
lingergnn
44 posts

lingergnn
@lingergnn41824
Ai infra dev。多年流浪于各互联网公司研发团队;做过搜索、数据抓取、数据挖掘、检索索引、AI模型训练优化、RDMA高性能网络通信...and so on...
Katılım Haziran 2025
1K Takip Edilen59 Takipçiler

阿里云 DNS 解析免费版限速了,开始要收过路费了
阿里云买的域名
我早早的将 DNS 在腾讯云 DNSPod 上解析
刚看了 腾讯云 DNSPod 其实早就收费了的
腾讯云专业版 99 元/每年
阿里云流量包的方式最低 150元/每年
👉 aliyun.com/notice/118259



中文
@QuanH76157 @gan158234 是什么这样的。鸡娃是社会普遍现象,而不仅仅是穷人专利,富人也一样可能方式不同。而且不要极端化,大部分鸡娃,没有那么bt和极端,都在比较正常范围和空间内。
中文


lingergnn retweetledi

多 Agent 系统炒了一年,生产环境里真正活下来的只有三种模式。剩下的都在坟墓里。
这个结论不是我的。它来自三份今天同时浮出水面的证据——一份是 Cognition(Devin 背后的公司)工程负责人的内部复盘,一份是 Manning 作者 Micheal Lanham 的行业全景报告,还有一份,是 GitHub 上一个叫 metaswarm 的项目。
我把它们放在一起看,发现一件很有意思的事:它们说的竟然是同一句话。
---
## 三个信号,同一个判断
**信号一:metaswarm——18 个 Agent,127 个 PR,一个周末**
今天 HN 上最火的项目。一个人 + 18 个 AI agent + 一个周末 = 127 个 PR 推到生产。MIT 开源。看起来是多 Agent 协作的终极案例。
但如果你仔细看它的架构,你会发现一个被刻意隐藏的细节:**它的 18 个 Agent 不是在对等协作。它是 map-reduce-and-manage。**
一个管理者拆任务,17 个子 Agent 各干各的,管理者收结果、合并、push。Agent 之间不互相聊天、不互相审查、不互相投票。每一个子 Agent 面对的是自己那一小块独立的上下文。
它看起来像 swarm,但其实是流水线。
**信号二:Walden Yan 的内部复盘——「写入保持单线程」**
Walden Yan 是 Cognition 的工程负责人。他 10 个月前写了一篇《不要构建多 Agent 系统》,今天又写了一篇《多 Agent:什么真的有效》。
核心结论原话:「多 Agent 系统在今天最有效时,写入保持单线程,额外的 Agent 贡献智能而不是行动。」
他们试了三种模式:
1. **代码审查循环**——编码 Agent 写,审查 Agent 读。审查 Agent 拥有**完全干净的上下文**,不看编码过程,只看 diff。平均每个 PR 能发现 2 个 bug,58% 是严重的。关键发现:两个 Agent **不共享上下文**效果反而更好。因为上下文衰减——编码 Agent 工作几小时后积累了巨大的上下文窗口,注意力已经稀释了。干净的审查 Agent 反而更聪明。
2. **智能朋友**——主模型遇到棘手问题,调用一个更强(也更贵)的模型作为「朋友」。关键难点不是推理能力,是**沟通**:弱模型怎么知道自己到极限了?该传给强模型什么上下文?强模型怎么回话才能让弱模型真正理解?
3. **管理者-子 Agent**——一个管理 Devin 拆任务,子 Devin 各干各的,管理者综合。遇到的问题全是**沟通问题**:管理者默认过度规定(因为它缺乏代码库上下文)、子 Agent 不主动报告该让兄弟姐妹知道的信息、Agent 之间默认不传消息。
三种模式,同一条规则:**写操作的 Agent 只有一个。**
**信号三:Micheal Lanham 的行业全景——「多 Agent 失败是结构性的,不是提示词问题」**
Lanham 是 Manning《AI Agents in Action》的作者。他今天的文章标题就说明了一切:《Multi-Agent in Production in 2026: What Actually Survived》。
他把多 Agent 系统分成三种拓扑:
- **Agent-flow(流水线)**:顺序传递。A 做完交给 B,B 做完交给 C。这是生产环境里**存活率最高**的形态。
- **Agent-orchestration(编排)**:一个管理者调度多个执行者。map-reduce-and-manage。最实用的复杂任务形态。
- **Agent-collaboration(对等协作)**:Agent 之间互相通信、协商、投票。**几乎全死了。**
他的原话:「大多数看起来像『更多 Agent = 更聪明』的东西,其实只是相同信息的冗余重排列。」
三份报告,三个作者,没有互相引用。但结论完全一致。
---
## 为什么「对等协作」全死了?
答案藏在两个技术细节里。
**第一个,Walden 说的「操作携带隐式决策」。**
当一个 Agent 写代码时,它在做选择——用什么设计模式、怎么处理边界情况、变量命名风格、错误处理策略。这些选择不是显式的,是「隐式」的。
两个 Agent 同时写,就会对同一个问题做出互相冲突的隐式决策。最后合并的时候不是 merge conflict,是**设计哲学冲突**。这种冲突没有 diff 工具能自动解决。
**第二个,Lanham 说的「级联表面」。**
对等协作的失败不是线性的,是指数级的。Agent A 的误差传给 Agent B,B 放大后传给 C,C 再放大传给 A。三个循环下来,输出和输入的语义距离已经大到不可恢复。
这解释了为什么 2024 年所有那些「Agent 团队自动开发 App」的演示都停在了 demo 阶段。
---
## 那活下来的三种模式长什么样?
**模式一:流水线(Agent-flow)**
最简单的形态。A → B → C,一个接一个。像工厂流水线。
适用场景:需求明确、步骤可分、输出可验证。比如:需求分析 Agent → 代码生成 Agent → 测试生成 Agent → 代码审查 Agent。
活下来的原因:每一步的输入和输出是明确的、可检查的。出问题能定位到具体环节。
**模式二:编排(Orchestration = map-reduce-and-manage)**
一个强 Agent 做规划 + 拆解 + 综合,多个弱 Agent 并行执行子任务。
适用场景:复杂任务需要并行加速,但决策权必须集中。比如 metaswarm 的 18 个 Agent,比如 Devin 的 manager-worker。
活下来的原因:写入操作只有管理者一个。子 Agent 贡献的是「智能」(分析、生成、搜索),不是「决策」。
**模式三:生成-验证(Generator-Validator)**
一个 Agent 写,另一个 Agent 读 + 挑刺。写的不看读的过程,读的不看写的过程。干净的上下文。
适用场景:代码审查、安全检查、内容审核。Walden 说他们在生产环境已经跑了很久。
活下来的原因:验证 Agent 的上下文是干净的。没有历史包袱,不会被编码 Agent 的错误假设带偏。
---
## 一个反直觉的结论
看了这三份报告,我最大的感受不是「多 Agent 不行」,而是一个更微妙的东西——
**多 Agent 系统真正解决的问题不是「更聪明」,是「更便宜 + 更可靠」。**
用同样的钱,跑 5 个便宜模型的并行流水线,比跑 1 个贵模型做全流程,出活质量更稳定、容错率更高、速度更快。
这不是 AGI 的突破。这是系统设计的胜利。
Walden 在文章最后说的:「我们正在构建一个世界,智能被注入软件开发生命周期的每一个阶段——不是作为一群自主行动者,而是作为一个协调的系统,扩展人类的品味。」
注意这个词:「协调的系统」,不是「自主的行动者」。
---
## 所以,别再造 Agent Swarm 了
如果你现在准备做一个多 Agent 项目,问自己三个问题:
1. **写入操作能不能只有一个人?** 如果能,继续。如果不能,单 Agent 可能更好。
2. **Agent 之间传什么上下文?传多少?** 这不是提示词问题,这是架构问题。传多了淹没接收者,传少了接收者无法做正确决策。
3. **失败会怎么级联?** 如果 Agent A 错了,Agent B、C、D 会跟着错到什么程度?有没有断路器?
如果你对这三个问题没有清晰的答案,你就还没有准备好上生产。
多 Agent 的未来是真实的。但不是你想的那种未来。
不是一群 Agent 在聊天室里讨论怎么做。是一个指挥,多个执行者。是一种结构设计,不是魔法。
---
**参考来源:**
- Walden Yan (Cognition): [Multi-Agents: What's Actually Working](x.com/walden_yan/sta…)
- Micheal Lanham: [Multi-Agent in Production in 2026: What Actually Survived](@Micheal-Lanham/multi-agent-in-production-in-2026-what-actually-survived-f86de8bb1cd1" target="_blank" rel="nofollow noopener">medium.com/@Micheal-Lanha…)
- metaswarm: [18 AI agents, 127 PRs to prod in a weekend](news.ycombinator.com/item?id=468649…)
- Anthropic: [anthropics/skills](github.com/anthropics/ski…) ⭐
中文



