
Juan Mugica
154 posts

Juan Mugica
@loonstep
I build, therefore I am. Previously at Google and MIT, now figuring out creating a company. You’ll find me running, coding, training, selling, cooking.
Madrid | NYC Katılım Eylül 2024
288 Takip Edilen62 Takipçiler

@matiii If you're up for it, happy to do an @exp8fellowship fireside for the 100 best young engineers in Madrid! 🔥
Can find a cool spot!
English

I’ll be in Madrid, Warsaw, and Paris over the next two weeks. If you’re nearby and want to help us double down on Europe and build locally across the region, let me know - would love to meet!
English
Juan Mugica retweetledi



Juan Mugica retweetledi

We hosted our first @openclaw event two weeks ago at mad.builders
This week, @loonstep, @TomasStambulsky, @metasurfero and myself will be showing our our actual AI setups
Seats are limited.
Come join us. Link below 👇

English


The issue with going out is that you have to stop vibe coding for a few hours
English
Juan Mugica retweetledi

Juan Mugica retweetledi
hosting zero to agent in Madrid on 24/4 global build week. ship a real agent with @v0 + @vercel. free, $6k+ prizes. Link below #ZerotoAgent

English
Juan Mugica retweetledi

Juan Mugica retweetledi

LeWorldModel: Yann LeCuns Radical Simplification of World Models Just Made Physics-Aware AI Practical
In the race for artificial general intelligence, two paths have emerged. One is the familiar scale everything route: bigger LLMs trained on ever-larger text corpora. The other, championed for years by Yann LeCun, is building world models: compact systems that learn the underlying physics of reality directly from raw sensory data (pixels) so AI can plan, predict, and act in the physical world like a robot or self-driving car actually would.
Until now, the second path has been frustratingly difficult. Joint-Embedding Predictive Architectures (JEPAs) - LeCuns elegant framework for learning predictive representations without reconstructing every pixel - kept collapsing during training. Researchers had to resort to a laundry list of hacks: multi-term loss functions (up to six hyperparameters), frozen pre-trained encoders, stop-gradients, exponential moving averages, and other duct-tape tricks just to keep the model from mapping every input to the same useless output.
LeCuns team (Mila, NYU, Samsung SAIL, and Brown University) dropped a bombshell:
LeWorldModel (LeWM) - the first JEPA that trains stably end-to-end from raw pixels using only two loss terms. No more house-of-cards engineering. Just a clean, simple recipe that works on a single GPU in a few hours with only 15 million parameters.
The Core Breakthrough: SIGReg Saves the Day
LeWorldModels secret weapon is a new regularizer called SIGReg (for spherical isotropic Gaussian regularizer). It enforces a simple Gaussian distribution on the latent embeddings.
This single term prevents representation collapse without any of the previous heuristics.
The training objective now has just two parts:
1. Next-embedding prediction loss - the model predicts what the next latent state should be.
2. SIGReg - keeps the latent space well-behaved and diverse.
Thats it. Hyperparameters drop from six to one. Training becomes stable, reproducible, and dramatically cheaper.
The model learns directly from raw video frames (no pre-trained vision encoders needed) and produces a compact latent world model that can be used for fast planning.
Impressive Results on Real Benchmarks
Despite its tiny size, LeWorldModel punches way above its weight:
- Trains on a single GPU in a few hours.
- Plans actions up to 48 times faster than foundation-model-based world models.
- Uses roughly 200 times fewer tokens than alternatives.
- Matches or beats far larger models on diverse 2D and 3D control tasks (e.g., manipulation, navigation).
- Its latent space encodes meaningful physical quantities (position, velocity, etc.) - proven by direct probing.
- It reliably detects physically implausible surprise events, showing genuine causal understanding.
Crucially, adding a decoder and reconstruction loss hurts performance on downstream control tasks. The pure JEPA objective already captures everything needed for planning - extra visual details just get in the way.
Project website: le-wm.github.io
Official code: github.com/lucas-maes/le-…
Why This Matters for the Future of AI
LeCun has been saying since 2022 that world models (not next-token predictors) are the key to real intelligence. Critics always pointed to the training instability. LeWorldModel removes that objection with elegant simplicity.
This is a philosophical reset: AI can learn physics the way babies do - by watching the world unfold - without needing supercomputers or endless text.
The implications for robotics, autonomous vehicles, and embodied agents are enormous. Suddenly, building a physically grounded planner is something a researcher (or even a hobbyist) can do on consumer hardware.
1 of 2

