Sabitlenmiş Tweet
Levi
1.1K posts


@__mujeeb__ Exactly! Not to mention labs buy data from bench providers and post train… What datasets did you use?
English

This is the exact problem with LLM-as-judge evals. The judge scores the output, not the consequence. I built an adversarial eval tier for a clinical trial agent specifically because passing 28/30 cases meant nothing if the 2 failures were confident wrong citations. The benchmark hides what matters.
English
Thanks to @mercor_ai @appliedcompute @BrendanFoody for the work on APEX Agents bench, and @cursor_ai @AnthropicAI for the continued inspiration.
English
(7/7) Right now, code is the easiest domain to evaluate. We want to build the equivalent benchmarks for real-world documents. If you’re building vertical AI, researching document engineering, or wrestling with deployment gaps, let's chat.
Full blog post: raycaster.ai/blog/benchmark…
English
@lateinteraction @mixedbread What makes RLM with colBERT special? Haven't seen an apples to apples comparison against a well-designed good grep + semantic search. Also, isn't the challenge still around parsing and indexing over a fast changing repo?
English

Look at these results carefully.
Codex and Gemini 3, with gemini file search and codex default tools, versus with @mixedbread’s new late interaction model.
Soon enough, if your coding agent is not an RLM with ColBERT file search, you’re ngmi.
Mixedbread@mixedbreadai
For Agentic tasks, Oracle-level performance is the maximum performance a system can achieve, assuming it is able to retrieve all relevant documents perfectly, every time. We're proud to show that Mixedbread Search approaches the Oracle on multiple knowledge intensive benchmarks.
English

RAG‘s dead. Use search agents instead.
That’s also what Anthropic found early on for codebase search as opposed to indexing the whole codebase and performing vector search to find relevant code.

English
@mattpocockuk Know a good benchmark to test this? Anecdotally it makes sense but then it defeats the whole purpose of those long horizon tasks
English

Doing some experiments today with Opus 4.6's 1M context window.
Trying to push coding sessions deep into what I would consider the 'dumb zone' of SOTA models: >100K tokens.
The drop-off in quality is really noticeable. Dumber decisions, worse code, worse instruction-following.
Don't treat 1M context window any differently.
It's still 100K of smart, and 900K of dumb.
English