ChatGPT Pro 很划算!因为 GPT-5.5 API 比 DeepSeek v4 Pro 贵39倍,比 DeepSeek v4 Flash 贵98倍。
- Fresh input: $5 / 1M
- Cache read: $0.50 / 1M
- Output: $30 / 1M
- Reasoning: treated like output → $30 / 1M
过去24小时 Codex 花费(如果用 API):
- Fresh input: 24.36M × $5/M ≈ $121.80
- Cache read: 881.61M × $0.50/M ≈ $440.81
- Output: 3.57M × $30/M ≈ $106.96
- Reasoning: about 1.21M × $30/M ≈ $36.17
Total ≈ $705.73
Codex 的缓存命中不输 DeepSeek,超过97%!
AskClaw 🦀@GetAskClaw
hermes 切换模型失败,一直在用 deepseek-v4-flash deepseek-v4-flash 作为 orchestrator 负责 /goal hermes deepseek-v4-flash 将 /goal 任务 分解后操控 codex gpt-5.5 xhigh /fast 持续编码,消耗了 chatgpt pro 超过60% weekly limit,生成了超过10万行代码
中文
@taozi0929 @fenseanna 是你在扩大,人家就是早说交通秩序,行就行,差就是差。你非要强调好一面坏一面的,故意把水搅浑。
中文