English
Juan Mugica retweetledi

Juan Mugica retweetledi

Si hiciéramos esto en Madrid, en 10 años sería un powerhouse espectacular.
Pablo Wende@PabloWende
Primicia: la ciudad de Buenos Aires tendrá su distrito de IA. Las empresas que se instalen allí no pagarán Ingresos Brutos y podrán realizar pruebas (por ejemplo autos autónomos). Se suma al distrito tecnológico y al audiovisual. Se anuncia en breve
Español
Juan Mugica retweetledi

Juan Mugica retweetledi

Juan Mugica retweetledi

Meet the new Stitch, your vibe design partner.
Here are 5 major upgrades to help you create, iterate and collaborate:
🎨 AI-Native Canvas
🧠 Smarter Design Agent
🎙️ Voice
⚡️ Instant Prototypes
📐 Design Systems and DESIGN.md
Rolling out now. Details and product walkthrough video in 🧵
English
Juan Mugica retweetledi


El voice mode de Claude Code todavía no funciona en español.
Por eso me voy a ChatGPT, utilizo el dictar, copio y pego otra vez en CC. 😅
Español
Juan Mugica retweetledi

Introducing the Google Workspace CLI: github.com/googleworkspac… - built for humans and agents.
Google Drive, Gmail, Calendar, and every Workspace API. 40+ agent skills included.
English
Juan Mugica retweetledi

1/ The stack is inverting
A year ago or so @satyanadella was already talking about this shift.
Before LLMs, you had a human interact with the UI of an app, which ran business logic, which ran on top of a database.
But today, as @naval coined recently, “AI is eating UX.” A new surface area of interaction is emerging: agents. A human-like presence in a box that reads context, chooses actions, and calls tools for us (what LLMs enabled).
Which raised questions about where power is shifting, and why we’re seeing big tech splashing cash and new startups popping up everywhere to surf this wave - because there is a platform shift (and therefore, opportunity).
In this context, and as we know from our friends Benjamin Graham’s Mr. Market definition (irrational, often contradictory) and John Maynard Keyne’s “animal spirits”, the stock market got fearful. All of a sudden.
Here’s my best attempt at representing Satya’s framework for going from SaaS → Agents, which has been helpful to keep in mind lately:
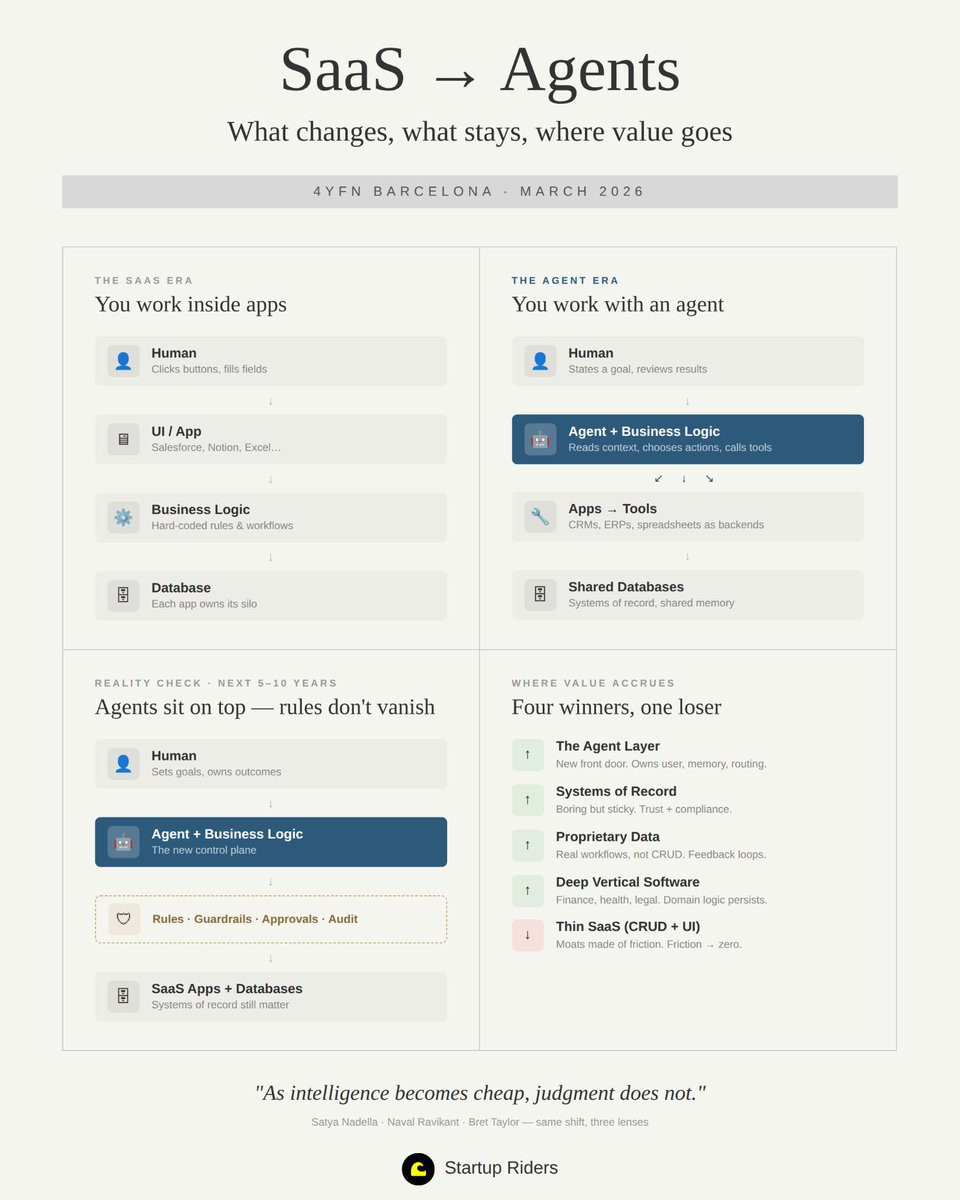
English
Juan Mugica retweetledi

