Clanaid
28 posts





最新ChatGPT Team 48个月优惠,美区优惠码来了,亲测有效,订阅时招行卡拒绝,Bitget成功。
此外需要更改代码把英国的改到美国,开通链接如下chatgpt.com/?promoCode=Tec…
测试成功时间:2026.5.11 (北京时间)
改动后代码如下:
(async function generateAUTeamLink() {
console.log("⏳ 正在获取B Session Token...");
// 自动获取登录凭证
let accessToken;
try {
const s = await fetch("/api/auth/session").then(r => r.json());
accessToken = s?.accessToken;
if (!accessToken) throw new Error("accessToken 为空");
} catch (e) {
console.error("❌ 获取 Token 失败:", e.message);
return;
}
console.log("✅ Token 获取成功");
const COUPON = "TechAheadUS";
// ---- 以下为你提供的 Payload(仅修改 workspace_name 动态生成)----
const payload = {
plan_name: "chatgptteamplan",
team_plan_data: {
workspace_name: "workspace", // 可自行修改
price_interval: "month", // month 或 year
seat_quantity: 2, // 席位数量,Team 最少 2?1的话是另外种玩法,需要号
},
billing_details: {
country: "US",
currency: "USD"
},
cancel_url: "chatgpt.com/?promoCode=Tec…",
promo_code: COUPON, // 注意这里用的是 promo_code 字段
checkout_ui_mode: "hosted"
};
console.log("⏳ 正在请求 Stripe 长链接 (US)...");
try {
const resp = await fetch(
"chatgpt.com/backend-api/pa…",
{
method: "POST",
headers: {
Authorization: `Bearer ${accessToken}`,
"Content-Type": "application/json"
},
body: JSON.stringify(payload)
}
);
const data = await resp.json();
if (!resp.ok) {
console.error(`❌ 请求失败 HTTP ${resp.status}`);
console.log("📋 响应详情:", data);
return;
}
const hostedUrl = data?.url || data?.stripe_hosted_url || data?.checkout_url;
if (!hostedUrl) {
console.warn("⚠️ 未找到长链接,原始响应:", data);
return;
}
console.log("─".repeat(60));
console.log("✅ ChatGPT Team 链接生成成功!(美国)");
console.log("📋 Checkout Session ID :", data.checkout_session_id);
console.log("📌 计划 : ChatGPT Team (US/USD)");