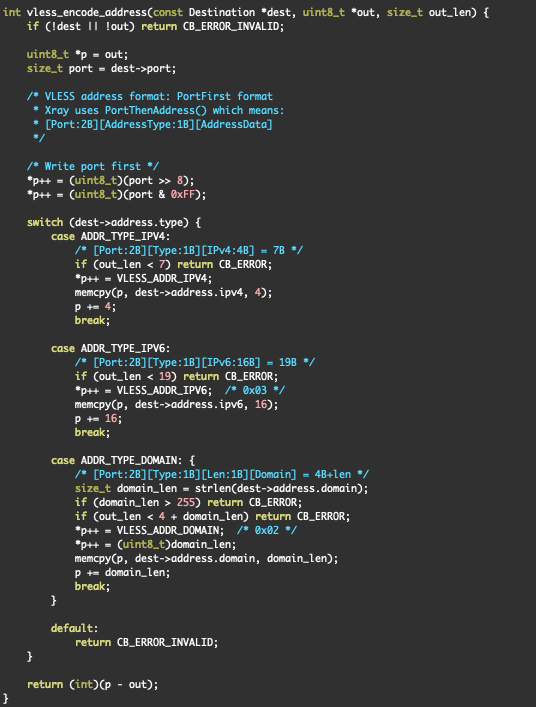
@fanleiLex 有相对稳的翻墙方案,代价略高看你抉择:买腾讯云hk轻量vps+优选流量包。就有了一条大厂国内到hk高质量线路,hk地区买个国际互联好廉价vps作为真正出口。让腾讯云hk通过配置iptables转发廉价出口vps。国内客户端--优选线路-->腾讯云hk-->落地机vps-->国际。这就是我的自建方案。
中文




@BelieveInChina @Kongkongda5882 删除不干净的。要想彻底删除干净就得卸载+重装APP。我删除+重装好几次了。就算把聊天记录全部删除,依然很大。只有删除app,才能彻底清理。
中文

@lingergnn41824 @Kongkongda5882 微信的记录不舍得删还怪微信。我拿telegram看片都占200多G了我都没说话。我自己都看了啥我自己清楚,我就不抱怨telegram了。
中文

@demonyins 没用过这家 我感觉目前东京线路性价比最高的是rfchost 的 jp co,我这边用起来很爽。浙江电信到他延迟39ms的样子。
中文

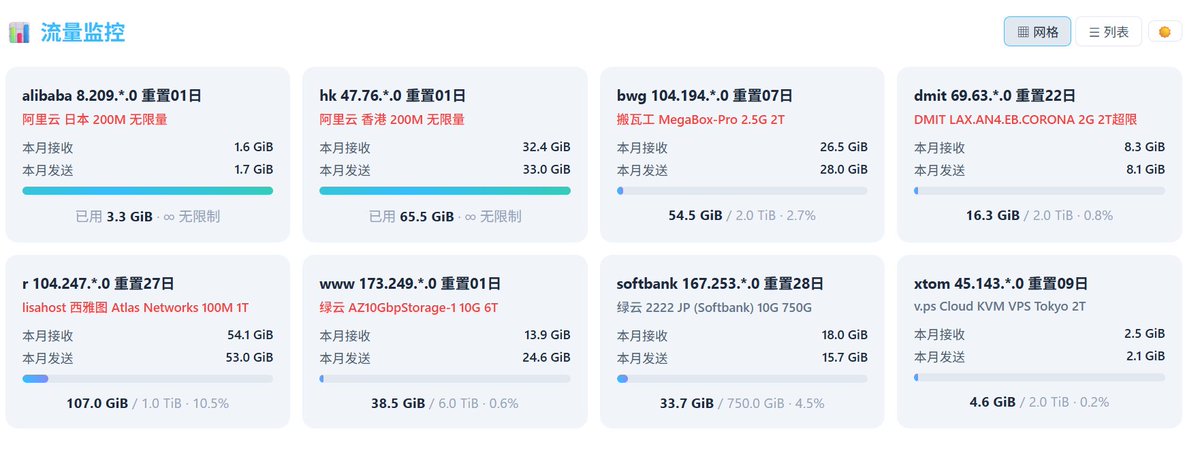


我在数学推理这块一直很强
列举一下:
小学没有任何培养背景,秒解24点
全班只能我一人能解
数学老师觉得我有天赋,
可惜家里穷,父母初中毕业没文化
没有培养
初中整天玩
依然考上山东省前十的重点高中
高中被高考650+的同学评价我比他聪明很多
这个分段的人都是很自傲的,很难赞赏别人
大学挂科无数,整天打游戏,放飞自我
挂过高数、线代、复变、c语言等等十几门
结果临近毕业找实习
跨专业转吗,刷了一周的算法题拿到百度实习
实习四个月拿到腾讯等数家大厂的校招offer
当时c++完全不会,鹅厂四年T10年薪百万
作为导师,带过清华、斯坦福、伯克利的毕业生
总结就2点:
1.勤奋努力
2.我脑子的确好使
中文
