
myprototypewhat
74 posts

myprototypewhat
@m13t_dev
Frontend Developer / Building AI products & agent tools / Focus on workflows that actually work
Katılım Şubat 2026
17 Takip Edilen30 Takipçiler

提到 web 的流畅,我讲点东西,和 flutter 没关系,和 react 有关系。
早期显示器基本都 60Hz。
所以浏览器提供了一个 API 叫 requestAnimationFrame,跟随屏幕刷新节奏。
所以这就是很多人都知道的 60帧那个事,如果 16.6ms 里没跑完,就会掉帧。
也就是 React 那个知名的发现时间快用完了就先暂停,把主线程还给浏览器,让它去画画,处理用户事件的行为。
今天的高刷显示器变多了,120Hz,144Hz,还有 240 和 360 的显示器(虽然我觉得意义不大了),意味着单个时间切片也变短了。
但 React 并没有继续跟随说把 16.6ms 继续切短,做更多调度,比如算成 8.3ms。而是改成了默认切片时间就是 5ms。
理由是这样的:
5ms 对于 60Hz,在一帧 16.6ms 里可以跑最多 3 个 5ms 的切片。
如果是 120Hz 的 8.3ms,跑 5ms 还有3.3ms 多余的时间,浏览器可以从容地去完成各种绘画和操作。
如果是 240Hz,4.1ms,5ms 稍微超时了一点点,但这时候人眼已经感知不出来了,所以也无所谓。
除非你是个电竞选手。
5ms 是个很好的 sweet spot。
这个细节可以自己去搜索下,官方有提过,也有不少文章讲过。如果你现在打开 #L16" target="_blank" rel="nofollow noopener">github.com/facebook/react… 也可以看到第 16 行的引入,指向了一个 5ms的 flag。
只不过很早以前在 scheduler 里好像是写死的,现在要处理的不只是浏览器,在不同环境编译时,可以更容易的调整这个参数。
——————
上面一大通其实和原 po 说的 flutter 没什么关系,只是今天正好复习到这里,看源码有一些东西发生了变化,就正好巩固下。
web 仍然有很多不如 native 丝滑的地方,w3c 的保守策略,历史欠债等,但一直有无数人在为了它的性能和表现在努力。
有很多地方确实不适合 web 方案,选 native 更合适。但我高度怀疑——可能有的开发者根本就不知道怎么用好 web 方案。
——————
我不是专业的前端开发,可能有不准或错误的地方,那就请大佬们指正。
akazwz@akazwz_
我用 flutter 写了一个简单的 web 应用,体验和原生一样,太强了,那种流畅感,和原生应用没有区别。
中文

受不了 TUI 了!!!
朋友们有没有直接基于 Claude code 本地 CLI 的 套壳 GUI 产品
不要是接 Anthropic 格式 API 的那种
中文

AI 自媒体圈太没非共识了
之前非常笃定 md 就是最好的格式
同时 for agents 就是未来
现在突然宣称 html 也是最好的
理由是 html 更适合阅读和交互
开始 for human 了
会不会往后发展
突然发现
SaaS 比 html 更适合表达
同时发现
数据库比 md 更适合存储
然后最终发现
SaaS 和 App 的春天又来了
中文
@elliotchen100 感觉多少沾点伪需求
1. md中也可以套html
2. 需要看产出的东西受众和方向是哪些,给ai看md适合,给人看html适合。如果是文本导向的,md一看能看出来结构,html有些费劲。
3. 他大概就没考虑过token的消耗(哈哈哈哈哈
中文