console.log("💺 席位 :", payload.team_plan_data.seat_quantity);
console.log("🎟️ 优惠码 :", COUPON);
console.log("🔗 Stripe 长链接:");
console.log(hostedUrl);
console.log("─".repeat(60));
} catch (e) {
console.error("❌ 网络异常:", e.message);
}
})();

Ean@neostify
中文









在构建企业 AI Agent 的时候,工作上下文(Context)是不可或缺的元素,那什么是好的 Context,又如何构建好的 Context?
好的 Context,是一套能让 AI 理解“此刻该如何行动”的组织记忆系统,它至少包含四层:
1)情境记忆。也就是发生过什么、谁说过什么、在哪个时间点做过什么决定。这对应 Endel Tulving 在 1972 年提出的 episodic memory,对具体事件和经历的记忆。对企业来说,聊天、会议、文档、项目流、审批、工单,都是情境记忆。它的价值在于保留现场,让 AI 在面对结论时,同时能够理解当时的路径和判断过程。
2)语义记忆。也就是从大量情境中抽象出来的稳定知识,例如规则、术语、流程、产品定义、组织共识、经验方法。Tulving 把 semantic memory 作为一种不依赖具体经历的知识系统。知识库真正产生价值的地方,在于把零散材料逐渐沉淀成可以反复使用的结构。
3)程序化记忆。也就是“遇到某类问题应该怎么做”。后续的记忆研究中,procedural memory 常被单独拿出来看。映射到 AI 系统里,就是 SOP、模板、工作流、工具调用策略、Agent Skill。它会直接影响系统停留在建议层,还是能够进一步进入执行层。
