Sabitlenmiş Tweet

@simonw I’ve got text embeddings of Wikipedia for semantic search in the browser at leebutterman.com/wikipedia-sear…
GIF
English
Lee Butterman
3.4K posts

@leebutterman
🏳️🌈 · 🚴 · 🏞️ · 🏜️ · ⦿⪥ · 🤖🧠


Time for another SF DSPy meetup, this time focusing on DSPy in production use cases and RLMs. Engineers from @Dropbox and @Shopify will be sharing case studies and answering questions, and @isaacbmiller1 will walk through DSPy's RLM module. Come! luma.com/je6ewmkx

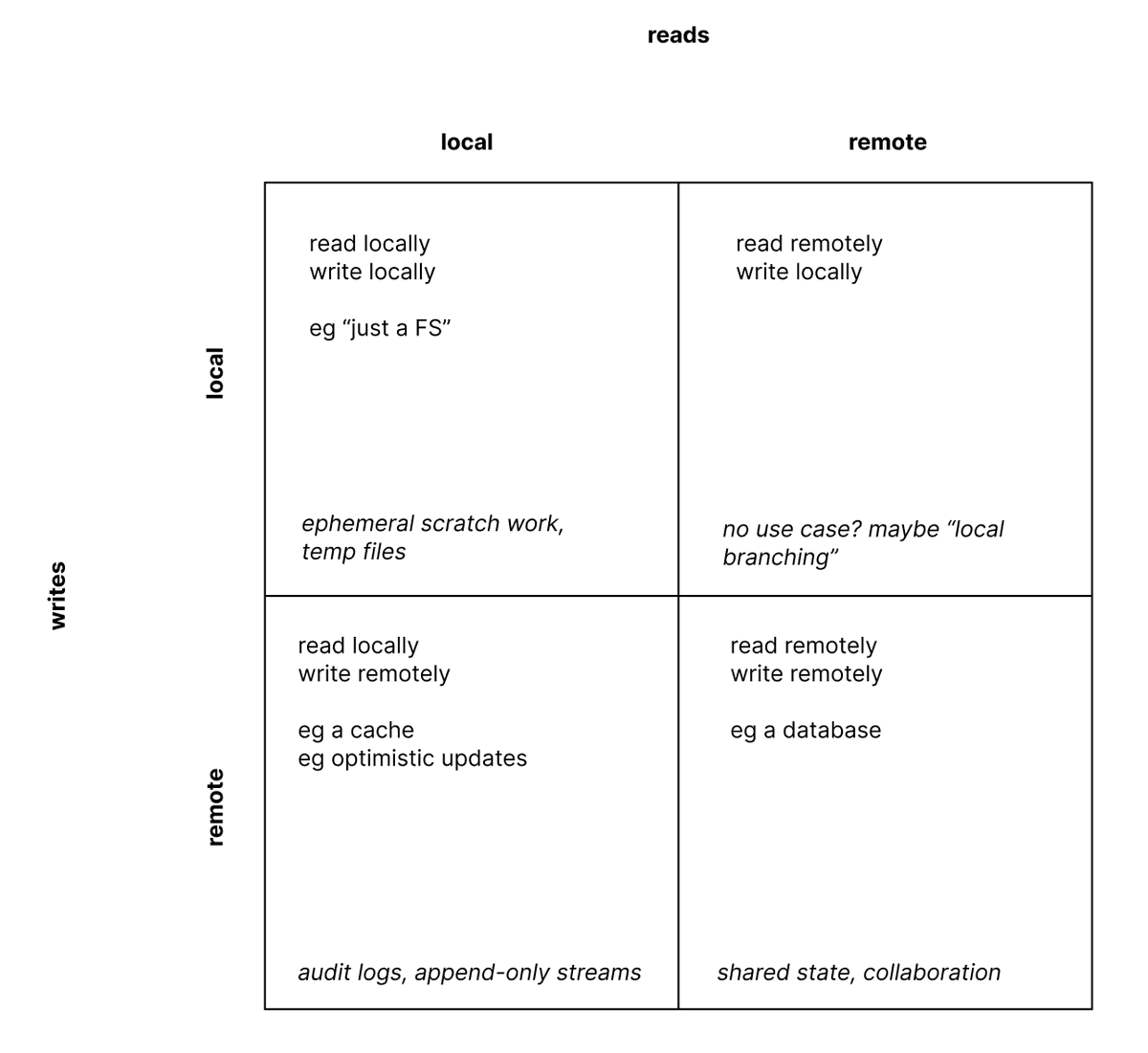


There’s a growing time and place for ‘vibe coding’, but it’s disastrous that it doesn’t record the produced system at the level of abstraction it was built. Imagine if the only way to use C was to compile isolated snippets of assembly. We need higher-level programming languages.

DSPy on a Pi: Cheap Prompt Optimization with GEPA and Qwen3 “It took me about sixteen hours on a Raspberry Pi to boost performance of chat-to-SQL using Qwen3 0.6B from 7.3% to 28.5%. Using gpt-oss:20b, to boost performance from ~60% to ~85% took 5 days.”

