Sabitlenmiş Tweet

@_akhaliq Thank you very much for featuring our work!
We’re excited to share that it has just been accepted to NeurIPS 2025.
The code & model are now open-sourced here: github.com/microsoft/late…
The website for a quick summary of the work: zinanlin.me/blogs/latent_z…
AK@_akhaliq
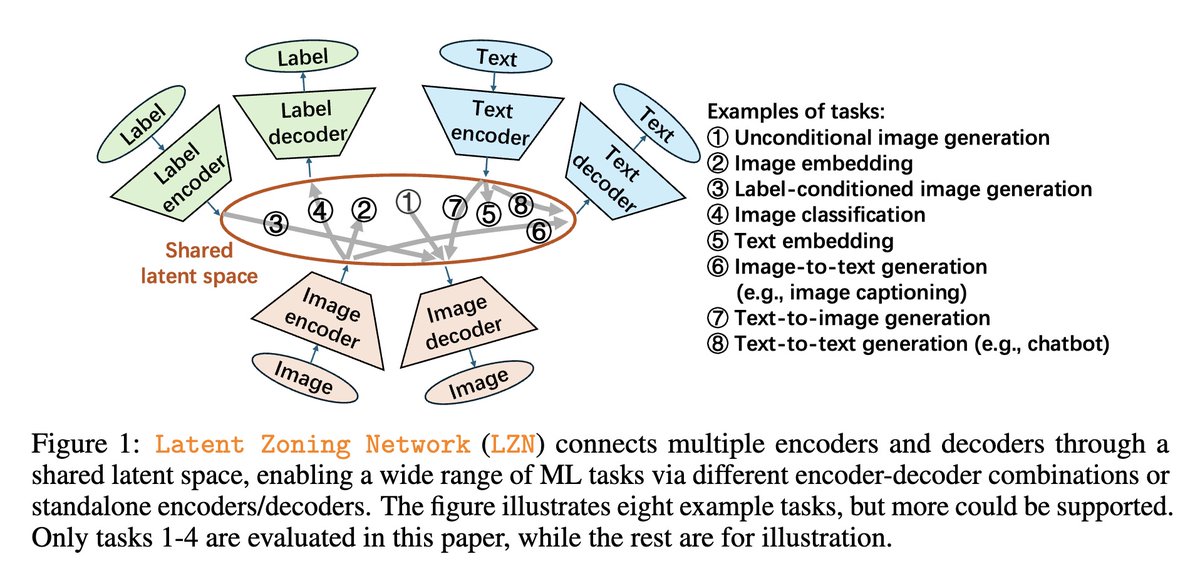
Latent Zoning Network A Unified Principle for Generative Modeling, Representation Learning, and Classification
English