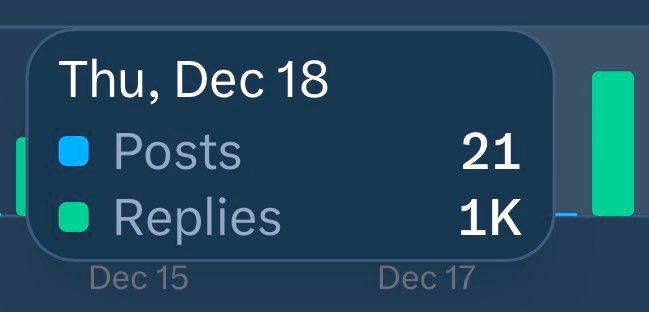
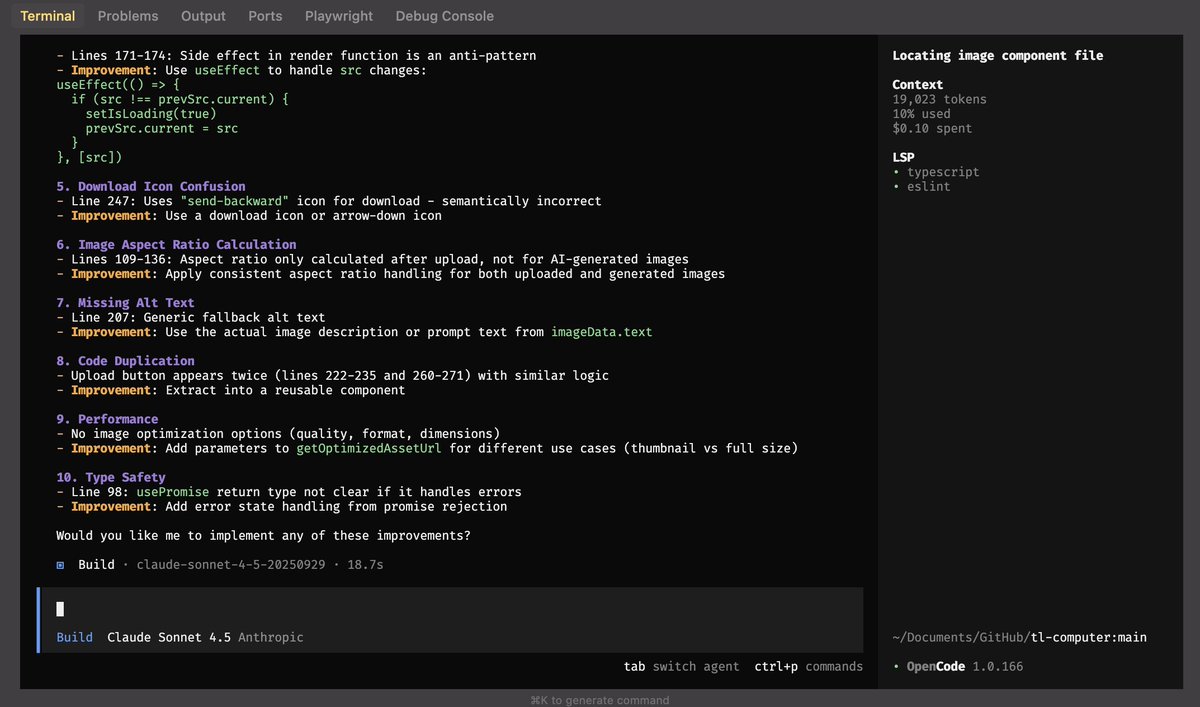
lgrd retweetledi

I get a lot of questions about how my @obsdmd vault is set up.
Theming, settings, plugins, fonts etc.
Here is a list of everything I have done to get my vault looking and feeling the way it does.