4)工作记忆。也就是当前任务窗口里,AI 临时需要的那一小块高相关信息。像 MemGPT 这样的工作,会把 LLM 的上下文窗口当成一种稀缺资源,通过分层管理来调用更大的长期记忆。这个视角很关键,Context 的核心在匹配程度,是否刚好支撑当前任务。
那 Context 如何被有效地组织起来,让它变成真正有价值的 Agent 语料呢?不同的场景,需要不同的处理策略。
例如在复杂项目推进、多人协作决策、跨周期目标管理中,对上下文的处理,适用于递归式记忆蒸馏与回注机制(Recursive Distillation & Grounding)。在认知科学里,它更像是从情境记忆不断压缩到语义记忆,再反向投射回情境的一种循环。
它有两个同时发生的动作:1)一条是向上抽象,日报 → 周报 → 月报,本质是在做信息压缩,把大量具体事件提炼成模式、趋势和判断;2)另一条是向下穿透,周报和月报反过来影响日报,让后续记录逐渐带上结构和重点,减少无序堆积。
这两条链路形成一个闭环:经历不会直接沉没,而是不断被压缩、再利用、再强化。这和 Endel Tulving 提出的记忆转化过程是高度一致的:经历会逐渐抽象为知识,知识也会进一步参与后续行为的生成。
类似的探索,在工作场景中,还有一些常见的组织模式:
1)情境重构机制(Context Reframing),适用于问题推进卡住、讨论反复震荡的阶段。很多时候限制来自问题所处的框架本身。通过调整问题的边界、目标或观察视角,再把已有记录重新放进去看,会发现原本难以推进的讨论开始出现新的路径。同一批信息,在不同结构下会导向完全不同的判断,这种能力更像是在主动切换解空间。
2)记忆遗忘与权重衰减机制(Forgetting & Decay),适用于信息持续累积、系统开始变慢或噪声变多的阶段。信息如果被一视同仁地保留,会逐渐拖慢判断节奏。更有效的方式,是让信息在使用中自然分层,低频、过期、无效的内容逐渐退出核心上下文,高频被引用、对关键决策有贡献的内容则持续被强化。时间拉长之后,系统会变得更轻,也更准。