Context engineering isn't just about assembling the right context at the start. It's becoming a profession of managing context dynamically throughout a task.
When you think about the amount of context (not only in the window but with progressive disclosure with connectors) we started giving to models, this makes even more sense.
"agent trajectories are expanding faster than the context length of models"
Another observation is that agent harnesses are converging with models themselves this year. Since compaction is still one of the biggest bottlenecks in long-running agents, Cursor's experiment is quite interesting.
1. Self-Summarization = RL-Trained Context Engineering
They trained the Composer model to summarize its own context as a learned behaviour via RL instead of a separate agent harness implementation.
The model learns what information matters through reward signals. This approach shows that the most effective compaction happens when the model itself learns relevance, not when a human writes a summary template.
2. The 50% Compaction Error Reduction With 1/5th the Tokens
Their trained self-summarization reduces compaction error by 50% while using one-fifth as many tokens as the baseline prompt.
The baseline had 12 sections and produced 5,000+
token summaries. Self-summarization produces ~1,000 tokens from a minimal prompt ("Please summarize the conversation").
I'm very excited about open-source context management models that are trained for this behaviour, anyone working on this?
3. Context Chaining > Single-Shot Generation
Cursor's training loop chains multiple generations with summaries. Each rollout is a full trajectory with summarization checkpoints. The final reward propagates back through the entire chain, reinforcing both good agent actions and good summaries.
Self-summarization is an alternative so instead of passing full context at each handoff, train agents to self-summarize at handoff boundaries. The reward signal teaches them what's load-bearing vs. noise.
They're making compaction part of the training loop rather than an external module. They also say that compaction (summarization, sliding windows, latent space approaches) is one of the core unsolved problems in agentic AI.
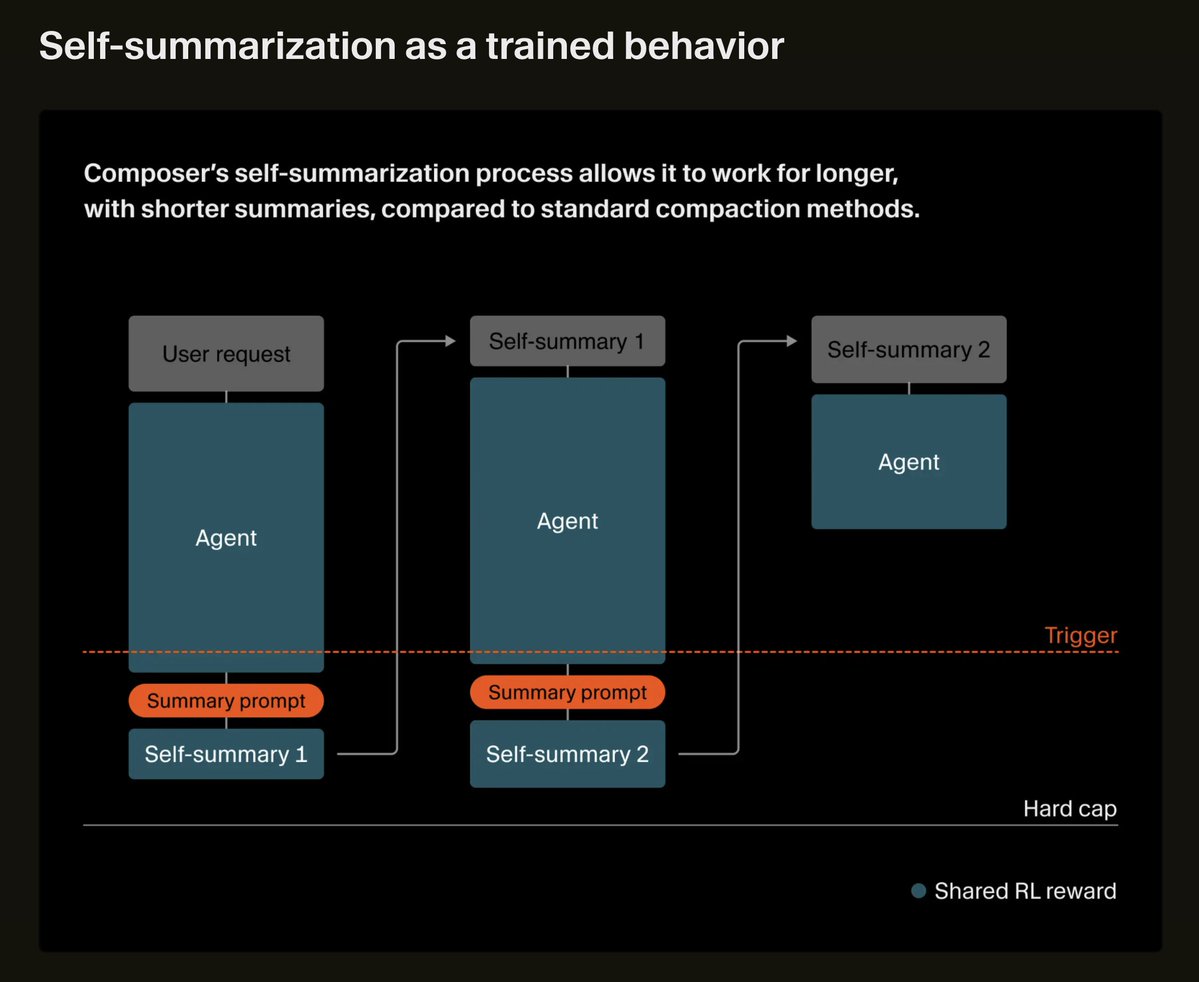
Cursor@cursor_ai
We trained Composer to self-summarize through RL instead of a prompt. This reduces the error from compaction by 50% and allows Composer to succeed on challenging coding tasks requiring hundreds of actions.
English
Finally, a rational perspective on @cursor_ai. I’ve long admired the team and what they’ve built.
The real takeaway actually extends far beyond software: if the labs don't have a monopoly on success in coding, they won't have one in any other professional field either :)
Barry McCardel@barrald
The Cursor vs. Claude/Codex feels very flawed and missing the bigger picture The labs have ~infinite money and specialized talent, and are going to win on coding models – that's a runaway train. Composer is impressive, but ultimately more for margin protection / defense than playing to win that game. But to quote Stringer Bell, "there are games beyond the game" and I believe Cursor's destiny is different: becoming the new Github – the place where the whole engineering process lives. Their real competition is with them and Linear, not the labs. Bugbot is a great start. We find it super valuable, no matter what coding agent is used, and is a nice wedge into Cursor getting beyond the coding itself. And of course acquiring @graphite. PR review is the single most essential workflow in Github and very ripe for disruption – Cursor is in an amazing position for this. More on the horizon. The cloud sandbox thing is going to be huge. The new Automations thing aims at GH Actions. And it wouldn't surprise me to see them start getting more into security, observability, etc. Could Anthropic/OpenAI try to compete here? Sure. But I don't think customers want them to. I want my coding agent to be a coding agent and would be happy to pay for another model-agnostic system that sits across the whole menagerie and help me manage it. My prediction is that in a year we'll look back at the "Claude Code is great, therefore Cursor is cooked" discourse as misguided, and understand Cursor as playing a different game entirely.
English

