
Nilay
317 posts

Nilay
@localm_tuts
AI Researcher | 2x Native AI Startups | Follow for tutorials, podcasts, and hacks to keep your skills sharp. For Hindi follow @localm_hi
London | San Jose Katılım Aralık 2025
25 Takip Edilen15 Takipçiler




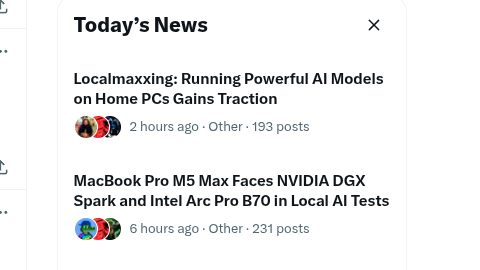
We made it to my "Today's News" @xyster @MemoryReboot_ 🤣🤣
Looks like we need to do more testing!
English
@mr_r0b0t @Tono_Ken3 Yes, I assume for the size of minimax and supporting reasonable context for multiturn (with a 20% token increase turn by turn to support up to 4-6 turns with 64K context), you are looking at 396GB VRAM for 4-6 parallel streams.
English

Imagine this
8x RTX Pro 2000s with 128GB of VRAM have aggregate throughput greater than 2x GB10s...
MiniMax 3.0 is about to be released.
mr-r0b0t@mr_r0b0t
16 local AI agents streaming at once! MiniMax M2.7 NVFP4 — 2x GB10, no cloud APIs.
English
Are you considering a @NVIDIAAI DGX Spark or GB10? Looking for tips and best practices for the one you have? Want to show off your new projects?
Join the newly formed DGX (GB10) User Group!
I'll be there and happy to help as best I'm able ♥️
x.com/i/chat/group_j…
English
@SpaceTimeViking @NVIDIAAI I think next round of NEMOs on way ;) that's my best hunch.
English

@NVIDIAAI is cooking up something “Ultra” and this could be their big break. The post training model has so much potential distilling the weights and data down to the purest form possible.
Isolating the signal and removing the noise.
Scaling that up could be a big deal.
NVIDIA AI@NVIDIAAI
@TheAhmadOsman 👀 "Ultra" ⏳️
English
@thegenioo if you have one - great, if you haven't that's not blockers. key is multiturn accuracy. one can have image agent.
English

The moment DeepSeek gets vision
You absolutely don’t need any other chinese model if you need reliability, performance, cost effectiveness and speed
DeepSeek@deepseek_ai
We are making our discount permanent! 🎉 Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀
English
FYI. this is experimental for dgx sparks only - optimised with modelopt from BF16 image, and post quant-optimised. I haven't benchmark to validate loss (but my hunch is it is lossless) - as NVFP4 was < 0.02
it use llamacpp's nvfp4 underlaying...
huggingface.co/nilayparikh/Qw…
English
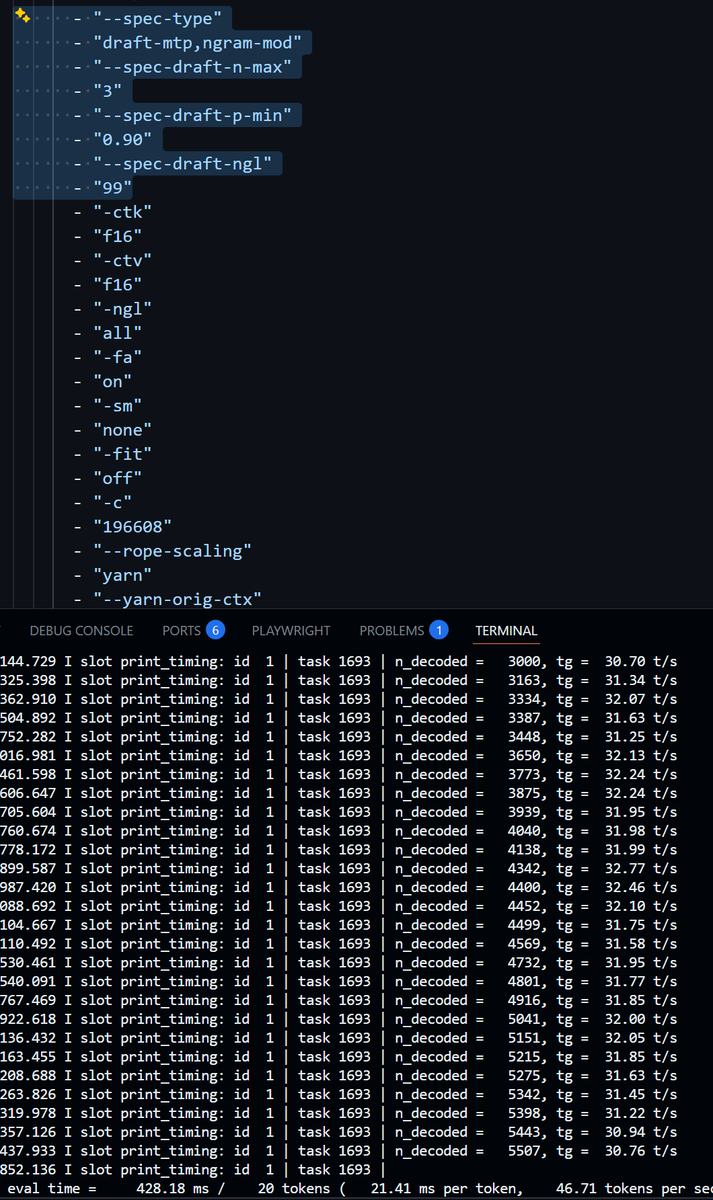








