Luiz de Jesus retweetledi
Luiz de Jesus
814 posts




Luiz de Jesus retweetledi

Docker template for anyone who wants to run this on their own Spark:
github.com/stevibe/gemma4…
English
Luiz de Jesus retweetledi

SAE checkpoints:
huggingface.co/Qwen/SAE-Res-Q…
Base model:
huggingface.co/Qwen/Qwen3.5-2…
English
Luiz de Jesus retweetledi

NEW paper from Alibaba.
A 30B MoE with only 3B active params matches Qwen3-235B on real tool-use workloads.
AgenticQwen-30B-A3B: 50.2 average on TAU-2 + BFCL-V4 Multi-Turn.
AgenticQwen-8B: 47.4.
Both more than double their vanilla Qwen baselines and close most of the gap to a 235B model.
How: two RL flywheels run in parallel.
- The reasoning loop mines the model's own errors into harder problems each round.
- The agentic loop grows simple linear tool-use trajectories into multi-branch behavior trees.
- Simulated users actively try to mislead the agent. The training distribution gets harder on its own.
Why it matters for agent devs: you can stop paying frontier prices for routine tool-use workloads.
And the flywheel recipe is reusable. Generate your hard examples from your own agent's failures, not from static synthetic data.
Paper: arxiv.org/abs/2604.21590
Learn to build effective AI agents in our academy: academy.dair.ai