3)任务驱动的 Context 编排机制(Context Assembly),适用于多任务并行或 AI 执行复杂流程的场景。上下文围绕当前目标展开,挑选出最相关的一小部分信息,并按照任务需要组织起来。不同任务对应不同的上下文切片,这种按需组装的方式,可以在有限空间内保持信息的高相关性,让执行过程更稳定,也更可控。
Context 是生长出来的,需要逐步清洗、过滤和沉淀,形成对个体和团队分别有效的上下文。
从当下开始,去构建自己工作/生活/学习的上下文,逐步让 AI 进来参与决策,AI 会帮助我们慢慢沉淀出一套稳定的认知结构,直接影响判断的质量与方向。
或许,这也是让自己从繁琐的事务中解脱出来的必要路径。😄

中文

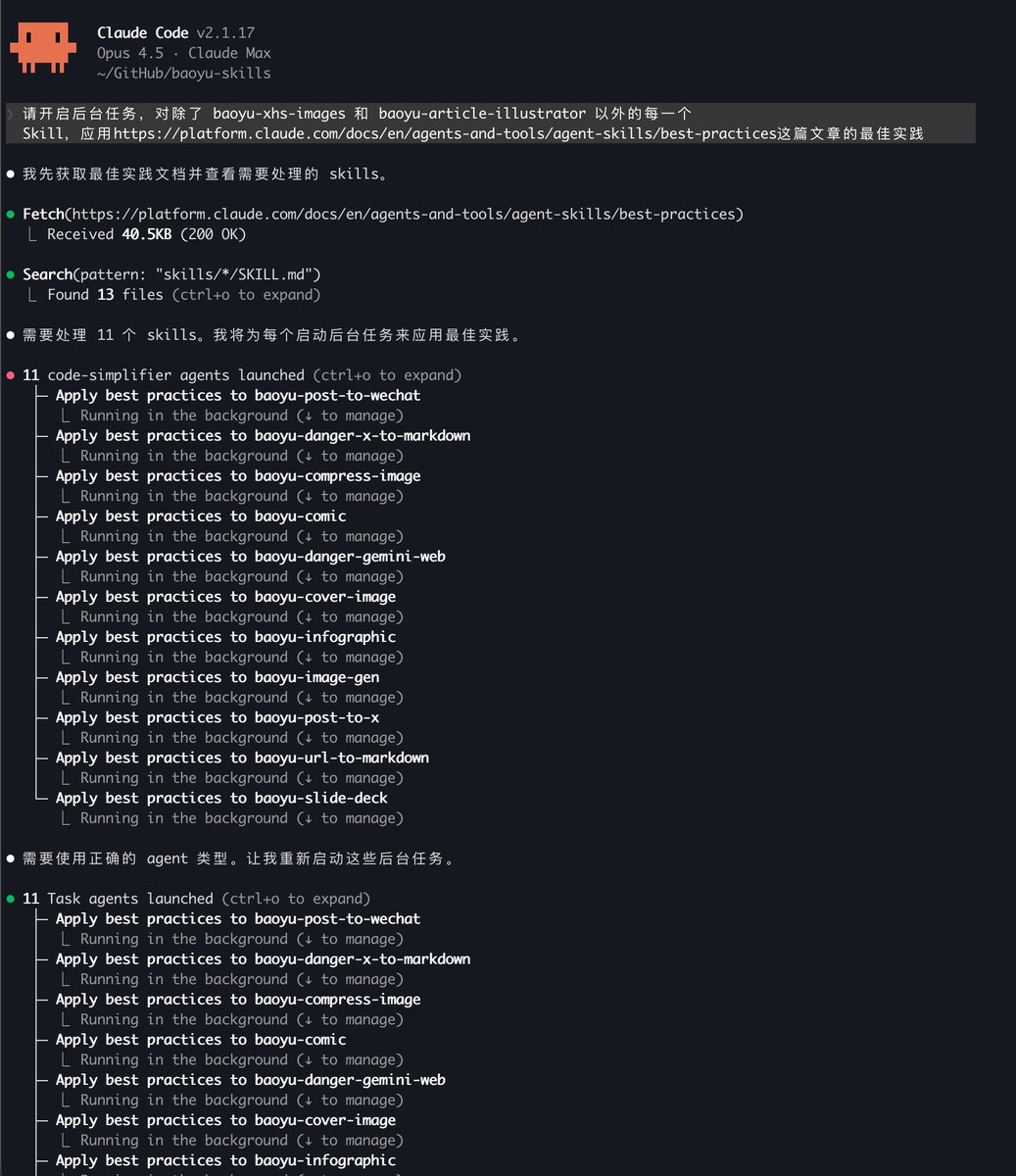
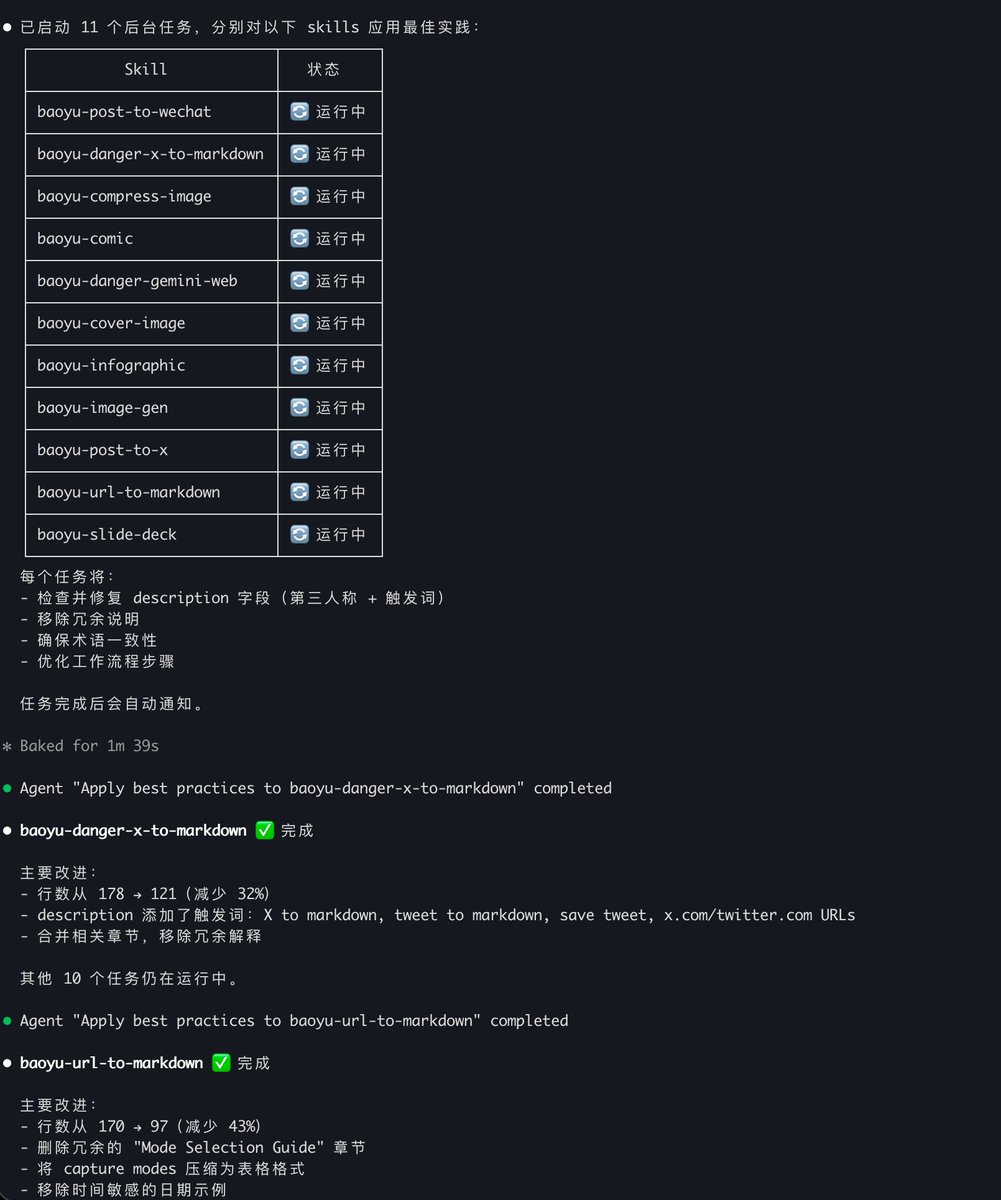
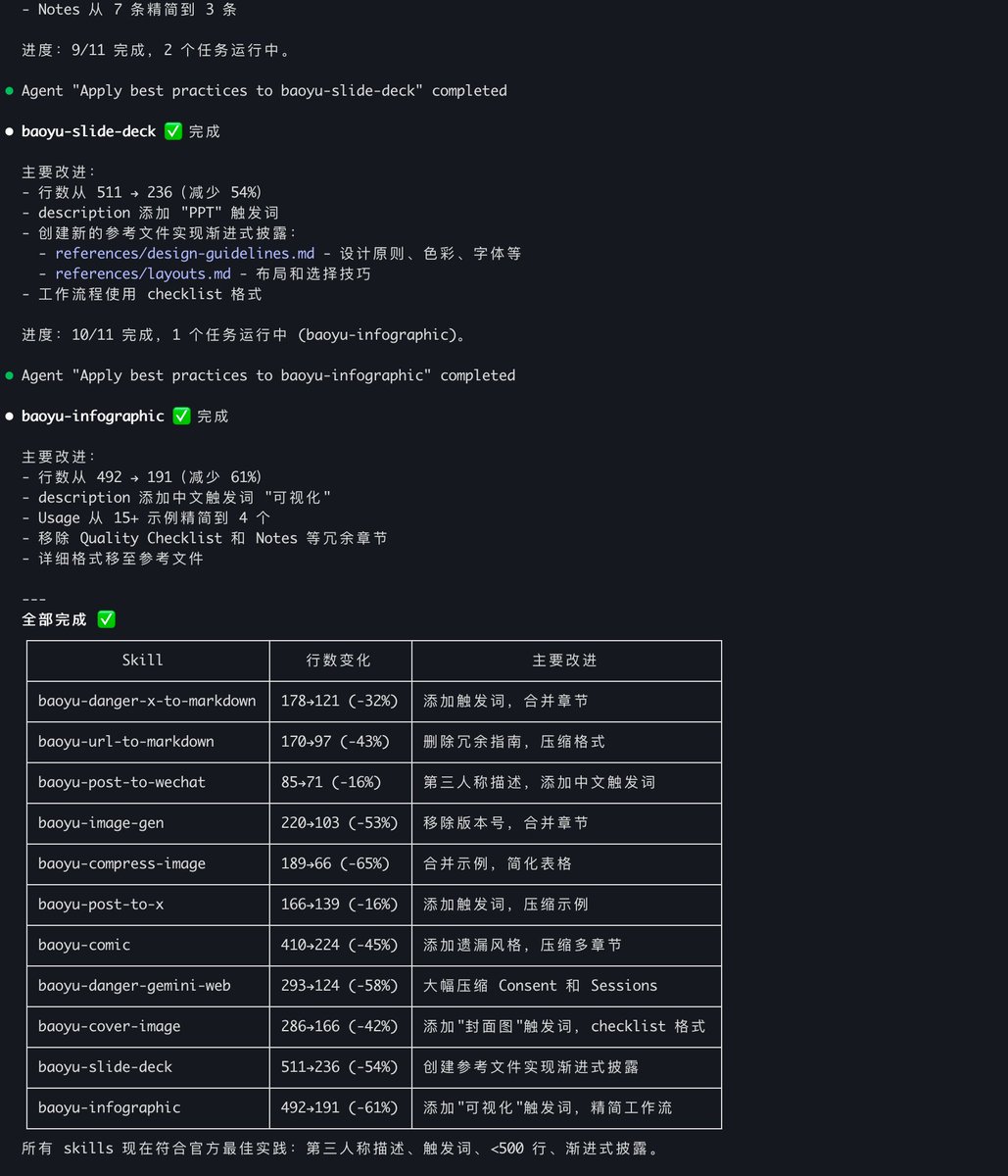
宝玉,想请问一下 Claude Code/Codex/其他的 AI,他们的 skills 你们是怎么管理的?是不是每一个 AI platform 都要装一遍 Skills?可不可以多个 AI platform 去共用一套 Skills?
宝玉@dotey
团队内的 skills 管理和维护的一点经验分享(以 codex cli 用的 .agents/skills 目录为例): 1. Git 管理是一定要的。 版本控制太重要了,而且 Skills 都是 Markdown 和脚本文件,天然适合 Git。 2. 用好 Symlink。 不要把 Skills 整个拷贝到 .agents/skills,而是通过 Symlink 直接链接到原始 Skills 的 Repo。 