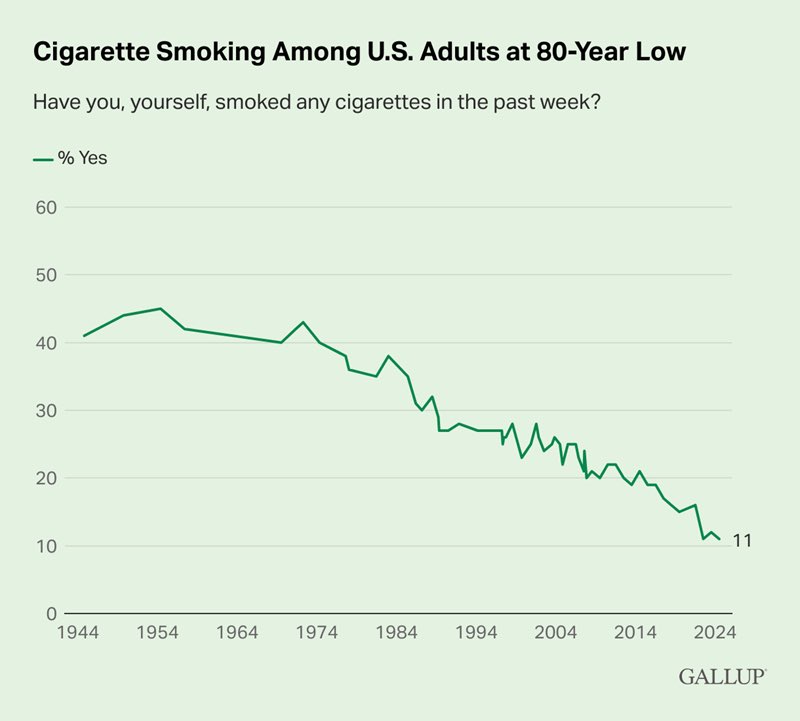
Ava@noampomsky
It seems pretty undeniable that people in their 30s/40s today look way younger than people the same age did even 20 years ago. Why is this happening, is it just better cosmetic treatments? What are the second order social effects?
English