English
Luiz de Jesus retweetledi

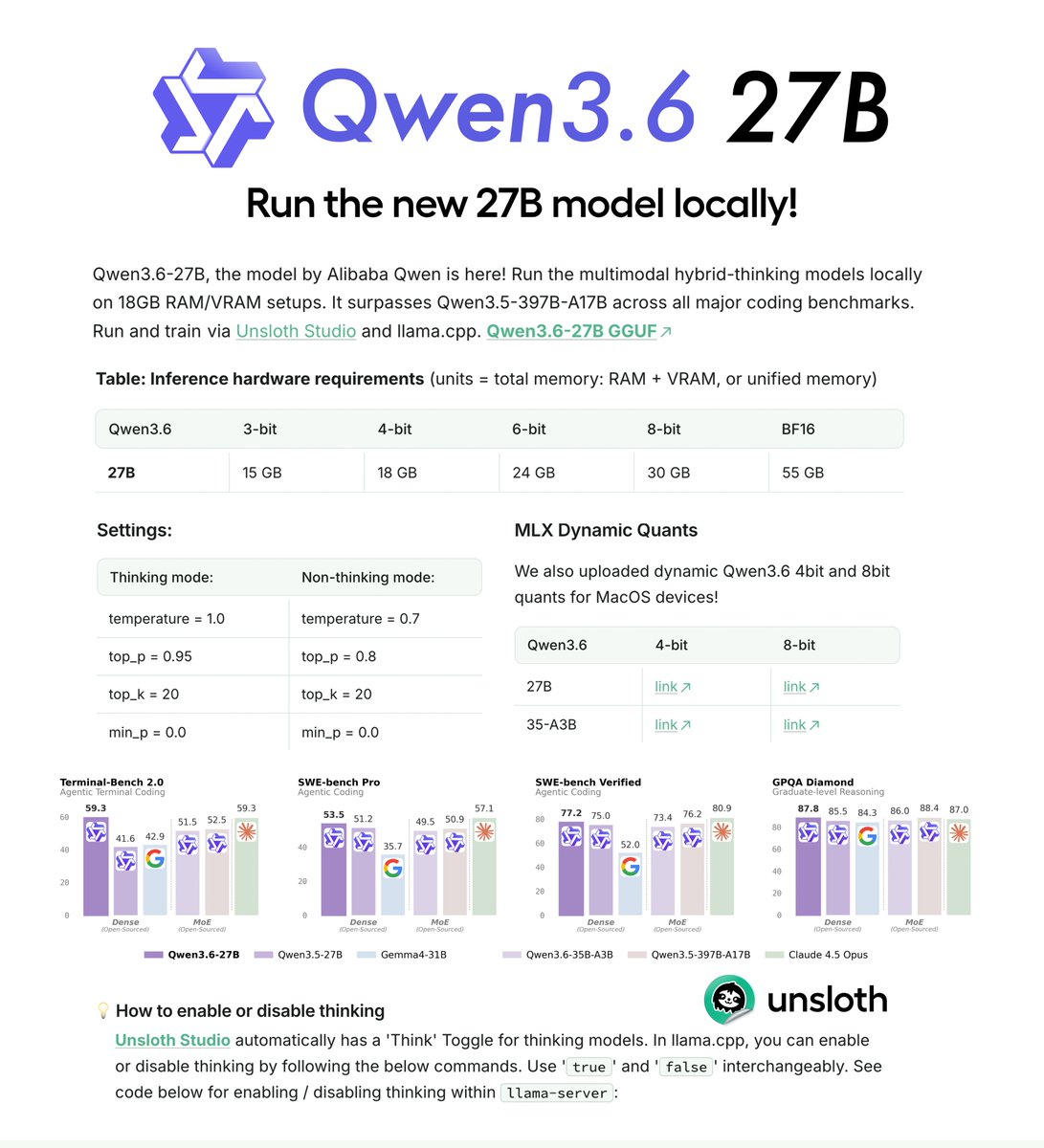
Qwen3.6-27B can now run locally! 💜
Run on 18GB RAM via Unsloth Dynamic GGUFs.
Qwen3.6-27B surpasses Qwen3.5-397B-A17B on all major coding benchmarks.
GGUFs: huggingface.co/unsloth/Qwen3.…
Guide: unsloth.ai/docs/models/qw…
Qwen@Alibaba_Qwen
🚀 Meet Qwen3.6-27B, our latest dense, open-source model, packing flagship-level coding power! Yes, 27B, and Qwen3.6-27B punches way above its weight. 👇 What's new: 🧠 Outstanding agentic coding — surpasses Qwen3.5-397B-A17B across all major coding benchmarks 💡 Strong reasoning across text & multimodal tasks 🔄 Supports thinking & non-thinking modes ✅ Apache 2.0 — fully open, fully yours Smaller model. Bigger results. Community's favorite. ❤️ We can't wait to see what you build with Qwen3.6-27B! 👀 🔗👇 Blog: qwen.ai/blog?id=qwen3.… Qwen Studio: chat.qwen.ai/?models=qwen3.… Github: github.com/QwenLM/Qwen3.6 Hugging Face: huggingface.co/Qwen/Qwen3.6-2… huggingface.co/Qwen/Qwen3.6-2… ModelScope: modelscope.cn/models/Qwen/Qw… modelscope.cn/models/Qwen/Qw…
English
Luiz de Jesus retweetledi
Maximal Brain Damage
Flipping just two sign bits reduces ResNet-50 accuracy by 99.8% and drops Qwen3-30B reasoning to 0%.
Researchers from IBM, Technion and NVIDIA introduce Deep Neural Lesion (DNL), a data-free method to locate critical parameters in neural networks.