🧵

English
lgrd
42 posts


@lgrd149
Faith | 1st Place Sui Bootcamp HCMC Hackathon 2025 💧🏆 | Mobile dev @purro_xyz

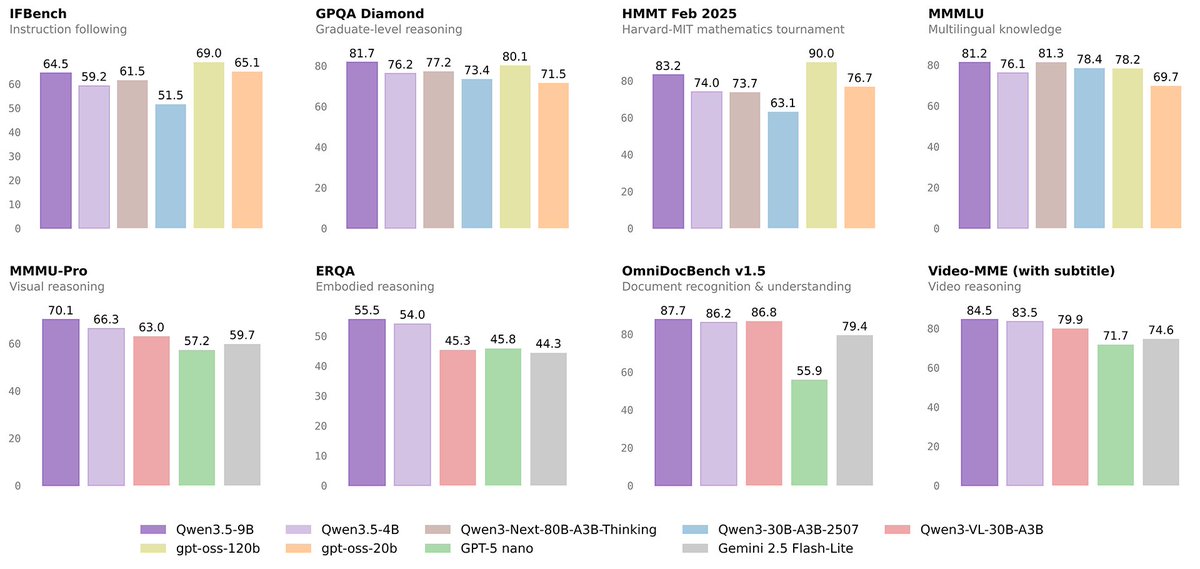





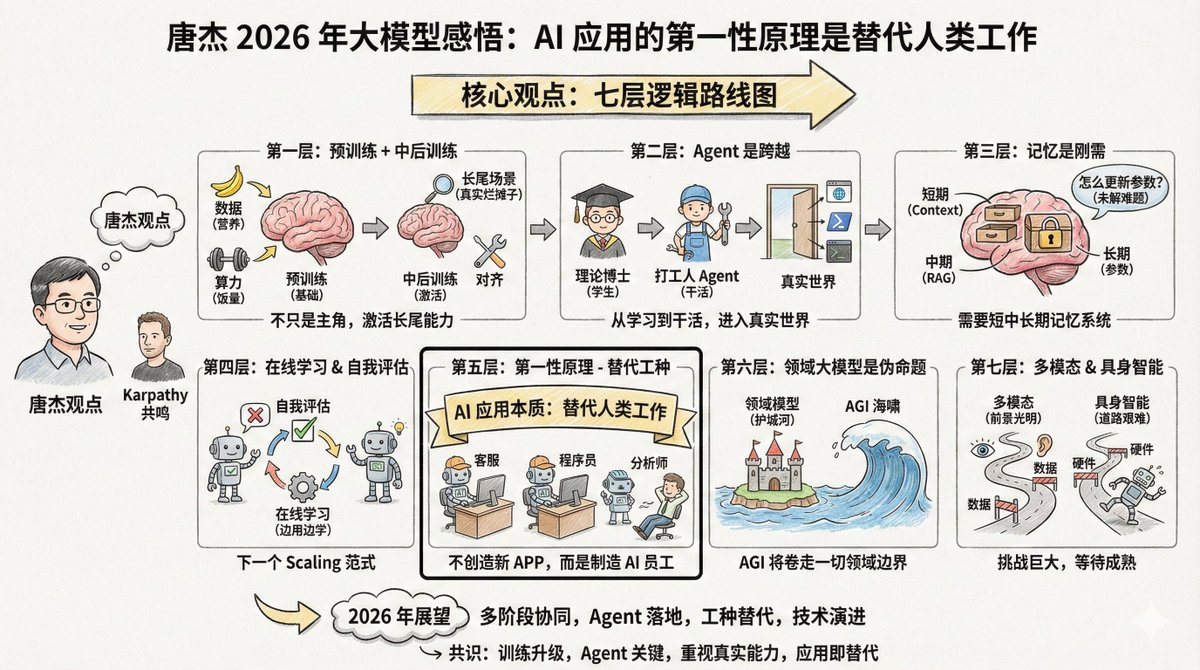
Andrej Karpathy 是 OpenAI 联合创始人、前特斯拉 AI 总监,也是全球最有影响力的 AI 研究者之一。他刚刚发布了一篇 2025 年 LLM 年度回顾。 第一个大变化:训练方法的范式升级 2025 年之前,训练一个好用的大模型基本是三步走:预训练、监督微调、人类反馈强化学习。这个配方从 2020 年用到现在,稳定可靠。 2025 年多了关键的第四步:RLVR,全称是 Reinforcement Learning from Verifiable Rewards,翻译过来就是「可验证奖励的强化学习」。 什么意思?简单说,就是让模型在「有标准答案」的环境里反复练习。比如数学题,答案对就是对,错就是错,不需要人来打分。代码也一样,能跑通就是能跑通。 这和之前的训练有什么本质区别?之前的监督微调和人类反馈,本质上是「照葫芦画瓢」,人给什么样本,模型学什么样本。但 RLVR 不一样,它让模型自己摸索出解题策略。就像学游泳,之前是看教学视频模仿动作,现在是直接扔水里,只要你能游到对岸,怎么划水我不管。 结果呢?模型自己「悟」出了看起来像推理的东西。它学会了把大问题拆成小步骤,学会了走错路时回头重来。这些策略如果靠人类标注示范,根本标不出来,因为人自己也说不清「正确的思考过程」长什么样。 这个变化带来一个连锁反应:算力的分配方式变了。以前大部分算力砸在预训练阶段,现在越来越多算力用于 RL 阶段。模型的参数规模没怎么涨,但推理能力飙升。OpenAI 的 o1 是这条路的起点,o3 是真正让人「感觉到不一样」的拐点。 还有个新玩法:推理时也能花更多算力。让模型「想久一点」,生成更长的推理链条,效果就更好。这相当于多了一个调节能力的旋钮。 第二个大变化:我们终于搞懂了 AI 是什么「形状」的聪明 Karpathy 用了一个很妙的比喻:我们不是在「养动物」,而是在「召唤幽灵」。 人类的智能是进化出来的,优化目标是「在丛林里让部落活下去」。大模型的智能是训练出来的,优化目标是「模仿人类文本、在数学题里拿分、在评测榜单上刷分」。 