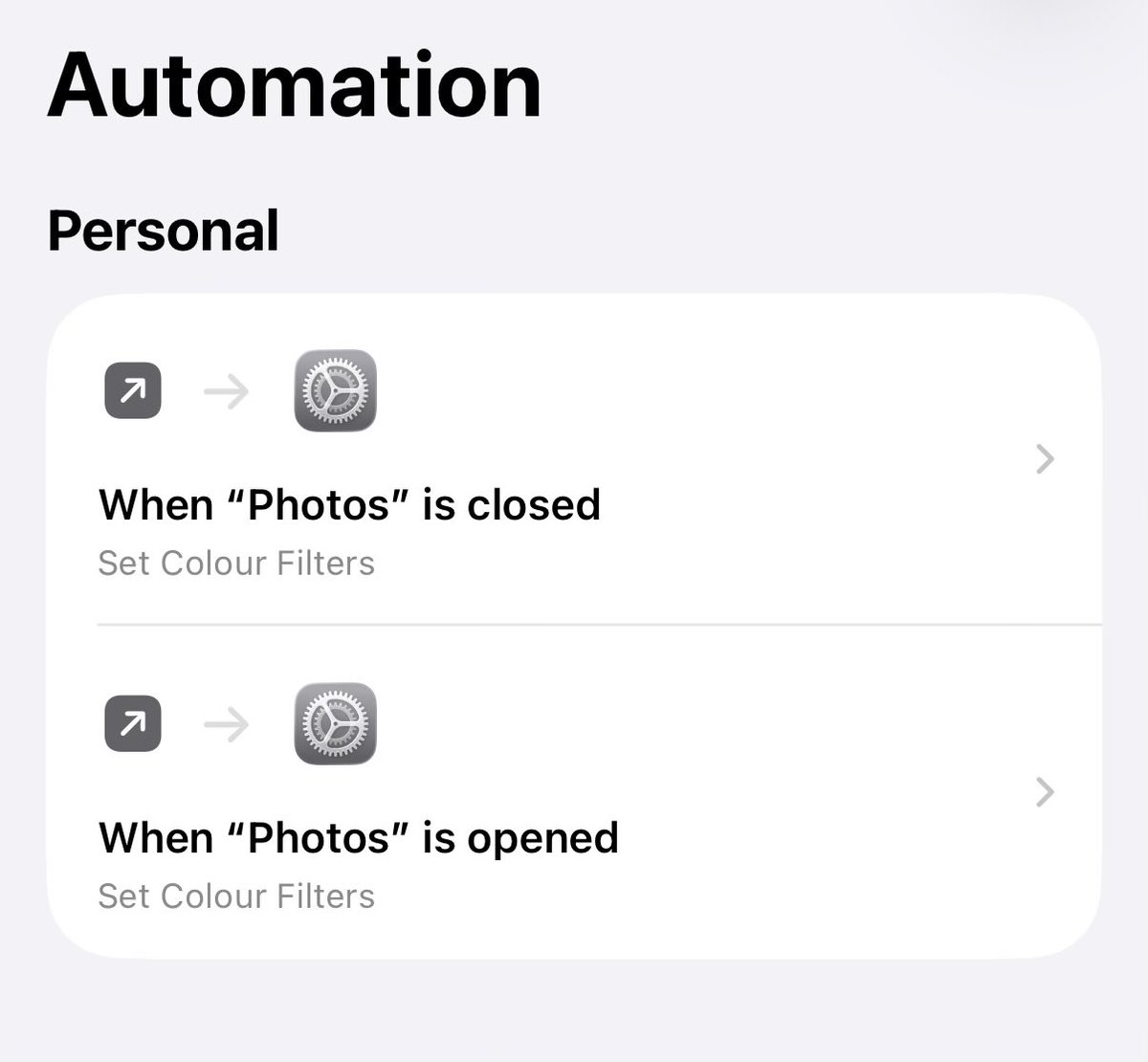
holy shit putting ur phone in greyscale really does break the mind control

In the age of AI for coding, Software Engineering strikes again… prompt optimization as the missing link for helping people discover latent requirements (Slide courtesy of @ChrisGPotts at the Bay Area @DSPyOSS meetup tonight)


DSPy on a Pi: Cheap Prompt Optimization with GEPA and Qwen3 “It took me about sixteen hours on a Raspberry Pi to boost performance of chat-to-SQL using Qwen3 0.6B from 7.3% to 28.5%. Using gpt-oss:20b, to boost performance from ~60% to ~85% took 5 days.”

has anyone of you used DSPy with GEPA in a production setting? the tutorials state around >10% improvements for most examples. seems like free performance, so i am a bit skeptic.




A frustrated startup founder came to me recently complaining about the devs he's been using for the past 10+ years. He's shocked at how fast we're moving on product with just a couple of people. His VP of eng and devs refuse to use AI, still builds on waterfall. Every feature takes 6-8 weeks between ideation, PRD, design, dev and testing. It blows my mind these devs still exist. But times are catching up and we're entering the "adopt or get left behind phase" The CEO and VP has been together for 10+ years, so transition isn't as clear cut. But they're now at the point where it's irresponsible to the investors not to do something. Take this however you will.

@MarkovMagnifico Because of the interest-on-interest, you really shouldn't leave it indefinitely. You will pay, eventually.