Referee Christian Dingert admits he made a mistake by sending off Luis Díaz: "During the game, I perceived the incident as him diving. That's what I saw. Looking at the footage now, it's clear it wasn't a penalty. But a red card was very harsh; I wouldn't give that now." [Sky]
English
@hud_evals Need to open source the dataset or let the public run the eval :)
English

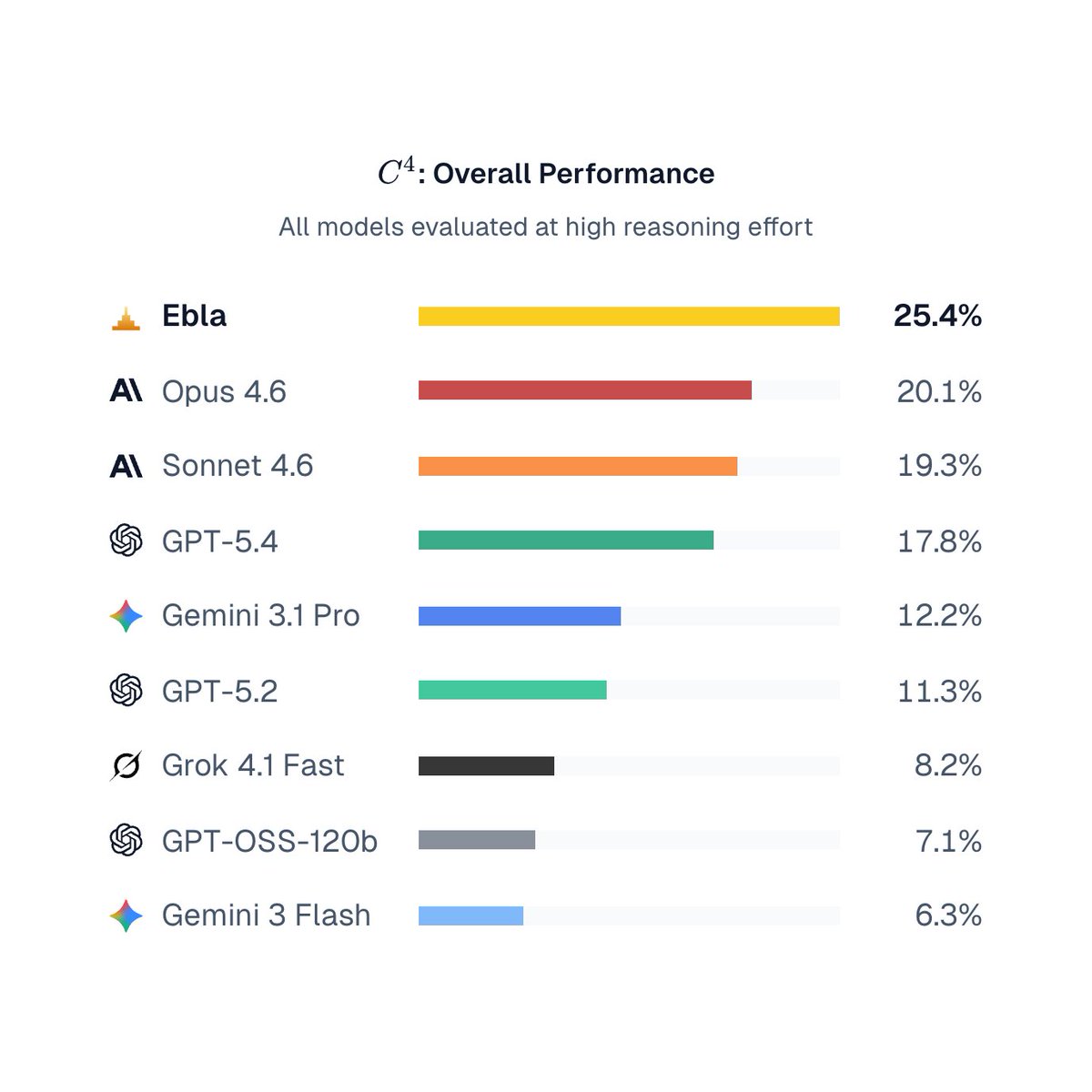
Aviro is introducing Ebla, a state of the art grounded reasoning model.
In collaboration with HUD, the Aviro team built C⁴ — a benchmark for long-horizon tasks in corporate document sets. We evaluate four dimensions: Correctness, Completeness, Composition, and Citations.
@aviro_ai post-trained GPT-OSS 120b to achieve SOTA performance, with a Pass@1 score of 25.4% and Pass@8 score of 37.1%.
English
@Starwatcher_vc Lots of think pieces on this topic, but with good parsing, grep, and multi-modal indexing, you’re 99% of the way to a sound system.
English