优化目标完全不同,出来的东西当然也完全不同。 所以 AI 的智能是「参差不齐」的,英文叫 jagged intelligence。它可以在某些领域表现得像全知全能的学者,同时在另一些领域犯小学生都不会犯的错。上一秒帮你推导复杂公式,下一秒被一个简单的越狱提示骗走你的数据。 为什么会这样?因为哪个领域有「可验证的奖励」,模型在那个领域就会长出「尖刺」。数学有标准答案,代码能跑测试,所以这些领域进步飞快。但常识、社交、创意这些领域,什么是「对」很难定义,模型就没法高效学习。 这也让 Karpathy 对基准测试失去了信任。道理很简单:测试题本身就是「可验证环境」,模型完全可以针对测试环境做优化。刷榜变成了一门艺术。所有基准都刷满了,但离真正的通用智能还差得远,这是完全可能发生的事。 第三个大变化:LLM 应用层浮出水面 Cursor 今年火得一塌糊涂,但 Karpathy 认为它最大的意义不是产品本身,而是证明了「LLM 应用」这个新物种的存在。 大家开始讨论「X 领域的 Cursor」,这说明一种新的软件范式成立了。这类应用做什么? 第一,做上下文工程。把相关信息整理好,喂给模型。 第二,编排多个模型调用。后台可能串了一堆 API 调用,平衡效果和成本。 第三,提供专业场景的界面。让人类能在关键节点介入。 第四,给用户一个「自主程度滑杆」。你可以让它多干点,也可以让它少干点。 有个问题被讨论了一整年:这个应用层有多「厚」?模型厂商会不会把所有应用都吃掉? Karpathy 的判断是:模型厂商培养的是「有通用能力的大学毕业生」,但 LLM 应用负责把这些毕业生组织起来、培训上岗,变成能在具体行业干活的专业团队。数据、传感器、执行器、反馈循环,这些都是应用层的活。 第四个大变化:AI 搬进了你的电脑 Claude Code 是今年最让 Karpathy 印象深刻的产品之一。它展示了「AI 智能体」应该长什么样:能调用工具、能做推理、能循环执行、能解决复杂问题。 但更关键的是,它跑在你的电脑上。用你的环境、你的数据、你的上下文。 Karpathy 认为 OpenAI 在这里判断失误了。他们把 Codex 和智能体的重心放在云端容器里,从 ChatGPT 去调度。这像是在瞄准「AGI 终局」,但我们还没到那一步。 现实是,AI 的能力还是参差不齐的,还需要人类在旁边看着、配合着干活。把智能体放在本地,和开发者并肩工作,才是当下更合理的选择。 Claude Code 用一个极简的命令行界面做到了这一点。AI 不再只是你访问的一个网站,而是「住在」你电脑里的一个小精灵。