Anthropic 的 Thariq 昨天那篇 HTML 的文章爆了,1.5M 阅读。
看上去在讲格式审美,其实他在讲一套全新的工作流。
挑几个最有技术含量的点。
第一,HTML 不是文档,是 throwaway editor。
他举的例子很经典。30 个 Linear ticket 要重排优先级,让 Claude 生成一个 HTML,每个 ticket 做成可拖拽卡片,分 Now / Next / Later / Cut 四列。结尾加一个「copy as markdown」按钮,把最终顺序导出来贴回 Claude Code。
这个模式可以套到所有「用文字很难描述」的场景。调动画缓动曲线,调颜色,调 cron,调 regex,全都比纯文本表达高效一个量级。
第二,用 HTML 网做 spec,不再用单个 Markdown plan。
他的流程是:先让 Claude 生成 6 个不同方向的方案,平铺在一个 HTML 里横向对比。挑一个深入做 mockup 和数据流图。最后写实施计划。开新 session 的时候把整个 HTML 网络当 context 喂回去。
verification agent 也读这堆 HTML。这意味着 spec 不再是给人看的过渡产物,而是 multi agent 协作的共享内存。
第三,SVG 是被严重低估的输出格式。
让 Claude 把 token bucket 限流逻辑画成 SVG 流程图,关键代码片段做内联注释,加一个 gotchas 段落。一张图比 200 行 Markdown 解释清楚一个数量级。
第四,他诚实承认了代价。
HTML 比 Markdown 生成慢 2 到 4 倍,diff 也更难 review。但是在 Opus 4.7 的 1MM context window 下,多出来的 token 在 context 里几乎不可见。这是他做出取舍的关键。
讲到底就一句话:
Markdown 的隐含假设是「人会从头读到尾」。HTML 的隐含假设是「人只想扫重点和动手改」。
后者才符合 AI 时代人和机器协作的真实形态。
Thariq@trq212
中文



活久见系列,有人贴心的帮 CC Switch 做了一个官方网站,并且链接到我的 GitHub 仓库,但是你这个定价是几个意思?在此声明一下,CC Switch 目前没有官方网站,唯一的下载地址是 GitHub,并且开源免费,凡是收费的都是盗版,谢谢大家!
中文



我其实最近vibe coding发现很多问题
我一开始其实对我想写的项目是没有非常清晰概念的。
所以导致后期发现AI给我的中间层非常的臃肿
我可以理解这些问题的原因
但是等我想明白,
回头重新解决的时候
修复的难度实际上已经高于自己重写了
自己重写就会引起新问题
于是陷入困境
软件工程永远都是一个复杂的系统工程这句话的含金量还在升高
中文

插进middleware 数组,不改业务代码。
历史压缩用便宜模型把旧对话炼成结构化摘要,不是粗暴截断。工具输出过大时自动截断保留头尾,完整内容存 VFS 按需取回。 当然core包也可以单独使用更加灵活。
@TanStackDev
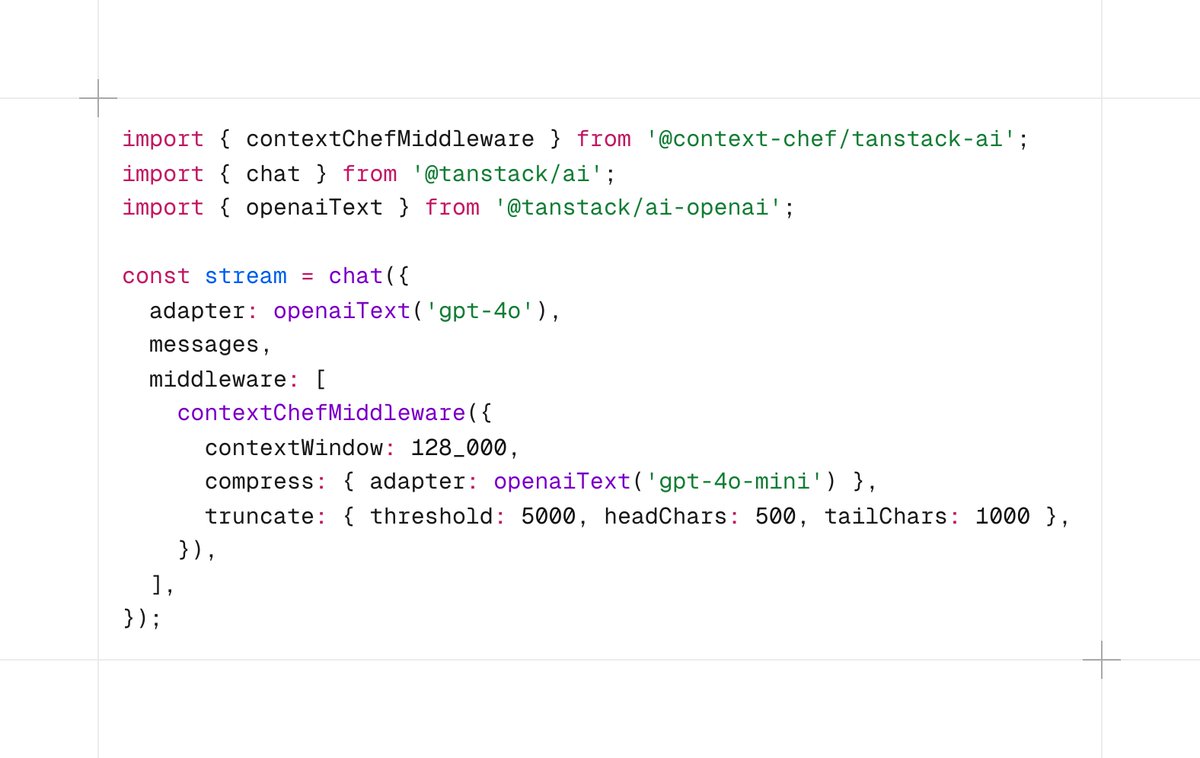
中文
做了个 TanStack AI 的 middleware — context-chef
一行接入,自动:
- 压缩对话历史
- 截断过大的工具输出
- 注入动态状态
- 多provider统一编译 👇
中文