The problem with vector databases are not the thing itself but how they are used. All those chunking strategies are poor way how to prepare data. Using single vector embeddings is poor way to represent and retrieve data.
Good late interaction models are the way to go. Rich multi-vector representation is a way. Data prepared consistently by an agent is a way to go. Follow @antoine_chaffin, @mixedbreadai, @bclavie and @lateinteraction to get into late interaction bubble.
English
The flaw in "AI for Office" tools is they try to stay inside the app then add context.
But real enterprise work spans thousands of files across different systems.
We solved this context gap for biopharma and energy giants. Now expanding to everyone office worker. @raycasterai
Felix Rieseberg@felixrieseberg
Shipping today: Small but meaningful updates to Claude in Excel & PowerPoint! We obviously want Claude to be helpful in your work lives across a wide range of apps and data - and with this change, PowerPoint & Excel can share context and gain support for Skills. claude.com/blog/claude-ex…
English
@_simonsmith Would love to have you try raycaster.ai and compare. We've outperformed all models on Office skills in Apex benchmarks. Let me know how we can set it up for you.
English

So, ChatGPT team responsible for presentations: the Slides skill (at least in Codex; assuming also ChatGPT) is undermining GPT-5.4's ability to create good presentations. Opus helped me diagnose some issues:
1. It's using LAYOUT_WIDE as the default, which is 13.33" × 7.5", instead of a standard 16:9 of 10" × 5.625".
2. The helpers and authoring rules create too much complexity. If I want a few slides, it has to go through so much complex work, which takes a long time and doesn't seem to help. Opus notes: "There are 2,371 lines of JavaScript helpers... The skill tells ChatGPT to copy this entire folder into the workspace and use it. For a 20-slide data-dense deck this makes sense. For a simple slide, it's like handing someone a CNC machine to cut a piece of paper." Good one :)
3. There's no design guidance. According to Opus, "The word 'design' doesn't appear once in the SKILL.md. No color palette suggestions. No typography pairing advice. No layout principles. No guidance on restraint or whitespace. No examples of what 'good' looks like versus 'bad.'"
Some recommendations:
- Let ChatGPT work freely in PptxGenJS when warranted, such as for simple slides.
- Add some design principles and guidance
- Change the default layout to LAYOUT_16x9
- Add 2-3 example outputs as visual references
English