这是一种全新的人机交互范式。 第五个大变化:Vibe Coding 起飞了 2025 年,AI 的能力跨过了一个门槛:你可以纯用英语描述需求,让它帮你写程序,完全不用管代码长什么样。Karpathy 随手发了条推特,给这种编程方式起了个名字叫 vibe coding,结果这个词火遍全网。 这意味着什么?编程不再是专业程序员的专利,普通人也能做。这和过去所有技术的扩散模式都不一样。以前新技术总是先被大公司、政府、专业人士掌握,然后才慢慢下沉。但大模型反过来,普通人从中受益的比例远超专业人士。 不只是「让不会编程的人能编程」。对会编程的人来说,很多以前「不值得写」的小程序现在都值得写了。Karpathy 自己就用 vibe coding 做了一堆项目:用 Rust 写了个定制的分词器、做了好几个工具类 App、甚至写了一次性的程序只为找一个 bug。 代码突然变得廉价、即用即弃、像草稿纸一样随便写。这会彻底改变软件的形态和程序员的工作内容。 第六个大变化:大模型的「图形界面时代」要来了 Google 的 Gemini Nano Banana 是今年最被低估的产品之一。它能根据对话内容实时生成图片、信息图、动画,把回复「画」出来而不是「写」出来。 Karpathy 把这件事放到更大的历史脉络里看:大模型是下一个重大计算范式,就像 70 年代、80 年代的计算机一样。所以我们会看到类似的演进路径。 现在和大模型「聊天」,有点像 80 年代在终端敲命令。文字是机器喜欢的格式,但不是人喜欢的格式。人其实不爱读文字,读文字又慢又累。人喜欢看图、看视频、看空间布局。这就是传统计算机为什么要发明图形界面。 大模型也需要自己的「GUI」。它应该用我们喜欢的方式跟我们说话:图片、幻灯片、白板、动画、小应用。现在的 Emoji 和 Markdown 只是初级形态,帮文字「化个妆」。真正的 LLM GUI 会是什么样?Nano Banana 是一个早期暗示。 最有意思的是,这不只是图像生成的事。它需要把文本生成、图像生成、世界知识全部绞在一起,在模型权重里融为一体。 Karpathy 的总结是这样的:2025 年的大模型,比他预期的聪明,也比他预期的蠢。两者同时成立。 但有一点很确定:即使以现在的能力,我们连 10% 的潜力都没挖掘出来。还有太多想法可以试,整个领域感觉是敞开的。 他在 Dwarkesh 的播客里说过一句看似矛盾的话: > 他相信进步会继续飞速推进, > 同时也相信还有大量的工作要做。 两件事并不矛盾。2026 年系好安全带继续加速吧。