I am token rich!
I have ratio of 700:1 (input to output) ratio for input to output.

DeepSeek@deepseek_ai
We are making our discount permanent! 🎉 Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀
English

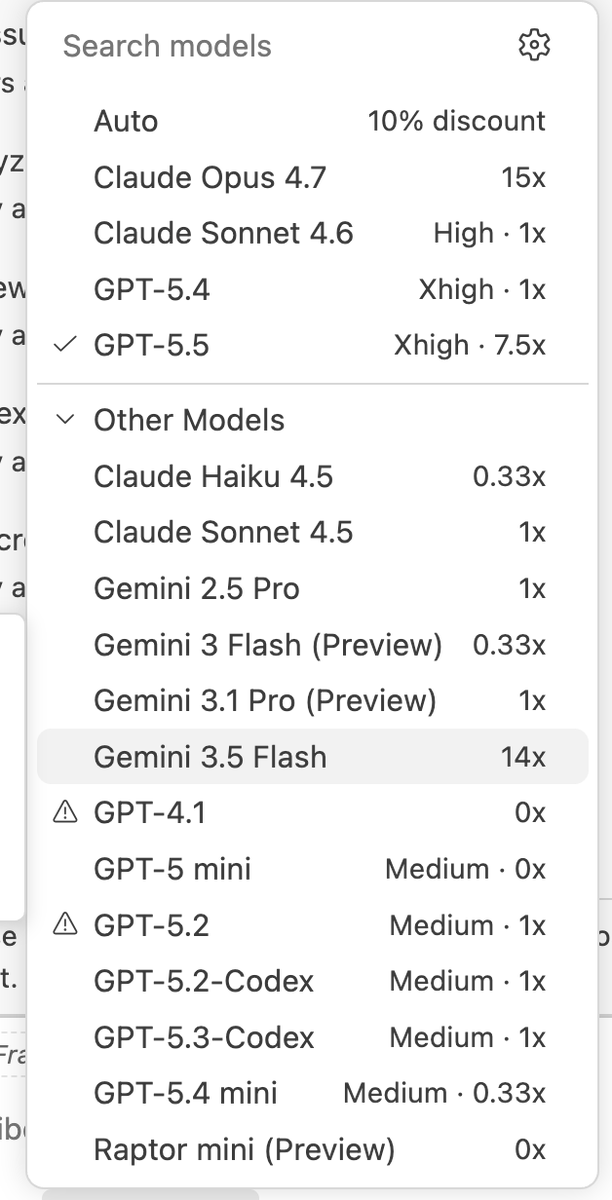
Gemini 3.5 Flash in GitHub Copilot has 14x multiplier basically on par with Claude Opus 4.7 🤡
English
I am without OPUS since 29 days
I am without GPT 5.5 since 29 days
I am without GPT 5.4 since a week
And I survived - so can you!
API (NVIDIA++) + Local 👏
DeepSeek@deepseek_ai
We are making our discount permanent! 🎉 Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀
English