前两天我发了篇推文说Meta是AI界最遗憾的公司,今天就刷大前Meta LLaMA团队的Peter Pang发的这篇3500字长文,是我今年看到的最有实战价值的AI-first落地报告。
它把所有喊了半年的AI-first空话,变成了可复制的步骤和可验证的数据。
现在所有人都在说AI辅助开发,说Copilot能提效20%,Pang认为这根本不是AI的正确用法。
在旧流程上叠AI工具,最多只能带来10-20%的效率提升,结构一点没变,
真正的AI-first,是先假设AI才是主要的代码构建者,然后把整个工程架构、CI/CD、测试流程、甚至组织分工,全部推倒重来。
最反直觉的一点来了:
当大多数人都以为AI-first的瓶颈是模型不够强,是工程师不会用工具,
他用真实数据告诉我们 AI写代码的速度从来不是瓶颈。
上下游的人工流程,才是卡死所有效率的死穴:
• PM写一份详细需求要两周,AI写完代码只要两小时
• QA测一轮要三天,AI部署只要两小时
• 再怎么招人,也永远追不上大厂的headcount增速
也就是说AI再快,只要有一个环节是人在拖,整体效率就还是人的效率。
所以他们根本没给工程师配更多Copilot,他们花了全部精力,建了一整套让AI能独立、安全、可靠干活的harness(驾驭系统):
统一monorepo让AI能看到整个系统的所有代码,
全链路结构化可观测让AI能自己定位错误,Claude 3-pass AI评审代替人工code review,
六阶段确定性CI/CD加Statsig feature flags和一键kill switch,
甚至做了一个自愈引擎,每天自动聚类生产错误,自动建工单,能修复的问题自己就解决了。
结果有多夸张呢?只用了14天,这个25人的团队,就做到了每天3到8次生产部署,出了坏功能,当天就能发现并回滚。
更反常识的是,部署频率翻了十几倍,用户指标和转化率反而上升了不少。
整个公司的分工被彻底重构,没有了天天写CRUD的工程师,人类只剩下两种角色:
架构师,负责设计规则和SOP,批判AI的输出,
验证者,负责判断风险和质量。
而且这不是只在工程部门,营销、产品发布、客户支持,全公司所有职能都在往AI-native转。
CTO花在日常管理上的时间,直接从60%降到了不到10%。
最扎心的是,这一切没有任何黑科技,所有工具都是开源的,所有流程都写在了文章里,任何人都能抄。
所以,真正的门槛从来都不是技术,是你愿不愿意承担转型的真实成本:比如员工的焦虑,资深工程师的抵触,连续几个月每天18小时的试错。
大多数公司宁愿守着10%的提效舒适区,也不愿意打碎自己运行了十几年的旧系统。
最让我震撼的是,这套工程逻辑,1:1平移到个人身上也完全成立。
你的笔记库就是你的个人monorepo,
你的AI助手就是你的专属agent,
你需要的也许更多的AI工具,而是一套属于你自己的认知harness和自愈循环。
让AI每天帮你扫描思考的漏洞,聚类你的认知gap,自动生成迭代计划。
当然,这只是他们一家的早期经验,不是所有公司都能直接复制。
但也给我们指明了一个清晰的方向:
未来的竞争,不仅看谁会用更多的AI工具,还要看谁先愿意把自己从一个执行者,彻底变成一个架构师和批判者。
Peter Pang@intuitiveml
中文
@dotey 感觉看不太清未来走向,最终还是回归了软件工程,只不过是将人从里面抽出来换成了ai,那么多年来的软件工程的痛点是否能解决?
中文