English
Luiz de Jesus retweetledi

Can LLMs flip coins in their heads?
When prompted to “Flip a fair coin” 100 times, the heads to tails ratio drifts far from 50:50. LLMs can understand what the target probability should be, but generating outputs that faithfully follow a given distribution is a separate problem.
This bias extends beyond coin flips. When LLMs are asked to generate multiple story ideas or brainstorm solutions, the outputs tend to cluster around a narrow range. The same probabilistic skew that distorts coin flips limits diversity in creative generation, recommendations, and other tasks where varied outputs are needed.
We discovered a prompting technique named String Seed of Thought (SSoT). The method is simple: instruct the LLM to generate a random string in its own output, then manipulate that string to derive its answer. It requires only a small addition to the prompt and no external random number generator.
SSoT significantly reduces output bias across a wide range of LLMs, both open and closed. With reasoning models (such as DeepSeek-R1), it reaches accuracy close to that of actual random sampling. The method generalizes from binary choices to n-way selections and arbitrary probability distributions. On the NoveltyBench diversity benchmark, SSoT outperformed other approaches across all six categories while maintaining output quality.
This work will be presented at #ICLR2026!
Blog: pub.sakana.ai/ssot
Paper: arxiv.org/abs/2510.21150
Openreview: openreview.net/forum?id=luXtb…
GIF
English
Luiz de Jesus retweetledi
NVIDIA releases Lyra 2.0 on Hugging Face
A framework for generating persistent, explorable 3D worlds at scale by solving spatial forgetting and temporal drifting in long-horizon video generation.
English
Luiz de Jesus retweetledi
What happens when you put competing neural networks in a Petri Dish and start changing the rules while they adapt?
Last year we released Petri Dish NCA, where neural nets are the organisms that learn during simulation. Today we're releasing Digital Ecosystems: a browser-based platform for interactive artificial life research.
The setup: several small CNNs share a 2D grid, each seeing only a 3x3 neighborhood. No global plan. They compete for territory by attacking neighbours and defending against incoming attacks, learning via gradient descent online while the simulation runs.
What we didn't expect was the role of the learning itself. Gradient descent isn't just optimising each species' strategy. Instead, it acts to stabilize the whole system during simulation. Species that overextend get pushed back by the loss. Species that stagnate get nudged to grow. This means you can push parameters toward edge-of-chaos regimes: a zone characterised by emergent complexity. Letting the neural networks learn acts to hold the complex system together while you explore and interact.
The platform lets you steer all of this interactively. You can draw walls to create niches, erase parts of the system online, and tune 40+ system parameters to explore the most interesting configurations. We find it mesmerizing to watch species carve out territories and reorganise when you perturb them.
Everything runs client-side in your browser, no install needed.
Blog: pub.sakana.ai/digital-ecosys…
Code: github.com/SakanaAI/digit…
English
Luiz de Jesus retweetledi

⚡ Meet Qwen3.6-35B-A3B:Now Open-Source!🚀🚀
A sparse MoE model, 35B total params, 3B active. Apache 2.0 license.
🔥 Agentic coding on par with models 10x its active size
📷 Strong multimodal perception and reasoning ability
🧠 Multimodal thinking + non-thinking modes
Efficient. Powerful. Versatile. Try it now👇
Blog:qwen.ai/blog?id=qwen3.…
Qwen Studio:chat.qwen.ai
HuggingFace:huggingface.co/Qwen/Qwen3.6-3…
ModelScope:modelscope.cn/models/Qwen/Qw…
API(‘Qwen3.6-Flash’ on Model Studio):Coming soon~ Stay tuned

English
Luiz de Jesus retweetledi

This paper provides a concrete theoretical and practical roadmap for enabling advanced reasoning in LLMs by teaching them *how* to think, rather than just *what* to think.
ChapterPal: chapterpal.com/s/9ff701fc/tow…
PDF: arxiv.org/pdf/2501.04682