好处有两个:一是版本控制更干净;二是使用中遇到问题,Agent 定位后可以直接在 Repo 里改,改完就能 Review 提 PR。 我日常维护 baoyu-skills 就是这么干的,用的时候发现问题,让 Agent 在当前会话改,改的就是 Repo 本身,流程非常顺。 主要的坑是 Windows 下好像不支持 Symlink,另外首次配置稍麻烦(可以让 Agent 帮你操作)。 3. Skills 的编辑优先让 Agent 来。 改完走 Git 提 PR,这就是最好的协作和发布流程。 4. 验证确实不太好做。 脚本部分可以写单元测试,Skill 的 Markdown 部分只能靠平时积累的测试集,大部分还得人工。 但配合 Git 的版本管理,快速迭代反而更现实:不怕改出问题,出了问题根据 commit history 快速定位,或者直接回滚。 5. 最后提醒一下:大部分 Skills 应该跟着项目走(放项目目录下的 .agents/skills),不要放全局(~/.agents/skills)。 即使是渐进式加载,meta 信息累积起来也会占不小的上下文空间。
中文




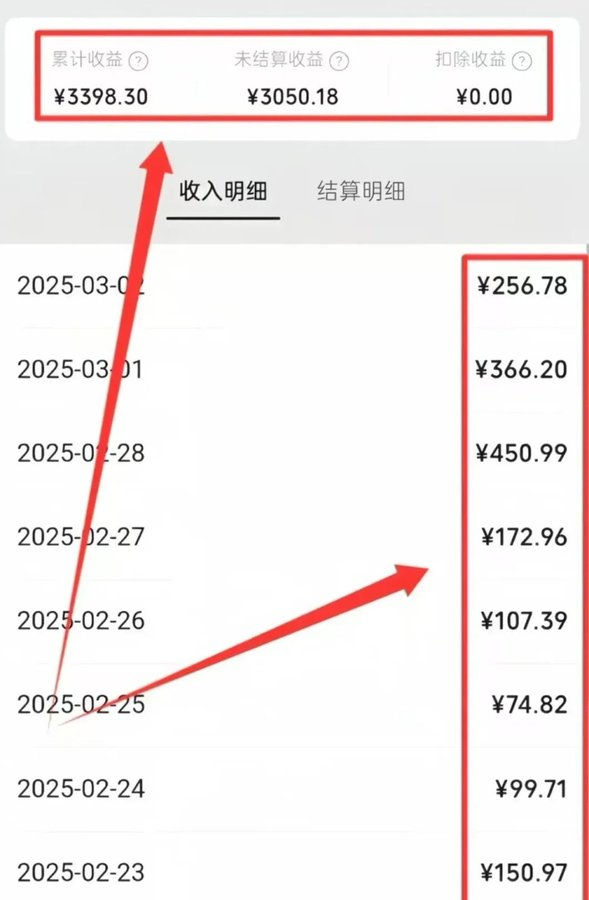

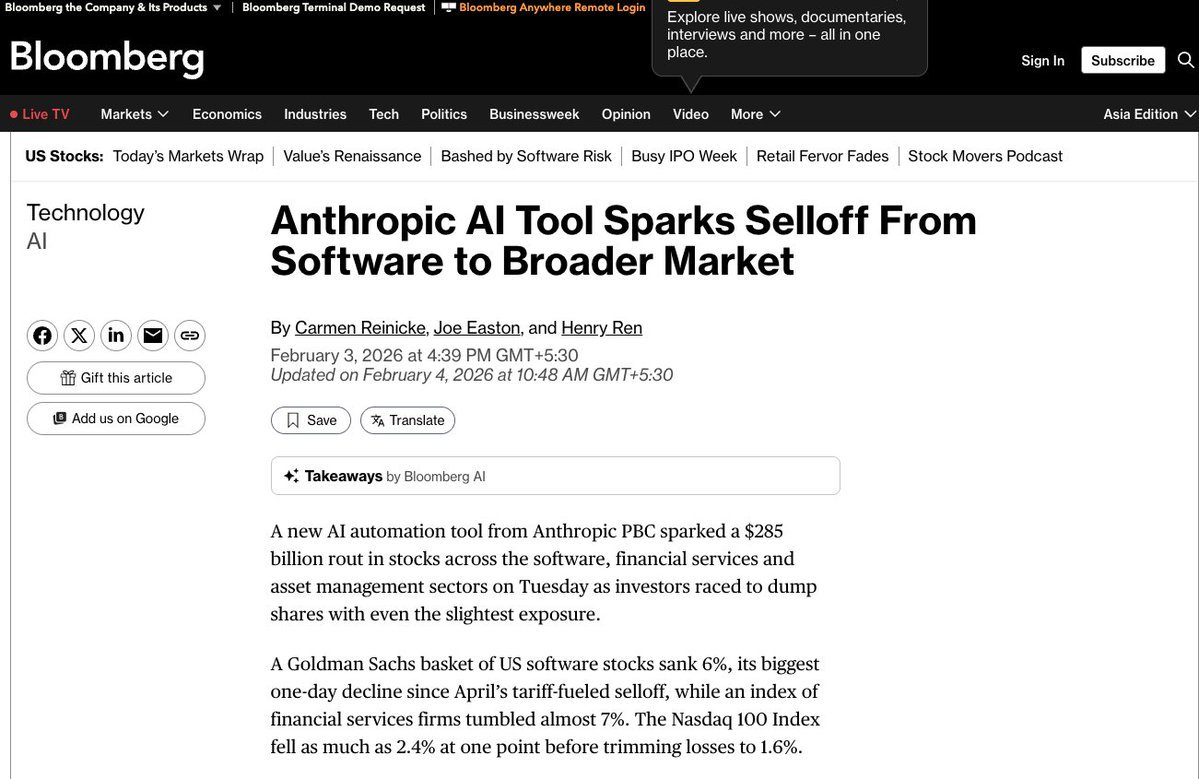
几小时内 2850 亿美元灰飞烟灭。 💸
Anthropic 发布了 11 个插件,纳斯达克就慌了。 为什么? 因为第一次,一家基础模型公司无视了 API 层,直接吞噬了应用层。
Anthropic 不仅仅是发布了插件。他们发布了“SaaS 杀手”。
• RELX (法律): -14% • Wolters Kluwer (税务): -13% • 高盛软件篮子: -6%
市场终于从可怕的数学中惊醒: 如果模型能直接干活,那软件就一文不值。
Anthropic 不再卖 AI 了。他们在卖整个员工。
中文