Sabitlenmiş Tweet

买了个域名 genaixue.com 跟AI学 目前重定向至 deepseek 向他们致敬。
以后谁问你问题不想回答了就扔给他这个域名,让他跟AI学
中文
handongxue
19K posts

@likev
after 80'/气象工作者/不苟同/关注天气变化/向往自由/热爱科学、互联网、编程 Node.js Web C++ Julia Python


听小珺 @zhang_benita 访谈谢赛宁 @sainingxie 的播客,太过瘾了。太多感触,说几个印象最深的点: 1. 世界模型远大于语言模型。我们每个人脑子里都有一个世界模型,比如知道把手放到火上烤会很痛,由此就不会把手放在火上烤。让你不会无缘由把手放在火上烤的模型,就是世界模型。 2. 世界模型是:Next state = M(state, action)。这个 M 就是世界模型。M 不是预测 next token,而是预测 next state. 比如:手很痛 = M(手不在火上, 把手放在火上)。世界模型的预测能力,可以让拥有世界模型能力的生命知道不做什么或做什么。 3. 从世界模型的视角再看大语言模型,就会发现语言的核心是沟通。沟通就意味着存在监督:说出来的,往往是加工过的。LLM 是毒药,Vision 才是无污染的。 4. Scaling law 是吞数据的能力。数据越多,效果越好。LLM 需要 Scaling law,可世界模型不一定需要。这是最有意思的部分,也是最难的部分。谢赛宁头大中,期待某种玄学的力量,突然某天能点连成线,灵光开悟。那样,就可以开始造生灵。 5. 用非机器人的方式,或许能真正解决机器人的困境。机器人领域,可能正在经历 LLM 领域曾经的 Bitter Lesson. 比如春晚的机器人炫技,或许只是曾经 CV 领域的识别猫猫狗狗。 6. 硅谷陷在 LLM 的述事里。硅谷之外的地方,对世界模型非常感兴趣。真正的智能,还在黑暗的探索期。语言很重要,然而整个宇宙的历史里,如果压缩到一天,有语言的时间,才几秒。 7. 人依旧很重要。比如 research taste、比如做研究实验时的 choices 等等。《金刚经》能提升人的独立思考性和研究品味。 8. Impact 不重要。奔着 impact 去做事,是一种自私。分享出来,让读者有启发,激发读者去做些事,这才是发 paper 的价值。 谢赛宁太可爱了。听完后,特别期待小珺下一期采访恺明。

🔍Follow Zhihu contributor toyama nao, a top large model reviewer, to evaluate @MiniMax_AI MiniMax-M2.7's capabilities in detail!✨ 📌 Basic Info: MiniMax iterates monthly in the Agent-driven model track. As a minor version upgrade, M2.7 carries its new understanding of the recent Agent boom. Its overall performance is on par with the previous generation, but key Agent capabilities are significantly upgraded. Despite tight computing power pressure ⚡, it maintains an average speed of 65 tps. ** Scores & ranking are shown in Fig 1 💪 What's improved 1️⃣ Instruction Following: M2.7 has obvious upgrades in direct/indirect instruction execution, but with reduced stability. It scores full marks in #59 long code derivation but may drop to "unusable" for medium-complexity tasks, leading to occasional misinterpretation or repeated programming corrections. 2️⃣ Context Hallucination: Significantly improved 🛡️, achieving perfect scores in typical information extraction tasks with only ±1 error in word counting. However, similar/duplicate context reduces accuracy (worse than Opus in long log analysis), but its worst performance is better than M2.5. 3️⃣ Coding Ability: No substantial upgrade in engineering design, but M2.7 more frequently writes SPEC.md/README.md to record project logic 📝, excelling in large-code/multi-round dialogue scenarios but struggling with difficult problems (needing retries or manual intervention). ⚠️ Shortcomings: • Complex Reasoning: Hard intelligence regresses slightly – no longer achieves perfect scores for previously solvable questions, with lower limits. It consumes 50%-100% more Tokens (excessive enumeration) and is more likely to hit MaxToken limits, increasing complex task costs 💰. 💬 In conclusion In the Agent boom era, "high-low model matching" is a consensus. MiniMax abandoned the super-model route early, focusing on M2 series' Agent/programming strengths. M2.5 widened the gap with Zhipu by riding the Claude alternative/OpenClaw wave, but competition is fierce – the next game-changer may be imminent 🌊. 🔗 Original Article: zhihu.com/question/20176… 📝 Benchmark: zhuanlan.zhihu.com/p/201117399166… #MiniMax #LLM #Agent #AI #Tech #Insight



added url support for: arxiv -> pdf github -> zip X long article -> markdown
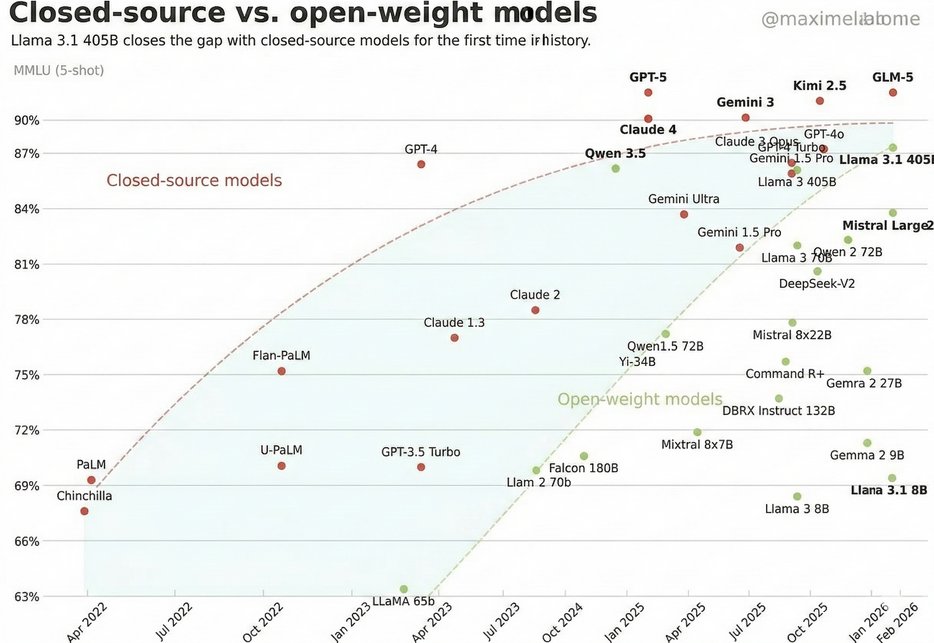


Due to popular demand, I've updated this figure to include DeepSeek-V2 and Mistral Large 2. It's also more zoomed for readability.
现在 Coding 就是,水多了加面,面多了加水。 Claude 不行换 Codex,Codex 不行就试试庸医 Gemini ,可能有奇效。

Omg.. GLM 5 beats sonnet 4.6 and 5.4 thinking on this trick question.