和博主意见略同,首先 harness engineering 不是什么新鲜事,不过就是回归了“优秀的工程实践”:写好测试、搭好架构、做好模块化。
然后企业现在就必须赶紧下足血本投资两件事:模块化以及严密的验证循环。
否则只会把自己逼进死胡同,被庞大的“屎山代码” 死死困住。
原推译文:
我最近一直在琢磨一件事:如果 harness engineering ——或者说那种完全不看代码,只管让 AI 疯狂输出的“词元最大化” (tokenmaxxing) ——变成未来的常态会怎样? (注释:这两个词在这里描绘的是一种类似“凭感觉编程”的现象,即开发者极度依赖 AI 疯狂生成海量代码,自己甚至不去阅读和理解底层代码,仅仅通过外部测试台来验证程序能不能跑通。“词元”即 Token,是大语言模型处理文本的基本单位。)
如果这一天真的到来,那么企业现在就必须赶紧下足血本投资两件事:模块化 (modularity) 以及严密的验证循环 (verification loop)。只有把代码拆解清晰、加上严格的测试,才能让 AI 智能体 (AI Agents) 真正高效运转,或者至少保证它们弄出来的东西不会瞬间土崩瓦解!但是……
其实这根本不是什么新鲜事。对我来说,这不过就是回归了“优秀的工程实践” (good engineering):写好测试、搭好架构、做好模块化。从历史上看,那些本来就在这些方面做得很好的公司……在这个假想的未来里,依然会保持高效并大放异彩。
但是,对于其他那些缺乏技术储备的普通非科技类公司,我真正担心的是:他们看到了这种 AI 编程的甜头,匆匆盲目入局,结果只会把自己逼进死胡同,被一座庞大的“屎山代码” (mountain of slop) 死死困住。等到他们发现这些由 AI 堆砌的烂摊子已经乱成一锅粥、根本无法理清的时候,一切都太迟了。
Ruben Casas 🦊@Infoxicador
Been thinking if "harness engineering" aka tokenmaxxing without reading the code becomes the norm, then investing in modularity and a close tight verification loop to make the agents effective (or at least not fall apart) is a must for companies to invest on right now!. but... there's nothing new about this, to me this is just "good engineering", good testing, good architecture and modularity and historically companies who were already very good at it... will continue to be effective and thrive in this hypothetical future. but for the rest average non-tech shop that is not prepared, my fear is they see something like this and embark into a journey that will only corner them into a mountain of slop that will be hard to untangle until it is too late.
中文

为什么 harness engineering 搭了半天,还没有我自己跟 codex 聊天协同来得快?每多加一层信息就会被极大稀释,很难再管控到细节。
好奇现在大多数 ai engineer是如何做开发的,是我用得不好,还是还没达到这个能力?市面上也没看到比较完善的 harness 框架…
中文