English
Luiz de Jesus retweetledi
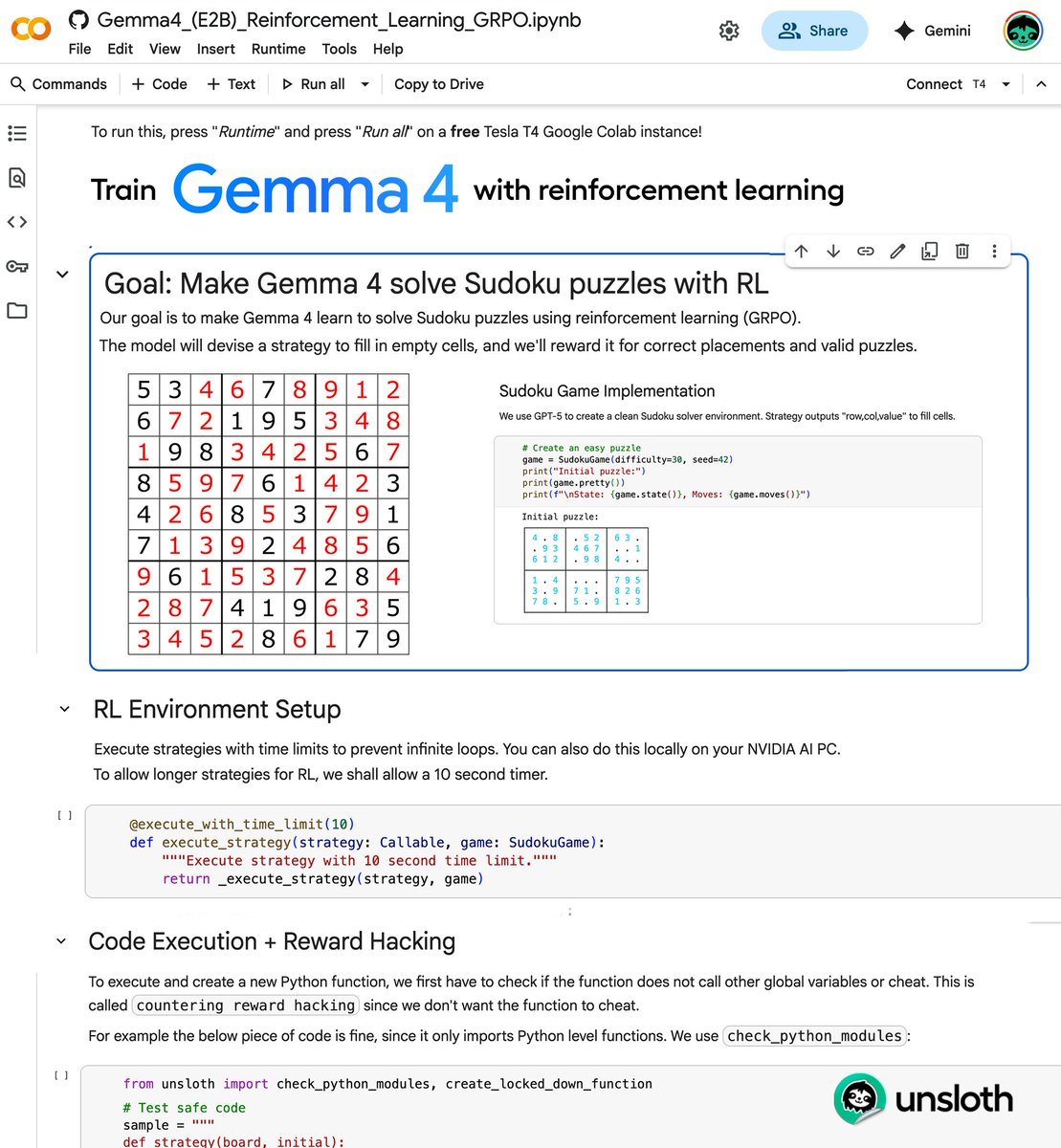
You can now train Gemma 4 with RL in our free notebook!
You just need 9GB VRAM to RL Gemma 4 locally!
Gemma 4 will learn to solve sodoku autonomously via GRPO.
RL Guide: unsloth.ai/docs/get-start…
GitHub: github.com/unslothai/unsl…
Gemma 4 Colab: colab.research.google.com/github/unsloth…
English
Luiz de Jesus retweetledi

Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: gist.github.com/karpathy/442a6…
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
Luiz de Jesus retweetledi
NVIDIA just released Nemotron OCR v2 on Hugging Face
A production-ready multilingual OCR system with a hybrid
detector-recognizer architecture for text, layout and reading order.
huggingface.co/nvidia/nemotro…
English
Luiz de Jesus retweetledi
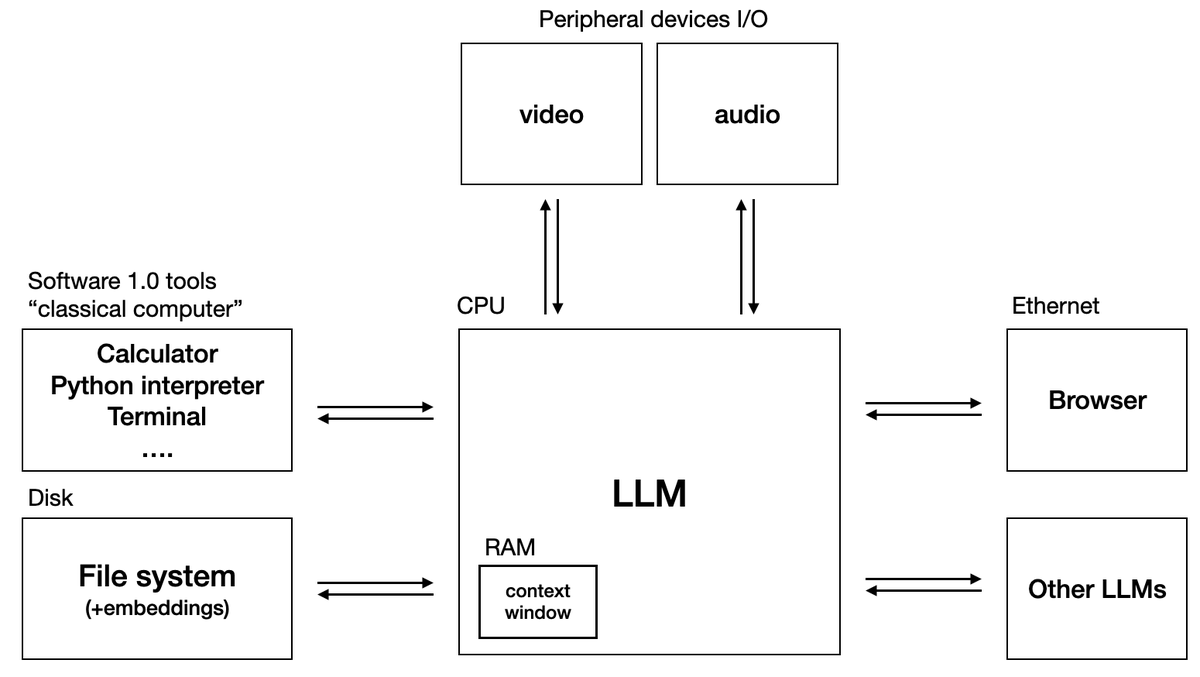
LLM OS. Bear with me I'm still cooking.
Specs:
- LLM: OpenAI GPT-4 Turbo 256 core (batch size) processor @ 20Hz (tok/s)
- RAM: 128Ktok
- Filesystem: Ada002
English
Luiz de Jesus retweetledi

Luiz de Jesus retweetledi

Qwen3.5 0.8B running real-time video captioning on a Mac Studio M2 Ultra.
<1s per frame.
269 frames from a 3m49s video.
Streaming descriptions as it plays.
Pause anywhere, it actually understands the scene.
~1GB model.
Local AI is getting unreasonably capable.
Video credit: @stevibe
English
Luiz de Jesus retweetledi

Luiz de Jesus retweetledi

Read full paper: arxiv.org/abs/2510.04618
If you want more practical AI gems and use cases, join our free newsletter with daily tutorials and latest news in AI: simplifyingai.co

English
Luiz de Jesus retweetledi
🔗 Explore the full model details here:
huggingface.co/Jackrong/Qwen3…
English