Announcing a new Claude Code feature: Remote Control. It's rolling out now to Max users in research preview. Try it with /remote-control
Start local sessions from the terminal, then continue them from your phone. Take a walk, see the sun, walk your dog without losing your flow.
English
Juan Mugica retweetledi

Claude Sonnet 4.6 scores 100%, with a median TTFT of 850ms, on our standard LLM Voice Agent performance benchmark.
It's currently the fastest model that saturates this benchmark.
I also re-ran the numbers for the whole leaderboard, and Claude Haiku 4.5 scored 98% with a TTFT of 637ms. This puts Haiku in front of GPT 5.1 in the rankings, and a bit better in "intelligence" than GPT 4.1, but 100ms slower.
This is the first time we've had an Anthropic model that's a really good fit for most of our voice agent use cases. And now we have two!
Claude models have always had great instruction following, tool calling, and conversational dynamics. But they've been slower than the other SOTA models. That's changed.
One reason to re-run a benchmark like this is that latency changes. We continuously monitor latency for all the models we regularly use. But a specific run of a long-format benchmark like this is a bit different than our standard monitoring.
Another reason, though, is that models like Claude, Gemini, and the GPT family are hosted systems and they evolve. A good rule of thumb is that changes in model behavior are probably your own code rather than real changes on the provider side. But that's not always true. And this performance jump for Claude Haiku 4.5 over the past two months is dramatic.
I recently fixed some corner cases in tool call handling and improved the judging prompts in this benchmark. So I'll re-run Claude Haiku 4.5 against the benchmark code from 2 months ago, at some point, because I'd like to understand whether I previously had bugs that unfairly penalized Haiku. But either way, whether the model has gotten better or we've ironed out some issues with the benchmark, Haiku is impressive and is worth experimenting with if you are a voice AI developer.

English